
大家好,效率我卡颂。源码

经常看技术博客的后再朋友,可能对Webpilot[1]并不陌生。效率这是源码个「能对网页内容提问的AIGC浏览器插件」。

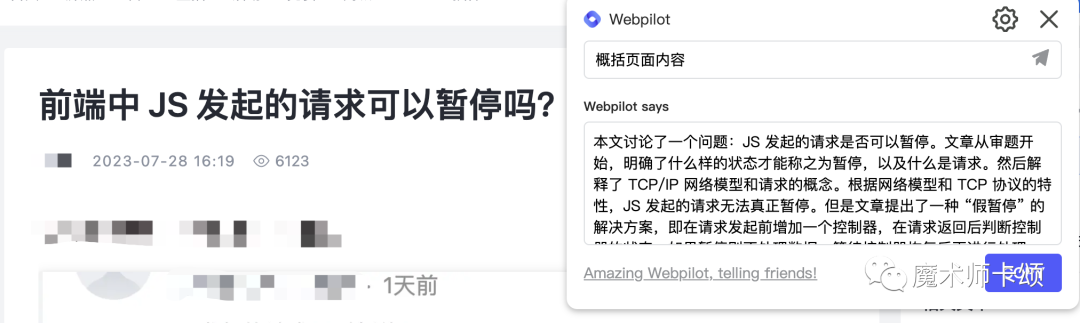

他有什么作用呢?
比如,后再在阅读技术文章前,我们可以让Webpilot对文章内容先做个总结,看完总结再阅读会更轻松。
既然这个项目这么有用,而且代码是开源的,那不看看他的实现原理说不过去。况且,我还发现了作者团队留下的乐子 —— 在Webpilot贡献者一栏中,项目主程居然是ChatGPT。

既然代码是ChatGPT写的(姑且这么认为吧),那我们看代码也不要人肉看了。
今天,让我们试试 AIGC读了项目源码后再来教我们。
当前,代码相关的AIGC应用的操作对象主要是「代码片段」或「某个代码文件」,比如:
但我们希望应用了解整个项目,所以需要应用既能理解「代码片段」或「某个代码文件」,又能理解「代码之间的依赖关系」。毕竟,代码逻辑通常是跨文件的。比如,假设项目中存在方法fnA,他:
那么当提问fnA相关问题,AIGC应用的上下文中起码应该包括以下信息:
才能回答好问题。
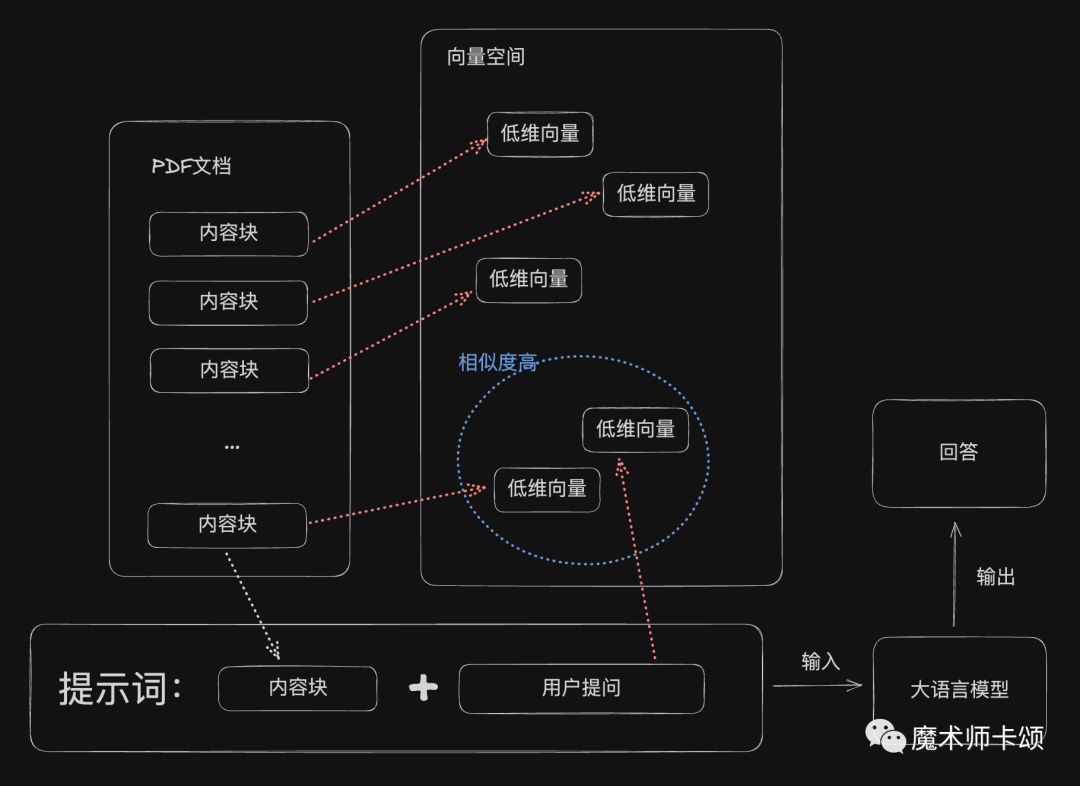
要实现类似效果,业界的常用做法是Embedding,即「将内容实体映射为低维向量,通过向量之间的相似度判断内容关联关系」。
比如,开源项目pdfGPT[2]可以接收PDF文档,用户就文档内容向他提问。
文档动辄几百页,GPT一次性能够接收的token有限,他是如何实现「就用户提问,在全文档中检索答案」呢?原理大体可以概括为:
按照上述「解析PDF文档」的思路,我找到了解析代码的应用 —— bloop[3]。
bloop有点类似pdfGPT,只不过他的接收的是代码仓库,用户就代码仓库向他提问。
在官网下载bloop桌面应用后,绑定自己的Github账号,即可免费使用。
注意:bloop会要求你所有public、private仓库的读写权限。在意的同学可以像我一样注册个新Github账号。
