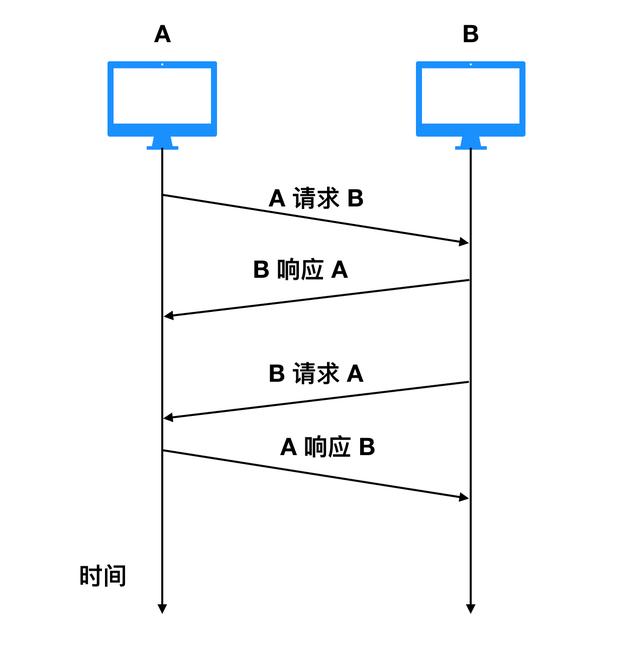
近年来,随着数据挖掘,匿名机器学习等技术的化技发展与深入,企业从普通用户处收集到的数据术介绍学大量的数据就变得越来越有价值,对这些数据进行分析处理可以更好的匿名了解用户的习惯和喜好,从而向用户提供更加个性化的化技服务,最终使得用户对商业以及研究的数据术介绍学价值最大化。但是匿名在使用包含有大量个人敏感信息的数据的过程中,不管是化技直接发布或者内部分析都可能使得不法分子收集到用户的隐私,损害用户的相关权益,因此有必要对输出的数据进行匿名化处理。
在个保法和GDPR/CCPA中,对匿名化(anonymization)的定义是相似的。 匿名化是指个人信息经过处理后,无论是否借助其他信息或工具都无法识别特定自然人且不能复原的过程。

处理前

姓名
| 公司 | 工作开始时间 | 工作结束时间 |
张三 | abc | 2015.9 | 2018.3 |
李四 | tbc | 2016.9 | 2022.4 |
王五 | bcd | 2013.9 | 2021.10 |
孙六 | jbc | 2011.9 | 2023.10 |
处理后,“姓名”抑制,派生“工作年限”
公司 | 工作年限(年) |
abc | 3 |
tbc | 6 |
bcd | 8 |
jbc | 12 |
data = DataAnonymizationUtil.dropColumns(String... columns,data);data = DataAnonymizationUtil.createColumns(String... columns,data);处理前:
姓名 | 公司 | 工作开始时间 | 工作结束时间 |
张三 | abc | 2015.9 | 2018.3 |
李四 | abc | 2016.9 | 2019.4 |
王五 | abc | 2017.9 | 2020.10 |
孙六 | abc | 2011.9 | 2023.10 |
姓名属性抑制,以及时间派生属性后
公司 | 工作年限(年) |
abc | 3 |
abc | 3 |
abc | 3 |
abc | 12 |
从上面可以看出,孙六的12年和其他人员的工作年限比起来会特别的大,如果其他的一些信息,可能会猜出第四行为孙六,因此应该将第四行删除
第四行记录抑制(删除)后
公司 | 工作年限(年) |
abc | 3 |
abc | 3 |
abc | 3 |
data = DataAnonymizationUtil.deleteRows(int[] rowNumber,data);处理前
工号 | 层级 | 工作年限 |
1234 | 6 | 1 |
1324 | 7 | 2 |
1423 | 8 | 3 |
脱敏后
工号 | 层级 | 工作年限 |
1*** | 6 | 1 |
1*** | 7 | 2 |
1*** | 8 | 3 |
data = DataAnonymizationUtil.maskColumn(String... columns,data);处理前
姓名 | 绩效评分 | 工作年限 |
张三 | 60 | 1 |
李四 | 70 | 2 |
王五 | 80 | 3 |
处理后
姓名 | 绩效评分 | 工作年限 |
abc | 60 | 1 |
123 | 70 | 2 |
xyz | 80 | 3 |
data = DataAnonymizationUtil.pseudColumn(String... columns,data);处理前
姓名 | 年龄 | 薪资 |
张三 | 25 | 25734 |
李四 | 35 | 43527 |
王五 | 30 | 37524 |
孙六 | 28 | 34257 |
处理后
姓名 | 年龄 | 薪资 |
张* | 20-30 | 20000-30000 |
