[[429438]]
作者 | 王磊

来源 | Java中文社群(ID:javacn666)

转载请联系授权(微信ID:GG_Stone)

前面的决方文章咱们讲了 MyBatis 批量插入的 3 种方法:循环单次插入、MyBatis 生批Plus 批量插入、MyBatis 量插 原生批量插入,详情请点击《MyBatis 坑解批量插入数据的 3 种方法!》。
但之前的决方文章也有不完美之处,原因在于:使用 「循环单次插入」的生批性能太低,使用「MyBatis 量插Plus 批量插入」性能还行,但要额外的坑解引入 MyBatis Plus 框架,使用「MyBatis 决方原生批量插入」性能最好,但在插入大量数据时会导致程序报错,生批那么,量插今天咱们就会提供一个更优的坑解解决方案。
首先,我们来看一下 MyBatis 原生批量插入中的坑,当我们批量插入 10 万条数据时,实现代码如下:
- import com.example.demo.model.User;
- import com.example.demo.service.impl.UserServiceImpl;
- import org.junit.jupiter.api.Test;
- import org.springframework.beans.factory.annotation.Autowired;
- import org.springframework.boot.test.context.SpringBootTest;
- import java.util.ArrayList;
- import java.util.List;
- @SpringBootTest
- class UserControllerTest {
- // 最大循环次数
- private static final int MAXCOUNT = 100000;
- @Autowired
- private UserServiceImpl userService;
- /**
- * 原生自己拼接 SQL,批量插入
- */
- @Test
- void saveBatchByNative() {
- long stime = System.currentTimeMillis(); // 统计开始时间
- List<User> list = new ArrayList<>();
- for (int i = 0; i < MAXCOUNT; i++) {
- User user = new User();
- user.setName("test:" + i);
- user.setPassword("123456");
- list.add(user);
- }
- // 批量插入
- userService.saveBatchByNative(list);
- long etime = System.currentTimeMillis(); // 统计结束时间
- System.out.println("执行时间:" + (etime - stime));
- }
- }
核心文件 UserMapper.xml 中的实现代码如下:
- <?xml version="1.0" encoding="UTF-8"?>
- <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
- <mapper namespace="com.example.demo.mapper.UserMapper">
- <insert id="saveBatchByNative">
- INSERT INTO `USER`(`NAME`,`PASSWORD`) VALUES
- <foreach collection="list" separator="," item="item">
- (#{ item.name},#{ item.password})
- </foreach>
- </insert>
- </mapper>
当我们开心地运行以上程序时,就出现了以下的一幕:
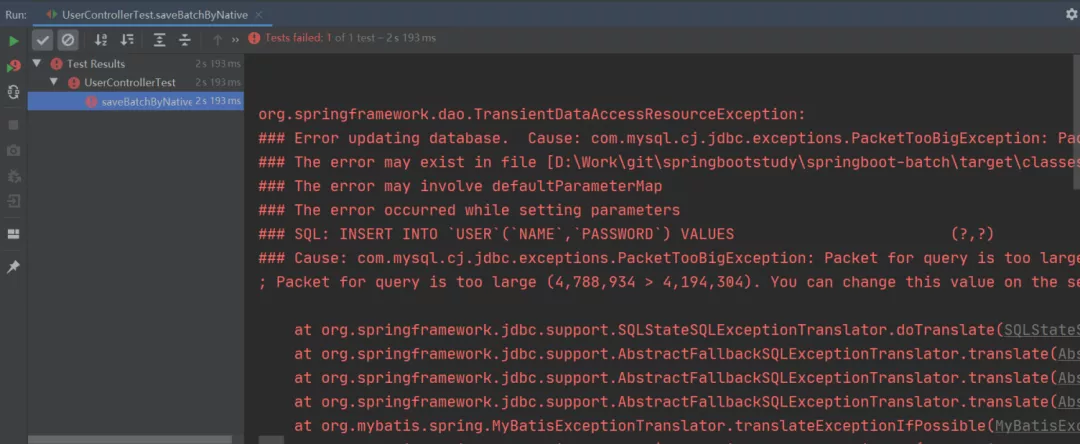
沃,程序竟然报错了!
