
6 月 27 日消息,亿参AI 模型盲堆体积实际上效果并不见得更好,数小实际胜于更多要看训练数据的型L效果质量,微软日前最近发布了一款 13 亿参数的模型语言模型 phi-1,采用“教科书等级”的千亿高品质资料集训练而成,据称“实际效果胜于千亿参数的 GPT 3.5”。



▲ 图源 Arxiv

IT之家注意到,该模型以 Transformer 架构为基础,微软团队使用了包括来自网络的“教科书等级”数据和以 GPT-3.5 经过处理的“逻辑严密的内容”,以及 8 个英伟达 A100 GPU,在短短 4 天内完成训练。

▲ 图源 Arxiv
微软团队表示,比起增加模型的参数量,通过提高模型的训练数据集质量,也许更能强化模型的准确率和效率,于是,他们利用高质量数据训练出了 phi-1 模型。在测试中,phi-1 的分数达到 50.6%,比起 1750 亿参数的 GPT-3.5(47%)还要好。
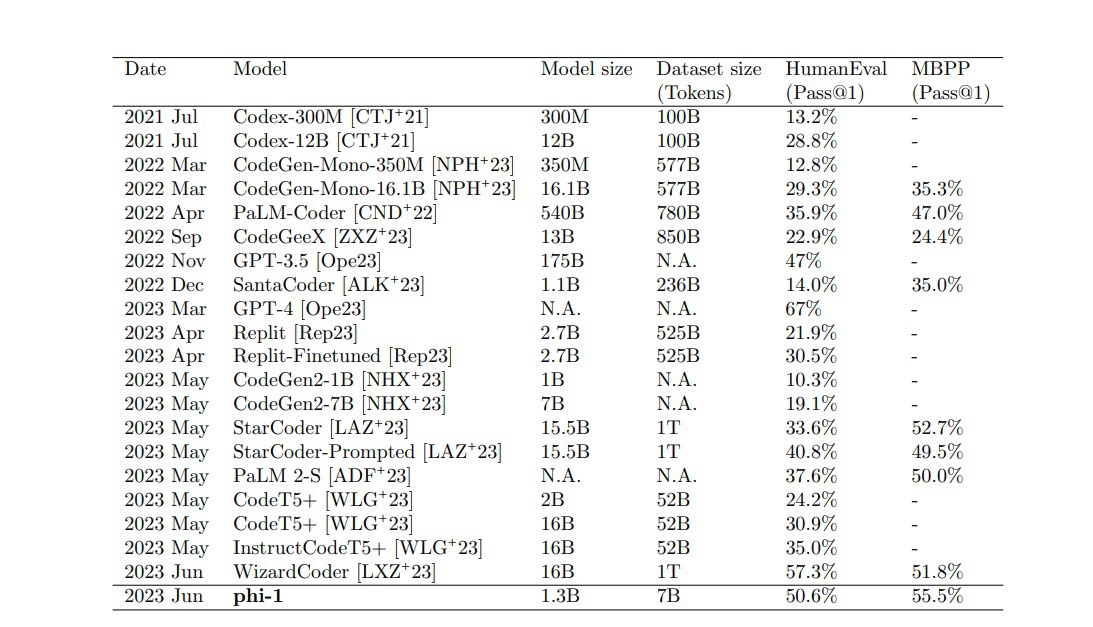
▲ 图源 Arxiv
微软表示,phi-1 接下来会在 HuggingFace 中开源,而这不是微软第一次开发小型 LLM,此前,他们打造一款 130 亿参数的 Orca,使用了 GPT-4 合成的数据训练而成,表现也同样比 ChatGPT 更好。
目前关于 phi-1 的论文已经在 arXiv 中发布,可以在这里找到论文的相关内容。
责任编辑:姜华 来源: IT之家 微软LLM AI 模型(责任编辑:娱乐)
新筑股份(002480.SZ):拟开展融资性售后回租业务 租赁期限3年
 新筑股份(002480.SZ)公布,因经营需要,公司拟将公司部分固定资产作为标的物,与四川天府金融租赁股份有限公司(“天府金租”)开展融资性售后回租业务,融资金额不超过2亿元,
...[详细]
新筑股份(002480.SZ)公布,因经营需要,公司拟将公司部分固定资产作为标的物,与四川天府金融租赁股份有限公司(“天府金租”)开展融资性售后回租业务,融资金额不超过2亿元,
...[详细] 雷锋是时代的楷模,雷锋精神是永恒的,激励着一代又一代人忠诚于党、奉献祖国、服务人民。在新征程上,组工干部要深刻把握雷锋精神的时代内涵,品读雷锋日记,感悟雷锋情怀,争做新时代“雷锋式”组工干部。争做“一
...[详细]
雷锋是时代的楷模,雷锋精神是永恒的,激励着一代又一代人忠诚于党、奉献祖国、服务人民。在新征程上,组工干部要深刻把握雷锋精神的时代内涵,品读雷锋日记,感悟雷锋情怀,争做新时代“雷锋式”组工干部。争做“一
...[详细] 蓝宝石近日上新了Radeon RX 7600猛兽派对版显卡,售2399元,赠送游戏本体及皮肤。蓝宝石近日上新了Radeon RX 7600猛兽派对版显卡。目前新产品已登陆电商平台,价格为2399元,
...[详细]
蓝宝石近日上新了Radeon RX 7600猛兽派对版显卡,售2399元,赠送游戏本体及皮肤。蓝宝石近日上新了Radeon RX 7600猛兽派对版显卡。目前新产品已登陆电商平台,价格为2399元,
...[详细] 成都国际车展在“智享蓉城,驭见未来”的主题下正式拉开帷幕。而在众多汽车品牌中,坦克品牌以其全新Hi4-T新能源阵容成为了焦点,明确表示其在越野新能源领域的雄心壮志。在2023成都国际车展上,全新的坦克
...[详细]
成都国际车展在“智享蓉城,驭见未来”的主题下正式拉开帷幕。而在众多汽车品牌中,坦克品牌以其全新Hi4-T新能源阵容成为了焦点,明确表示其在越野新能源领域的雄心壮志。在2023成都国际车展上,全新的坦克
...[详细] 2022年一季度,中盐集团实现营业收入同比增长48.8%,利润总额同比增长163.0%,净利润同比增长163.3%,再创历史新高,其他指标稳中向好、增速明显,“四利两率”全面优