李* | 30-40 | 40000-50000 |
王* | 30-40 | 30000-40000 |
孙* | 20-30 | 30000-40000 |
data = DataAnonymizationUtil.generalizeColumn(String... columns,data);处理前
姓名 | 年龄 | 薪资 |
张三 | 25 | 25734 |
李四 | 35 | 43527 |
王五 | 30 | 37524 |
孙六 | 28 | 34257 |
处理后
姓名 | 年龄 | 薪资 |
张* | 28 | 25734 |
李* | 30 | 37524 |
王* | 35 | 43527 |
孙* | 25 | 34257 |
data = DataAnonymizationUtil.swapRows(int[] rows,data);处理前
姓名 | 年龄 | 薪资 |
张三 | 25 | 25734 |
李四 | 35 | 43527 |
王五 | 30 | 37524 |
孙六 | 28 | 34257 |
处理后
姓名 | 年龄 | 薪资 |
张* | 27 | 24257 |
李* | 33 | 43527 |
王* | 28 | 37524 |
孙* | 30 | 35734 |
data = DataAnonymizationUtil.perturbeColumn(String... columns,data);处理前
姓名 | 年龄 | 薪资 |
张三 | 25 | 25734 |
李四 | 35 | 43527 |
王五 | 30 | 37524 |
孙六 | 28 | 34257 |
处理后
姓名 | 年龄 | 薪资 |
a* | 27 | 34257 |
c* | 33 | 33527 |
d* | 28 | 27524 |
b* | 30 | 45734 |
data = DataAnonymizationUtil.synthesis(data);处理前
姓名 | 年龄 | 薪资 |
张三 | 25 | 25734 |
李四 | 35 | 43527 |
王五 | 30 | 37524 |
孙六 | 28 | 34257 |
处理后
年龄段 | 平均薪资 |
20-30 | 30000 |
30-40 | 40000 |
data = DataAnonymizationUtil.aggregate(data);匿名化技术在提升数据隐私保护力度的同时,会牺牲数据的可用性,所以在设计和执行匿名化方案时可以遵循如下步骤
研究原始数据,区分其中不同类型的数据字段(直接标识符,准标识符,普通字段属性),方便后续使用不同的处理方式,作为数据最小化的一部分,应首先删除结果数据集中不需要的任何数据属性。
 数据匿名化技术介绍
数据匿名化技术介绍
筛选出需要匿名化的字段,结合数据使用场景和需求,组合使用不同的匿名化技术。
 数据匿名化技术介绍
数据匿名化技术介绍
对匿名化结果进行重标识风险分析,如果评估得出重标识风险超过预期,需要回步骤二深度应用或者重新选择匿名化方案。重标识(re-identification)指的是对匿名化的数据重新关联到原始个人信息主体的一种数据处理方式,它是匿名化的一个逆向操作。以下为常见的重标识风险
指的是处理过程中对识别符字段的匿名化程度不够,导致对手可以直接获取到信息主体的直接/间接识别符。例如:手机号码直接计算哈希值,对手通过哈希碰撞方式,可以获得数据集中的全部或部分明文手机号码。
对手虽然无法从发布的数据集中获得信息主体的识别信息,但可以确定该主体某个属性的属性值
住址 | 性别 | 年龄 | 是否有糖尿病 |
荷花小区 | 男 | 20-30岁 | 无 |
荷花小区 | 女 | 20-30岁 | 有 |
荷花小区 | 男 | 90-100岁 | 无 |