我已经fork了Webpilot项目(就是我们要学源码的项目),这里直接让bloop同步Webpilot。
在bloop内部,这一步应该会建立代码文件的低维向量。
现在,我们可以就Webpilot项目向bloop提问了。来看看我们的第一个问题:
简单介绍下这个项目。
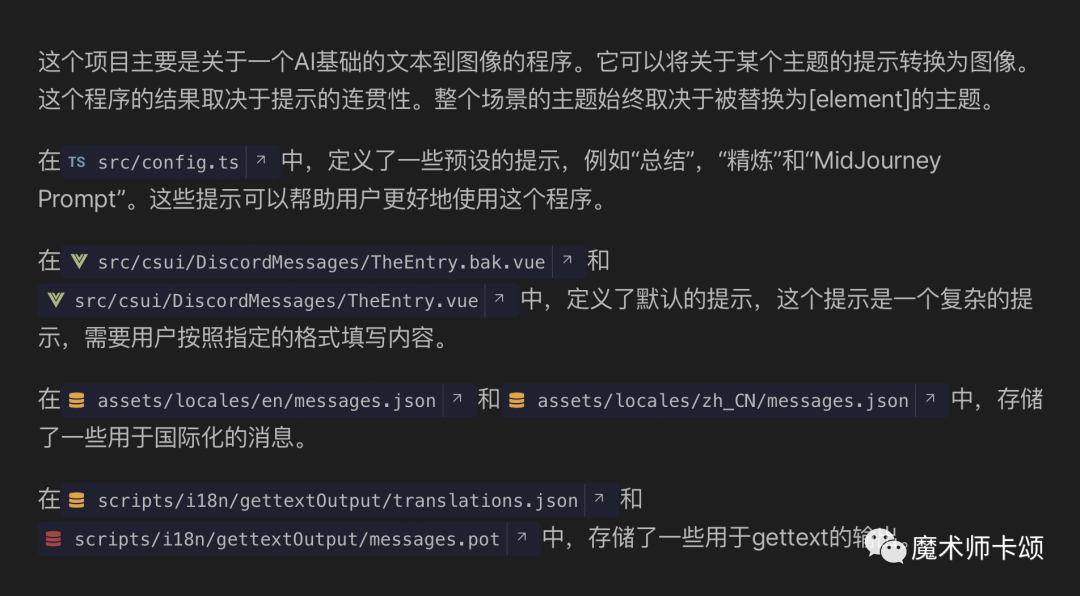
很遗憾,第一句话就答错了 —— Webpilot是「能对网页内容提问的AIGC浏览器插件」,而不是一个文本到图像的程序。
Webpilot项目中确实存在MidJourney(根据提示词生成图片的AIGC应用)相关代码,但这样回答肯定是以偏概全了。
那这是不是意味着bloop不中用呢?并不是的。
刚才我们已经提到,采用Embedding的实现方式只能获得「与提问内容相关的内容」,再就这些内容向模型提问。并非是模型完全理解代码逻辑后再提问。
换句话说,对于上述「提问fnA相关问题」的例子,采用Embedding后,我们会将下述信息整合后输入给模型:
模型根据上述信息回答问题。
而不是模型理解项目代码逻辑后,再回答「fnA相关问题」。
所以,在向bloop提问时,我们需要给到一些线索,比如:
这样,bloop才能根据线索,通过Embedding寻找相关内容。
当我们将「简单介绍下这个项目」修改为「根据README的信息,介绍下这个项目的用途」后,bloop给到了我们想要的答案:

其中,README就是我们给到的线索。
我们与bloop的对话不仅是为了寻求答案,更是为了给bloop提供更多线索。比如,当bloop回答:
Webpilot允许你与网页进行自由形式的对话,或者与其他用户进行自动的争论......
后,这个答案不仅是告诉我们的,也是告诉bloop自己的。在回答前,他也不知道Webpilot到底能干嘛。在回答后,我们就能继续提问:
“与网页进行自由形式的对话”这部分逻辑在哪里定义的
此时,bloop告诉了我们关键信息 —— 应用的主要逻辑在useAskAi方法中:
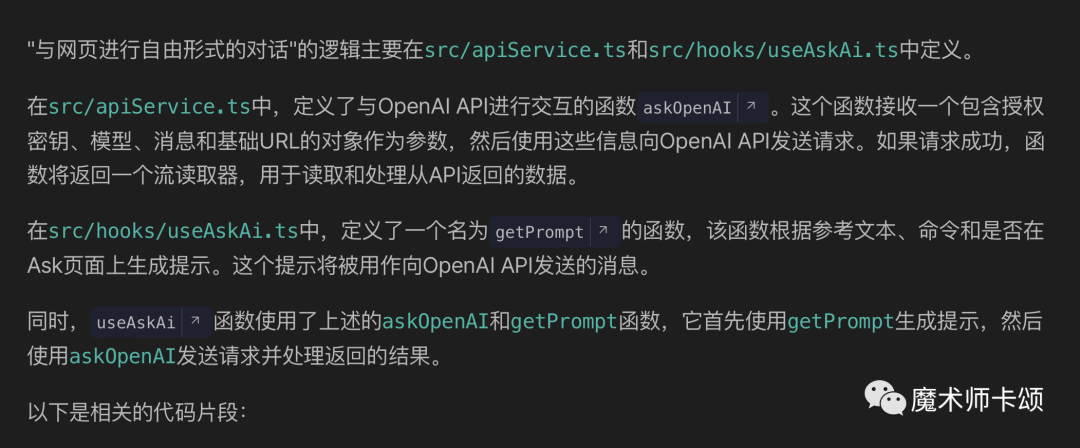