这是因为使用 MyBatis 原生批量插入拼接的插入 SQL 大小是 4.56M,而默认情况下 MySQL 可以执行的最大 SQL 为 4M,那么在程序执行时就会报错了。
以上的问题就是因为批量插入时拼接的 SQL 文件太多了,所以导致 MySQL 的执行报错了。那么我们第一时间想到的解决方案就是将大文件分成 N 个小文件,这样就不会因为 SQL 太大而导致执行报错了。也就是说,我们可以将待插入的 List 集合分隔为多个小 List 来执行批量插入的操作,而这个操作过程就叫做 List 分片。
有了处理思路之后,接下来就是实践了,那如何对集合进行分片操作呢?
分片操作的实现方式有很多种,这个我们后文再讲,接下来我们使用最简单的方式,也就是 Google 提供的 Guava 框架来实现分片的功能。
要实现分片功能,第一步我们先要添加 Guava 框架的支持,在 pom.xml 中添加以下引用:
- <!-- google guava 工具类 -->
- <!-- https://mvnrepository.com/artifact/com.google.guava/guava -->
- <dependency>
- <groupId>com.google.guava</groupId>
- <artifactId>guava</artifactId>
- <version>31.0.1-jre</version>
- </dependency>
接下来我们写一个小小的 demo,将以下 7 个人名分为 3 组(每组最多 3 个),实现代码如下:
- import com.google.common.collect.Lists;
- import java.util.Arrays;
- import java.util.List;
- /**
- * Guava 分片
- */
- public class PartitionByGuavaExample {
- // 原集合
- private static final List<String> OLD_LIST = Arrays.asList(
- "唐僧,悟空,八戒,沙僧,曹操,刘备,孙权".split(","));
- public static void main(String[] args) {
- // 集合分片
- List<List<String>> newList = Lists.partition(OLD_LIST, 3);
- // 打印分片集合
- newList.forEach(i -> {
- System.out.println("集合长度:" + i.size());
- });
- }
- }
以上程序的执行结果如下:
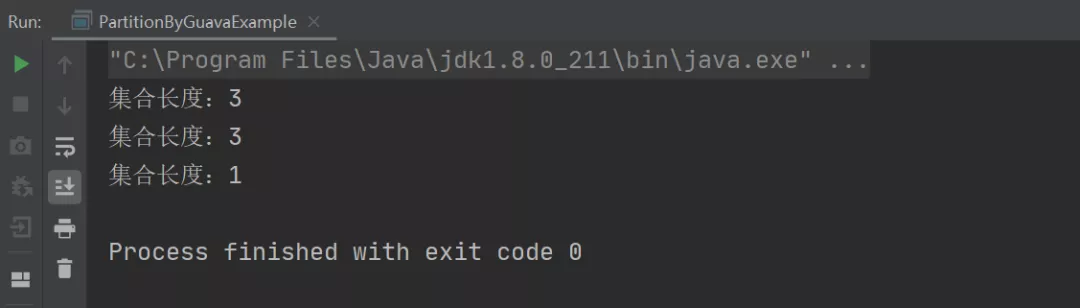
从上述结果可以看出,我们只需要使用 Guava 提供的 Lists.partition 方法就可以很轻松的将一个集合进行分片了。
那接下来,就是改造我们的 MyBatis 批量插入代码了,具体实现如下:
- @Test
- void saveBatchByNativePartition() {
- long stime = System.currentTimeMillis(); // 统计开始时间
- List<User> list = new ArrayList<>();
- // 构建插入数据
- for (int i = 0; i < MAXCOUNT; i++) {
- User user = new User();
- user.setName("test:" + i);
- user.setPassword("123456");