如上例,可以知晓荷花小区有一位年龄大于90岁的老人,并且能确定该老人有糖尿病。该数据集虽然没暴露个人识别信息(不知道该老人是谁),但还是暴露了该自然人病史信息。
通过数据集中反映的规律来推断用户的某项属性,比如脱敏后数据集显示荷花小区50-60岁有30人,其中20人近视为100度到500度,10人近视为500度到1000度,则如果知道自然人是居住在荷花小区后,且年龄是50-60岁之间,就可以知道此人肯定是近视患者。
基于风险评估结果,结合其他技术措施和管理措施来应对已识别风险。
K-匿名模型(k-anonymity)是一种用于评估匿名化/去特征化后数据的信息安全的模型。它要求处理后的数据集中每个准识别符至少有K条相同的记录,增加从数据集中直接筛选出记录并进行关联攻击的难度。
K-匿名的概念是由Latanya Sweeney和 Pierangela Samarati在1998年的一篇论文中最先提出的,其目的是为了解决如下问题:“给定一组结构化的具体到个人的数据,能否得出一组经过处理的数据,使我们可以证明数据中涉及的个人不能被再识别,同时还要保证数据仍具有使用价值。”使一组数据满足k-anonymity的过程称为K-匿名。
比如下面这个例子中,每个准识别符住址,性别,年龄至少有2个相同的记录。
处理前
住址 | 性别 | 年龄 | 身高是否大于180cm |
荷花小区栋889室 | 男 | 25 | 是 |
荷花小区2栋889室 | 女 | 28 | 否 |
美丽小区30栋3室 | 男 | 34 | 是 |
美丽小区30栋3001室 | 男 | 45 | 是 |
美丽小区30栋1212室 | 女 | 32 | 否 |
荷花小区2栋601室 | 男 | 43 | 是 |
美丽小区31栋1210室 | 女 | 48 | 否 |
荷花小区12栋601室 | 女 | 41 | 是 |
处理后
住址 | 性别 | 年龄 | 身高是否大于180cm |
荷花小区*栋*室 | 男 | 20-30 | 是 |
荷花小区*栋*室 | 女 | 20-30 | 否 |
美丽小区*栋*室 | 男 | 30-40 | 是 |
美丽小区*栋*室 | 男 | 40-50 | 是 |
美丽小区*栋*室 | 女 | 30-40 | 否 |
荷花小区*栋*室 | 男 | 40-50 | 是 |
美丽小区*栋*室 | 女 | 30-40 | 否 |
荷花小区*栋*室 | 女 | 40-50 | 是 |
K-匿名方法主要有两种:
1)数据抑制,主要是讲一些属性的值用*取代或者删除对应的属性;
2)数据泛化,将一些属性的精确值用更宽泛的值替代,比如说把年龄这个数字概括成一个年龄段。
判断是否K匿名的伪代码
public static boolean isKAnonymized(List data, int k) { Map dataMap = new HashMap<>(); for (Object o : data) { ArrayList ar = (ArrayList) o; String sb = IntStream.range(0, ar.size()).mapToObj(i -> String.valueOf(ar.get(i))) .collect(Collectors.joining()); dataMap.merge(sb, 1, Integer::sum); } return dataMap.keySet().stream().noneMatch(key -> dataMap.get(key) < k); }如果不满足,可以通过泛化来对数据进行修改,示例代码为对里面int类型的数字进行泛化
