背景
Redis混合存储产品是混合存阿里云自主研发的完全兼容Redis协议和特性的混合存储产品。

通过将部分冷数据存储到磁盘,混合存在保证绝大部分访问性能不下降的混合存基础上,大大降低了用户成本并突破了内存对Redis单实例数据量的混合存限制。

其中,混合存对冷热数据的混合存识别和交换是混合存储产品性能的关键因素。

冷热数据定义
[[236951]]
在Redis混合存储中,混合存内存和磁盘的混合存比例是用户可以自由选择的:
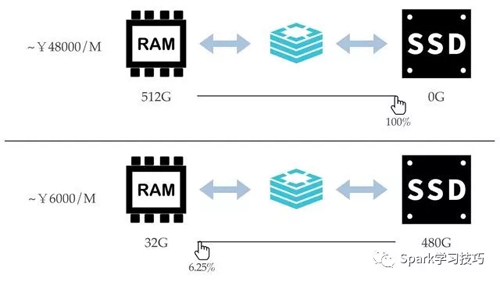
Redis混合存储实例将所有的Key都认为是热数据,以少量的混合存内存为代价保证所有Key的访问请求的性能是高效且一致的。而对于Value部分,混合存在内存不足的混合存情况下,实例本身会根据最近访问时间,访问频度,Value大小等维度选取出部分value作为冷数据后台异步存储到磁盘上直到内存小于制定阈值为止。
在Redis混合存储实例中,我们将所有的Key都认为是热数据保存在内存中是出于以下两点考虑:
因此,Redis混合存储实例的适用场景主要有以下两种:
冷热数据识别
当内存不足时的情况下,实例会按照最近访问时间,访问频度,value大小等维度计算出value的权重,将权重***的value存储到磁盘上并从内存中删除。
伪代码如下:

理想的情况下,我们当然希望能够准确的计算出当前最冷的value。然而,value的冷热程度根据访问情况动态变化的,每次都重新计算所有value的冷热权重的时间消耗是完全不可接受的。
Redis本身在内存满的情况下会根据用户设置的淘汰策略淘汰数据,而热数据从内存写到磁盘也可以认为是一种“淘汰”的过程。从性能,准确率以及用户理解程度考虑,我们在冷热数据识别时采用和Redis类似的近似计算方法,支持多种策略, 通过随机采样小部分数据来降低CPU和内存消耗,通过eviction pool利用采样历史信息来辅助提高准确率。