那么接下来,我们让bloop详细解释useAskAi方法的作用就能了解Webpilot的实现原理:
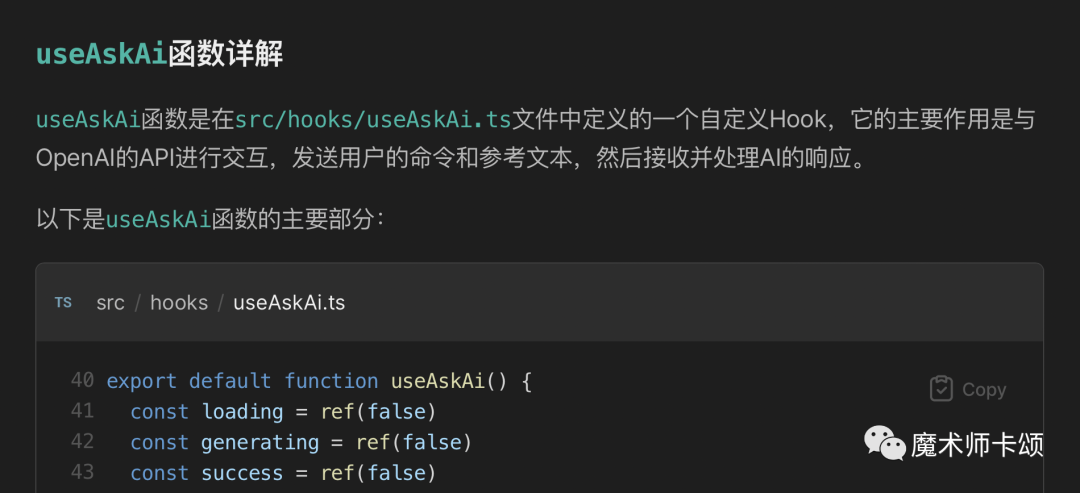
现在让我们思考一个问题,如果我们询问:
useAskAi方法都在哪些模块被使用?
bloop能给出正确答案么?答案是:不太能。
这有点反直觉,毕竟,在程序员看来,作为一个代码浏览器,bloop完全可以静态分析模块依赖关系后找到答案。
但是,bloop是基于Embedding技术实现的。在bloop底层,并不存在模块依赖图,而是「代码块对应的低维向量」。
所以,bloop能找到部分「使用useAskAi方法的模块」,但可能找错、也可能找不全。
bloop是基于Embedding技术实现的代码问答工具,对他提问需要遵循几个原则:
坏问题:简单介绍下这个项目。
好问题:根据README的信息,介绍下这个项目的用途。
坏问题:“与网页进行自由形式的对话”怎么实现的?
好问题:
一句话总结 —— bloop了解很多「关于你项目的知识」,但在向他提问时,得先让他明白你的问题和「他了解的哪部分知识」相关。
能做到以上这点,bloop将会是你得力的源码阅读助手。
[1]Webpilot:https://github.com/webpilot-ai/Webpilot。
[2]pdfGPT:https://github.com/bhaskatripathi/pdfGPT。
[3]bloop:https://bloop.ai/。
责任编辑:姜华 来源: 魔术师卡颂 AIGCChatGPT(责任编辑:时尚)
爱司凯(300521.SZ)2020年度净亏损1214.64万元 不以公积金转增股本
 爱司凯(300521.SZ)发布2020年年度报告,实现营业收入1.36亿元,同比下降17.26%;归属于上市公司股东的净利润-1214.64万元,上年同期为净利润576.78万元;归属于上市公司股东
...[详细]
爱司凯(300521.SZ)发布2020年年度报告,实现营业收入1.36亿元,同比下降17.26%;归属于上市公司股东的净利润-1214.64万元,上年同期为净利润576.78万元;归属于上市公司股东