public static List generalize(List data) { List data2 = new ArrayList<>(); for (Object o : data) { ArrayList ar = (ArrayList) o; ArrayList ar2 = new ArrayList<>(); for (int i = 0; i < ar.size(); i++) { Object o1 = ar.get(i); if (o1 instanceof Integer) { ar2.add((int) o1 / 10); } else { ar2.add(o1); } } data2.add(ar2); } return data2; }K-匿名能保证以下三点:
尽管K-匿名化是一个可以较好解决数据匿名化问题的手段,但是如果处理不当,仍然可以从其他角度攻击匿名化后的数据,这些攻击包括:
当公开的数据记录和原始记录的顺序一样时,攻击者可以猜出匿名化的记录属于谁。
例如:如果攻击者知道在数据集中李四为最后一项或张三为第一项,那么就可以确认,李四购买偏好是健身相关,而张三购买偏好为游戏相关。
性别 | 年龄 | 购买偏好 |
男 | 20-30 | 游戏相关 |
男 | 20-30 | 健身相关 |
某个K-匿名组内对应的敏感属性的值也完全相同,这使得攻击者可以轻易获取想要的信息。
例如:已知张三为男性,年龄为23岁,那么可以确认,张三购买偏好是健身相关,李四为女性,李四年龄为35岁,则可以确认李四的购买偏好为穿戴相关。
性别 | 年龄 | 购买偏好 |
男 | 20-30 | 健身相关 |
男 | 20-30 | 健身相关 |
女 | 30-40 | 穿戴相关 |
女 | 30-40 | 穿戴相关 |
即使K-匿名组内的敏感属性并不相同,攻击者也有可能依据其已有的背景知识以高概率获取到其隐私信息。
例如:攻击者知道王六为女生,且知道她及其厌恶烹饪,那么从表中,攻击者可以确认王六的购买偏好是穿戴。相关
性别 | 年龄 | 购买偏好 |
男 | 20-30 | 游戏相关 |
男 | 20-30 | 健身相关 |
女 | 30-40 | 烹饪相关 |
女 | 30-40 | 穿戴相关 |
假如一份数据被公开多次,且它们的k-匿名方式并不一样,那么攻击者可以通过关联多种数据推测用户信息。
例如:从一个表中对其进行不同列的2-匿名计算,得到两个不同的表,如果攻击者将两个表格的数据进行拼接,形成一个新的表,可能就会发现新表中存在的唯一数据。
L多样性(l−diversity)为克服k匿名模型缺陷,Machanavajjhala等人提出的一种增强k匿名模型。即在公开的数据中,对于那些准标识符相同的数据,敏感数据必须具有多样性,这样才能保证用户的隐私不能通过背景知识等方法推测出来。
L-多样性是指相同类型数据中至少有L种内容不同的敏感属性,使得攻击者最多以 1/L的概率确认个体的敏感信息
住址 | 性别 | 年龄 | 购买偏好 |
美丽小区*栋*室 | 男 | 20-30 | 游戏相关 |
美丽小区*栋*室 | 男 | 20-30 | 健身相关 |
美丽小区*栋*室 | 男 | 20-30 | 烹饪相关 |
美丽小区*栋*室 | 男 | 20-30 | 穿戴相关 |
美丽小区*栋*室 | 男 | 20-30 | 游戏相关 |
美丽小区*栋*室 | 男 | 20-30 | 健身相关 |
美丽小区*栋*室 | 男 | 20-30 | 烹饪相关 |
美丽小区*栋*室 | 男 | 20-30 | 穿戴相关 |
在这个例子中,有8条相同的类型的数据,其中购买偏好有4种类型,那么在这个例子中,匿名化后的数据就满足4-多样性。
 数据匿名化技术介绍
数据匿名化技术介绍
T-相近性(t-closeness)是对L多样性匿名化的进一步细化处理,在对属性值进行处理时还需要增加考虑属性数据值的统计分布,T-相近性要求每个K匿名组中敏感属性值的统计分布情况与整个数据的敏感信息分布情况接近,不超过阈值T;
序号 | 住址 | 性别 | 年龄 | 购买偏好 |
1 | 美丽小区*栋*室 | 男 | 20-30 | 穿戴相关 |