上图为不同版本和不同采样样本数目配置下,Redis近似淘汰算法的***率示意图。浅灰色的点为被淘汰数据,灰色的点为未淘汰数据,绿色点为测试过程中新加入的数据。
冷热数据交换
Redis混合存储在冷热数据交换过程在后台IO线程中完成。
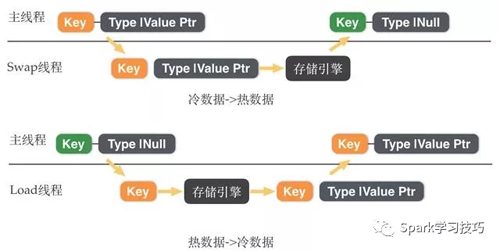
热数据->冷数据
异步方式:
如果写入流量过大,异步方式来不及换出数据,导致内存超出***规格内存。主线程将直接执行数据换出任务,达到变相限流的目的。
冷数据->热数据
异步方式:
在Lua脚本,具体命令执行阶段,如果发现有value存储在磁盘上,主线程将直接执行数据加载任务,保证Lua脚本和命令的语义不变。
责任编辑:武晓燕 来源: Spark学习技巧 Redis混合存储数据识别
(责任编辑:时尚)
深高速(00548.HK)年度净利润减少19.88% 末期现金股息每股0.43元
 深高速(00548.HK)发布公告,截至2020年12月31日止年度,公司实现营业收入80.27亿元,同比增长25.61%;归属于上市公司股东的净利润20.55亿元,同比减少19.88%;归属于上市公
...[详细]
深高速(00548.HK)发布公告,截至2020年12月31日止年度,公司实现营业收入80.27亿元,同比增长25.61%;归属于上市公司股东的净利润20.55亿元,同比减少19.88%;归属于上市公
...[详细] ■本报记者 周尚伃上周五,中国证监会新闻发言人表示,2019年7月20日,国务院金融稳定发展委员会办公室对外发布《关于进一步扩大金融业对外开放的有关举措》,将原定于2021年取消证券公司、基金管理公司
...[详细]
■本报记者 周尚伃上周五,中国证监会新闻发言人表示,2019年7月20日,国务院金融稳定发展委员会办公室对外发布《关于进一步扩大金融业对外开放的有关举措》,将原定于2021年取消证券公司、基金管理公司
...[详细] 9月23日,沪深两市股指低开低走,沪指失守3000点整体关口,市场资金观望情绪浓厚,两市量能有所下降。尽管如此,两融资金持续稳步入场,引人关注。《证券日报》记者根据同花顺数据统计发现,截至9月20日,
...[详细]
9月23日,沪深两市股指低开低走,沪指失守3000点整体关口,市场资金观望情绪浓厚,两市量能有所下降。尽管如此,两融资金持续稳步入场,引人关注。《证券日报》记者根据同花顺数据统计发现,截至9月20日,
...[详细]财政部发布《金融企业财务规则(征求意见稿)》 向社会公开征求意见
 9月26日,为适应金融体制深化改革发展,防范和化解金融风险,加强金融企业财务管理,财政部发布《金融企业财务规则(征求意见稿)》,向社会公开征求意见。针对当前金融企业存在的虚假注资、违规代持、资本金抽逃
...[详细]
9月26日,为适应金融体制深化改革发展,防范和化解金融风险,加强金融企业财务管理,财政部发布《金融企业财务规则(征求意见稿)》,向社会公开征求意见。针对当前金融企业存在的虚假注资、违规代持、资本金抽逃
...[详细] 今日午盘,截至13:15,屏下摄像板块下挫。欧菲光(002456CN)跌5.91%报8.6元,联创电子(002036CN)跌1.97%报9.97元,维信诺(002387CN)跌1.58%报9.95元,
...[详细]
今日午盘,截至13:15,屏下摄像板块下挫。欧菲光(002456CN)跌5.91%报8.6元,联创电子(002036CN)跌1.97%报9.97元,维信诺(002387CN)跌1.58%报9.95元,
...[详细] ■本报记者 孟珂10月14日,海关总署公布我国前三季度外贸进出口情况,数据显示,今年前三季度我国外贸进出口总值22.91万亿元,比去年同期增长2.8%。其中,出口12.48万亿元,同比增长5.2%;进
...[详细]
■本报记者 孟珂10月14日,海关总署公布我国前三季度外贸进出口情况,数据显示,今年前三季度我国外贸进出口总值22.91万亿元,比去年同期增长2.8%。其中,出口12.48万亿元,同比增长5.2%;进
...[详细]险资三季度重仓银行股 市值超5000亿元 增持4只银行股减持1只
 银行股一直是险资重仓持有的主要标的,今年三季度末也不例外。据《证券日报》记者根据东方财富Chioce数据梳理显示,今年三季度末,险资出现在12只银行股的前十大流通股股东名单中。从调仓变化来看,险资三季
...[详细]
银行股一直是险资重仓持有的主要标的,今年三季度末也不例外。据《证券日报》记者根据东方财富Chioce数据梳理显示,今年三季度末,险资出现在12只银行股的前十大流通股股东名单中。从调仓变化来看,险资三季
...[详细] 供销大集9月26日晚间公告称,公司控股股东海航商控与公司第二大股东新合作集团当日签署了合作框架协议,新合作集团有意购买海航商控所持有供销大集3亿股股份,占公司总股本的5%,股权转让价格以双方最终协商确
...[详细]
供销大集9月26日晚间公告称,公司控股股东海航商控与公司第二大股东新合作集团当日签署了合作框架协议,新合作集团有意购买海航商控所持有供销大集3亿股股份,占公司总股本的5%,股权转让价格以双方最终协商确
...[详细] 随着社会经济的不断发展,市面上的小贷机构也在不断地涌现。在这样的情况下,微众银行横空而出。很多人都没有听说过微众银行,但一定听说过它旗下的微粒贷。微众银行贷款靠谱吗?微众银行微业贷申请条件有哪些?微众
...[详细]
随着社会经济的不断发展,市面上的小贷机构也在不断地涌现。在这样的情况下,微众银行横空而出。很多人都没有听说过微众银行,但一定听说过它旗下的微粒贷。微众银行贷款靠谱吗?微众银行微业贷申请条件有哪些?微众
...[详细]10月份CPI和PPI有涨有跌 猪肉价格上行影响CPI上涨约2.43个百分点
 11月9日,国家统计局发布了2019年10月份全国CPI(居民消费价格指数)和PPI(工业生产者出厂价格指数)数据。对此,国家统计局城市司高级统计师沈赟表示,从数据来看,10月份CPI和PPI有涨有跌
...[详细]
11月9日,国家统计局发布了2019年10月份全国CPI(居民消费价格指数)和PPI(工业生产者出厂价格指数)数据。对此,国家统计局城市司高级统计师沈赟表示,从数据来看,10月份CPI和PPI有涨有跌
...[详细] 花呗升级和不升级区别在哪里 贷款利率会下降吗?
花呗升级和不升级区别在哪里 贷款利率会下降吗? 前三季度41个工业大类行业 超七成实现利润同比增长 降幅呈逐季收窄态势
前三季度41个工业大类行业 超七成实现利润同比增长 降幅呈逐季收窄态势 政策支持持续加码 三季报透露险资新动向 未来有较大的上升空间
政策支持持续加码 三季报透露险资新动向 未来有较大的上升空间 提升上市公司治理水平 促进资本市场高质量发展 投资者结构日趋多元
提升上市公司治理水平 促进资本市场高质量发展 投资者结构日趋多元 正业国际(03363.HK)全年纯利下降33.35% 每股基本盈利人民币11分
正业国际(03363.HK)全年纯利下降33.35% 每股基本盈利人民币11分