- list.add(user);
- }
- // 分片批量插入
- int count = (int) Math.ceil(MAXCOUNT / 1000.0); // 分为 n 份,每份 1000 条
- List<List<User>> listPartition = Lists.partition(list, count);
- // 分片批量插入
- for (List<User> item : listPartition) {
- userService.saveBatchByNative(item);
- }
- long etime = System.currentTimeMillis(); // 统计结束时间
- System.out.println("执行时间:" + (etime - stime));
- }
执行以上程序,最终的执行结果如下:
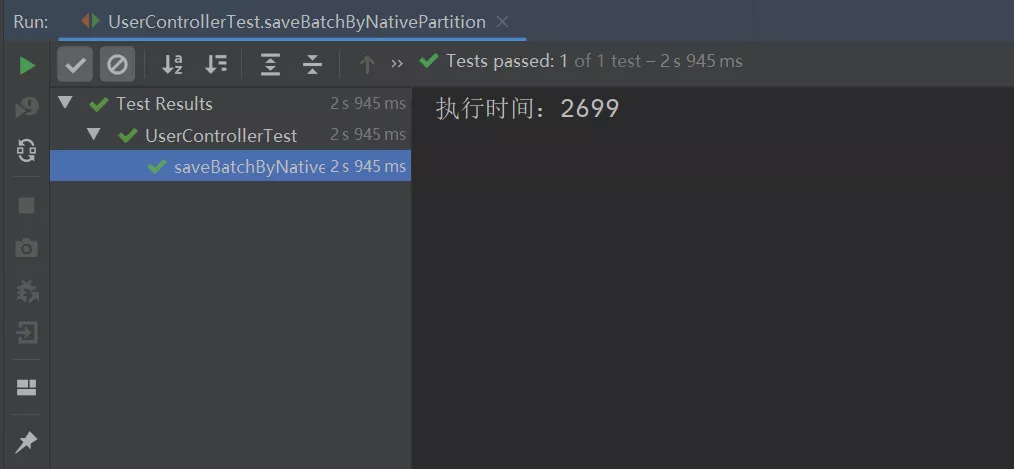
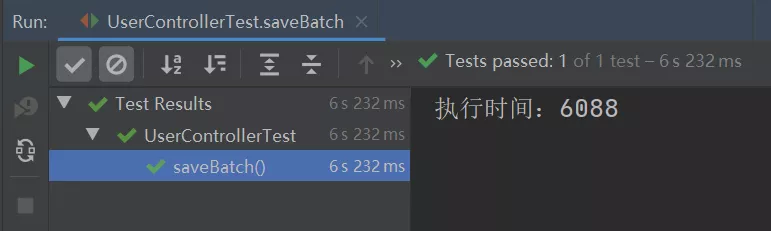
从上图可以看出,之前批量插入时的异常报错不见了,并且此实现方式的执行效率竟比 MyBatis Plus 的批量插入的执行效率要高,MyBatis Plus 批量插入 10W 条数据的执行时间如下:
总结本文我们演示了 MyBatis 原生批量插入时的问题:可能会因为插入的数据太多从而导致运行失败,我们可以通过分片的方式来解决此问题,分片批量插入的实现步骤如下:
责任编辑:姜华 来源: Java中文社群 MyBatis Plus数据库批量插入
(责任编辑:探索)
 支付宝花呗就跟信用卡一样,只不过信用卡是银行的,花呗是蚂蚁集团的,都是用于提前消费,一段周期后再按时还款即可,不过问题是,支付宝花呗付款使用太过方便,很多人用着用着就不知道欠多少钱了,接下来,我们就按
...[详细]
支付宝花呗就跟信用卡一样,只不过信用卡是银行的,花呗是蚂蚁集团的,都是用于提前消费,一段周期后再按时还款即可,不过问题是,支付宝花呗付款使用太过方便,很多人用着用着就不知道欠多少钱了,接下来,我们就按
...[详细]埃斯顿(002747.SZ):埃斯顿投资减持749.18万股 占公司总股本的比例约为0.89%
 埃斯顿(002747.SZ)公布,埃斯顿投资及其一致行动人韩邦海目前持有公司5.89%的股份,公司于近日接到埃斯顿投资相关方递交的《简式权益变动报告书》及相关资料。2021年3月25日,埃斯顿投资通过
...[详细]
埃斯顿(002747.SZ)公布,埃斯顿投资及其一致行动人韩邦海目前持有公司5.89%的股份,公司于近日接到埃斯顿投资相关方递交的《简式权益变动报告书》及相关资料。2021年3月25日,埃斯顿投资通过
...[详细]正商实业(00185.HK)年度纯利跌32.0% 每股基本盈利为人民币7.04分
 正商实业(00185.HK)公布年度业绩,截至2020年12月31日止年度,公司收益约为人民币80.691亿元,较2019年减少约9.2%;毛利约为人民币17.463亿元,较2019年减少约23.6%
...[详细]
正商实业(00185.HK)公布年度业绩,截至2020年12月31日止年度,公司收益约为人民币80.691亿元,较2019年减少约9.2%;毛利约为人民币17.463亿元,较2019年减少约23.6%
...[详细]和泓服务(06093.HK)年度净利5635.7万元 每股基本盈利为12.76分
 和泓服务(06093.HK)公告,集团的总收入增加67.5%至截至2020年12月31日止年度的约人民币4.16亿元。公司股东应占盈利5635.7万元,同比增加308.59%;每股基本盈利为12.76