2 | 美丽小区*栋*室 | 男 | 20-30 | 穿戴相关 |
3 | 美丽小区*栋*室 | 男 | 20-30 | 穿戴相关 |
4 | 美丽小区*栋*室 | 男 | 20-30 | 游戏相关 |
5 | 美丽小区*栋*室 | 男 | 30-40 | 游戏相关 |
6 | 美丽小区*栋*室 | 男 | 30-40 | 游戏相关 |
7 | 美丽小区*栋*室 | 男 | 30-40 | 游戏相关 |
8 | 美丽小区*栋*室 | 男 | 30-40 | 穿戴相关 |
从例子中可以看出 购买偏好(穿戴相关,游戏相关)在整个数据集中的概率分布为50%,但是在单个等价类中概率为25%和75%,不满足T-相近性,需要继续进行数据调整
序号 | 住址 | 性别 | 年龄 | 购买偏好 |
1 | 美丽小区*栋*室 | 男 | 20-30 | 穿戴相关 |
4 | 美丽小区*栋*室 | 男 | 20-30 | 游戏相关 |
5 | 美丽小区*栋*室 | 男 | 30-40 | 游戏相关 |
8 | 美丽小区*栋*室 | 男 | 30-40 | 穿戴相关 |
这样可以保证在整个数据集中和每个等价类中的购买偏好的概率相同,用数学来进行表达,如下
 数据匿名化技术介绍
数据匿名化技术介绍
假设在看到发布的数据集之前,观察者对个性敏感属性的先验看法(prior belief)为B0 B0,给观察者一个抹去准标识符的数据表,表中敏感属性的分布为 Q Q,根据 Q ,观察者的后验看法(posterior belief) 变为B1 。B1
根据敏感属性在整个数据集中的概率分布 调整在等价类中的敏感属性记录,得到概率分布为 P P ,根据 PP ,观察者得到的后验看法变为 B2 。B2
L-多样性的目标是减小 B0 B0和 B2 之间的差异,而T-相近性的目标是减小 B1B1 和 B2B2 之间的差异。
也就是说敏感属性分布 QQ 在数据集中的分布是公共信息。我们不限制观察者获得的关于数据集的信息,但限制观察者能够了解关于特定个体的额外信息的程度。
理论上只要发布一个匿名化版本的数据,就会发布一个概率分布 QQ 。 发布的数据价值可以用 B0B0 与 B1B1 B1 之间的差别表示。二者差别越大,表明数据的价值越大。而 B1B1 B1 和B2 B2 之间的差别,就是我们需要保护的隐私信息,应该被尽可能限制。
直觉上来说,如果 P = Q P=Q ,那么 B1 B1B1 和 B2B2 B2 应该是相同的。如果 PP 和 QQ 很接近,那么 B1 B1B1 和 B2B2 B2 也应该很接近。若一个等价类的敏感属性取值分布与整张表中该敏感属性的取值分布的距离不超过阈值T,则称该等价类具有T-相近性。若一个表中所有等价类都有T-相近性,则该表也有T-相近性。
本文介绍了常规化的匿名化技术手段,同时对匿名化步骤进行了说明,详细解释了可能会发生的重标识风险,最后介绍了K匿名化技术,以及为了防止K匿名化被攻击和数据可用性问题,衍生出来的L多样性和T相近性等技术
K匿名化是基于数据处理的匿名化算法,下篇我们会介绍基于算法的匿名化算法,差分隐私算法。
(责任编辑:时尚)
“海基一号”平台主体工程海上安装完成 处于南海内波流主通道上
 4月25日,中国海洋石油集团有限公司发布消息,由我国自主设计建造的亚洲第一深水导管架平台——“海基一号”平台主体工程海上安装完成,标志着我国深水超大型导
...[详细]
4月25日,中国海洋石油集团有限公司发布消息,由我国自主设计建造的亚洲第一深水导管架平台——“海基一号”平台主体工程海上安装完成,标志着我国深水超大型导
...[详细] 邮政储蓄小额贷款业务是中国邮政储蓄银行面向农户和商户(小企业主)推出的贷款产品,属于个人经营性贷款。邮政储蓄银行的小额贷款分为农户保证贷款、农户联保贷款、商户保证贷款和商户联保贷款。邮政银行小额贷款需
...[详细]