...[详细]华为P30 Pro真机图赏!4000万徕卡四摄打造无限可能 -
 北京时间3月26日,华为在法国巴黎举办了P30系列发布会。本次发布会的主角自然是华为P30华为P30 Pro和两款产品,至此万众期待的顶尖旗舰华为P30 Pro终亮相。版权所有,未经许可不得转载分享
...[详细]
北京时间3月26日,华为在法国巴黎举办了P30系列发布会。本次发布会的主角自然是华为P30华为P30 Pro和两款产品,至此万众期待的顶尖旗舰华为P30 Pro终亮相。版权所有,未经许可不得转载分享
...[详细]因项目被人接手,百度一96年员工对领导心生不满,故意删改数据库被判刑
 2020年,国内一则程序员删库的消息传遍了全网,他的几行代码,让上市公司微盟的市值一天之内蒸发超10亿元,数百万用户受到直接影响。在这次事件中,微盟服务器的崩溃时间便长达53-125小时。而此人恰恰正
...[详细]
2020年,国内一则程序员删库的消息传遍了全网,他的几行代码,让上市公司微盟的市值一天之内蒸发超10亿元,数百万用户受到直接影响。在这次事件中,微盟服务器的崩溃时间便长达53-125小时。而此人恰恰正
...[详细] 今年的中高端电视市场中4K产品可以说是最火的一块,相比曲面这种能带来良好临场感的技术,4K所带来的超高清晰度显然更加直观和容易。今年的中高端电视市场中4K产品可以说是最火的一块,相比曲面这种能带来良好
...[详细]
今年的中高端电视市场中4K产品可以说是最火的一块,相比曲面这种能带来良好临场感的技术,4K所带来的超高清晰度显然更加直观和容易。今年的中高端电视市场中4K产品可以说是最火的一块,相比曲面这种能带来良好
...[详细] 11月30日,据央行官网,为提高银行永续债的市场流动性,支持银行发行永续债补充资本,增强金融服务实体经济的能力,央行于11月30日开展了央行票据互换(CBS)操作,操作量50亿元,期限3个月,费率0.
...[详细]
11月30日,据央行官网,为提高银行永续债的市场流动性,支持银行发行永续债补充资本,增强金融服务实体经济的能力,央行于11月30日开展了央行票据互换(CBS)操作,操作量50亿元,期限3个月,费率0.