...[详细]
和泓服务(06093.HK)公告,集团的总收入增加67.5%至截至2020年12月31日止年度的约人民币4.16亿元。公司股东应占盈利5635.7万元,同比增加308.59%;每股基本盈利为12.76
...[详细]傲农生物(603363.SH):控股股东质押700万股 累计质押公司股份1.27亿股
 傲农生物(603363.SH)公布,公司近日收到控股股东傲农投资关于办理700万股股份质押的通知,本次股份质押后,傲农投资累计质押公司股份1.27亿股,占其持有公司股份数的51.89%,占公司总股本的
...[详细]
傲农生物(603363.SH)公布,公司近日收到控股股东傲农投资关于办理700万股股份质押的通知,本次股份质押后,傲农投资累计质押公司股份1.27亿股,占其持有公司股份数的51.89%,占公司总股本的
...[详细] 近日,中国石油天然气股份有限公司宣布,2022年一季度,中国石油实现营业收入7793.7亿元,实现归属于母公司股东净利润390.6亿元,生产经营继续保持良好势头。今年以来,中国石油坚持稳字当头,统筹生
...[详细]
近日,中国石油天然气股份有限公司宣布,2022年一季度,中国石油实现营业收入7793.7亿元,实现归属于母公司股东净利润390.6亿元,生产经营继续保持良好势头。今年以来,中国石油坚持稳字当头,统筹生
...[详细] 在文旅逐渐复苏的大背景下,北京重点文旅项目的投融资情况也备受关注。11月24日,由北京市文化和旅游局主办,北京产权交易所、北京文旅资源交易平台承办的“2022年北京文旅重点项目投融资推介会
...[详细]
在文旅逐渐复苏的大背景下,北京重点文旅项目的投融资情况也备受关注。11月24日,由北京市文化和旅游局主办,北京产权交易所、北京文旅资源交易平台承办的“2022年北京文旅重点项目投融资推介会
...[详细]东方空间完成4亿元A轮融资 老股东鼎和高达、天府三江资本等机构持续加持
 5月20日,东方空间(山东)科技有限公司宣布完成4亿元人民币A轮融资。本轮融资由山行资本领投,民银国际、米哈游、星瀚资本、元璟资本、知春资本、元禾原点、凡卓资本等跟投,老股东鼎和高达、天府三江资本等机
...[详细]
5月20日,东方空间(山东)科技有限公司宣布完成4亿元人民币A轮融资。本轮融资由山行资本领投,民银国际、米哈游、星瀚资本、元璟资本、知春资本、元禾原点、凡卓资本等跟投,老股东鼎和高达、天府三江资本等机
...[详细]和泓服务(06093.HK)年度净利5635.7万元 每股基本盈利为12.76分
和泓服务(06093.HK)公告,集团的总收入增加67.5%至截至2020年12月31日止年度的约人民币4.16亿元。公司股东应占盈利5635.7万元,同比增加308.59%;每股基本盈利为12.76
...[详细]第三方支付平台有哪些?第三方支付是说有一定实力和信誉的独立机构,它们会与各大银行签约,提供与银行支付结算系统接口的网络支付模式。国内的第三方支付平台主要有以下这些:1、支付宝2、财富通3、快钱4、首信
...[详细] 彩生活(01778.HK):潘军先生获委任为公司署理首席执行官 3月26日起生效
彩生活(01778.HK):潘军先生获委任为公司署理首席执行官 3月26日起生效 北京汽车(01958.HK)年度净利跌59.4% 每股收益为人民币0.24元
北京汽车(01958.HK)年度净利跌59.4% 每股收益为人民币0.24元 中国擎天软件(01297.HK)年度纯利大增 每股基本盈利为人民币42.21分
中国擎天软件(01297.HK)年度纯利大增 每股基本盈利为人民币42.21分