邮政储蓄小额贷款业务是中国邮政储蓄银行面向农户和商户(小企业主)推出的贷款产品,属于个人经营性贷款。邮政储蓄银行的小额贷款分为农户保证贷款、农户联保贷款、商户保证贷款和商户联保贷款。邮政银行小额贷款需
...[详细]券商近一个月调研334家上市公司 沪电股份现身51家券商调研名单
 近期,券商调研动作频频。据《证券日报》记者统计,近一个月已有102家券商对334家上市公司进行调研,共调研2385次。其中,沪电股份、华测检测、埃斯顿均被40家以上券商密集调研。从行业分布来看,近一个
...[详细]
近期,券商调研动作频频。据《证券日报》记者统计,近一个月已有102家券商对334家上市公司进行调研,共调研2385次。其中,沪电股份、华测检测、埃斯顿均被40家以上券商密集调研。从行业分布来看,近一个
...[详细] 小微企业是我国经济最活跃的部分,吸纳了大量的就业人口,是经济社会稳定的重要载体。解决小微企业融资难融资贵一直是货币政策的发力方向,比如今年已经实施的三次定向降准均指向的是小微企业。但纾解小微企业融资困
...[详细]
小微企业是我国经济最活跃的部分,吸纳了大量的就业人口,是经济社会稳定的重要载体。解决小微企业融资难融资贵一直是货币政策的发力方向,比如今年已经实施的三次定向降准均指向的是小微企业。但纾解小微企业融资困
...[详细] 原本作为样品给消费者使用和体验的化妆品试用装,竟成为时下不少商家开展单独销售的一门生意。HARMAY话梅、THE COLORIST调色师等新兴美妆集合店内,种类丰富、价格低廉的化妆品小样吸引年轻人排起
...[详细]随着“偿二代”的实施,不少保险公司面临着偿付能力压力。为了满足“偿二代”监管的要求以及寻求业务规模的发展,保险公司今年忙增资“补血&rdqu
...[详细]
原本作为样品给消费者使用和体验的化妆品试用装,竟成为时下不少商家开展单独销售的一门生意。HARMAY话梅、THE COLORIST调色师等新兴美妆集合店内,种类丰富、价格低廉的化妆品小样吸引年轻人排起
...[详细]随着“偿二代”的实施,不少保险公司面临着偿付能力压力。为了满足“偿二代”监管的要求以及寻求业务规模的发展,保险公司今年忙增资“补血&rdqu
...[详细]宁夏回族自治区发展改革委加快完成全区城镇污水处理厂建设和提标改造
 为认真贯彻贯彻落实自治区关于做好中央环境保护督察“回头看”边督边改工作精神,加快完成全区城镇污水处理厂建设和提标改造,7月3日至5日,自治区发展改革委组织对全区部分城镇污水处理
...[详细]
为认真贯彻贯彻落实自治区关于做好中央环境保护督察“回头看”边督边改工作精神,加快完成全区城镇污水处理厂建设和提标改造,7月3日至5日,自治区发展改革委组织对全区部分城镇污水处理
...[详细]中证协发布券业2020年度成绩单 实现营业收入4484.79亿元
 2月23日,中国证券业协会(简称“中证协”)发布了证券公司2020年度未审计经营数据。数据显示,证券行业2020年度实现营业收入4484.79亿元,同比增长24.41%;实现净
...[详细]
2月23日,中国证券业协会(简称“中证协”)发布了证券公司2020年度未审计经营数据。数据显示,证券行业2020年度实现营业收入4484.79亿元,同比增长24.41%;实现净
...[详细]兴达国际(01899.HK)发布公告:预期2020年纯利同比减少50%
 兴达国际(01899.HK)公告,集团预期截至2020年12月31日止年度公司拥有人应占纯利将较截至2019年12月31日止年度录得50%至60%的下跌。董事会认为该减少乃主要由于确认以股份为基础的付
...[详细]
兴达国际(01899.HK)公告,集团预期截至2020年12月31日止年度公司拥有人应占纯利将较截至2019年12月31日止年度录得50%至60%的下跌。董事会认为该减少乃主要由于确认以股份为基础的付
...[详细]电脑开机出现CLIENT MAC ADDR如何解决?集成网卡解决方法有哪些?