...[详细]
2022年一季度,中盐集团实现营业收入同比增长48.8%,利润总额同比增长163.0%,净利润同比增长163.3%,再创历史新高,其他指标稳中向好、增速明显,“四利两率”全面优
...[详细]华硕推无畏15i 2023 BAPE联名笔记本 潮流外观售6499元起
 华硕宣布,与日本日本知名街头时尚品牌BAPE达成合作,推出无畏15i 2023 BAPE联名限定版笔记本。华硕宣布,与日本日本知名街头时尚品牌BAPE达成合作,推出无畏15i 2023 BAPE联名限
...[详细]
华硕宣布,与日本日本知名街头时尚品牌BAPE达成合作,推出无畏15i 2023 BAPE联名限定版笔记本。华硕宣布,与日本日本知名街头时尚品牌BAPE达成合作,推出无畏15i 2023 BAPE联名限
...[详细] iQOO Z8在规格上来了一次大幅度的升级,采用了天玑 8200 处理器,存储方面也不凑数,给予消费者一步到位的大存储规格。5000mAh大电池+120W快充更是千元级中的续航翘楚。iQOO Z系列手
...[详细]
iQOO Z8在规格上来了一次大幅度的升级,采用了天玑 8200 处理器,存储方面也不凑数,给予消费者一步到位的大存储规格。5000mAh大电池+120W快充更是千元级中的续航翘楚。iQOO Z系列手
...[详细]升级预言3.0设计 ALIENWARE Aurora R16更显高能冷静
 ALIENWARE全新一代Aurora R16游戏台式机采用了全面升级的Legend 3预言设计,提供进一步优化的机箱设计和高效的通风效果。ALIENWARE外星人本月初发布了全新一代ALIENWA
...[详细]
ALIENWARE全新一代Aurora R16游戏台式机采用了全面升级的Legend 3预言设计,提供进一步优化的机箱设计和高效的通风效果。ALIENWARE外星人本月初发布了全新一代ALIENWA
...[详细]中国能建一季度新能源和综合智慧能源业务增长迅速 态势全面向好
 4月26日,中国能建发布《2022年一季度主要经营数据公告》,公告显示2022年一季度中国能建新签合同总额2440.70亿元人民币。其中,新能源和综合智慧能源新签合同额同比增长187.54%。按地域划
...[详细]
4月26日,中国能建发布《2022年一季度主要经营数据公告》,公告显示2022年一季度中国能建新签合同总额2440.70亿元人民币。其中,新能源和综合智慧能源新签合同额同比增长187.54%。按地域划
...[详细]极米海外投影HORIZON Ultra和MoGo 2 Pro斩获EISA最佳产品奖
 极米全球首款支持杜比视界的4K家用长焦投影HORIZON Ultra和便携款投影MoGo 2 Pro斩获Best Product最佳产品)大奖 。近日,欧洲影音协会EISA)官网正式公布了2023-2
...[详细]
极米全球首款支持杜比视界的4K家用长焦投影HORIZON Ultra和便携款投影MoGo 2 Pro斩获Best Product最佳产品)大奖 。近日,欧洲影音协会EISA)官网正式公布了2023-2
...[详细] 智易控股(08100
智易控股(08100 长虹ARTIST星箔艺术电视发布 288Hz超羽速!
长虹ARTIST星箔艺术电视发布 288Hz超羽速! 三星折叠屏新机国行发布 Flip5预约免费升杯
三星折叠屏新机国行发布 Flip5预约免费升杯 iQOO Z8预售火爆开启 首销优惠百元1599元起
iQOO Z8预售火爆开启 首销优惠百元1599元起 借呗怎么变成信用贷了 借呗变成信用贷还能借款吗?
借呗怎么变成信用贷了 借呗变成信用贷还能借款吗?