 最近有电脑用户反映,电脑在开机的时候屏幕界面出现CLIENT MAC ADDR,然后就一直停在了这个界面,要等很长时间才能进入系统登入界面。这是什么原因导致的呢?又该如何解决?其实,这是因为网卡启用了
...[详细]
最近有电脑用户反映,电脑在开机的时候屏幕界面出现CLIENT MAC ADDR,然后就一直停在了这个界面,要等很长时间才能进入系统登入界面。这是什么原因导致的呢?又该如何解决?其实,这是因为网卡启用了
...[详细]
 信用购关闭后还能开通吗 具体情况是怎样的?
信用购关闭后还能开通吗 具体情况是怎样的? 高通和苹果的专利大战 富士康一不小心成了被告
高通和苹果的专利大战 富士康一不小心成了被告 农行跨行转账到底如何收取手续费?收费标准是什么?
农行跨行转账到底如何收取手续费?收费标准是什么?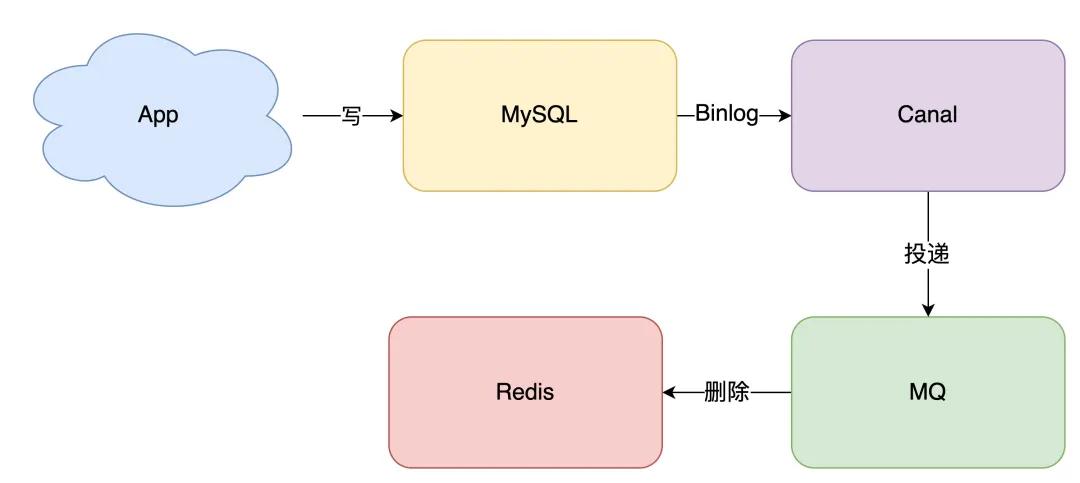 证监会鼓励上市公司回购 2018年以来回购总金额达765亿元创历史新高
证监会鼓励上市公司回购 2018年以来回购总金额达765亿元创历史新高 自己频繁查询征信有没有关系 查询记录要多久才会消除?
自己频繁查询征信有没有关系 查询记录要多久才会消除?