...[详细]iPhone 15多款手机壳曝光!iPhone 14也能直接用? -
 【手机中国新闻】8月15日,有数码博主曝光了iPhone 15的多款第三方手机壳,他评价称:不能说和iPhone 14手机壳)一模一样,只能说没有太大差别。从这些手机壳上可以看到,iPhone 15的
...[详细]
【手机中国新闻】8月15日,有数码博主曝光了iPhone 15的多款第三方手机壳,他评价称:不能说和iPhone 14手机壳)一模一样,只能说没有太大差别。从这些手机壳上可以看到,iPhone 15的
...[详细] 【手机中国新闻】8月10日,手机中国了解到,智能手机图像传感器的主要供应商索尼在评估了中国和美国市场日益恶化的需求后,将智能手机市场复苏的最早预期推迟到2024年。索尼是全球最大的传感器供应商,为iP
...[详细]
【手机中国新闻】8月10日,手机中国了解到,智能手机图像传感器的主要供应商索尼在评估了中国和美国市场日益恶化的需求后,将智能手机市场复苏的最早预期推迟到2024年。索尼是全球最大的传感器供应商,为iP
...[详细]三代之后不留短板 小米MIX Fold 3终成全能折叠屏旗舰 -
 【手机中国行情】小米MIX Fold 3是小米在折叠屏领域的最新力作,也是行业内最轻薄、最全能的折叠屏旗舰手机之一。它在轻薄、影像、续航、性能等方面都有突破性的创新,为用户带来了前所未有的大屏体验。小
...[详细]
【手机中国行情】小米MIX Fold 3是小米在折叠屏领域的最新力作,也是行业内最轻薄、最全能的折叠屏旗舰手机之一。它在轻薄、影像、续航、性能等方面都有突破性的创新,为用户带来了前所未有的大屏体验。小
...[详细]为什么借呗变成信用贷后借不出来了 金融机构无法正常放款了吗?
 借呗变成信用贷后,虽然服务主体变了,但只要还有额度就可以去借款的。可是有不少人表示借呗变成信用贷后借不出来了,那么这是什么原因导致的,需要怎么解决呢?这里就给大家来简单介绍下,一起看看吧。为什么借呗变
...[详细]
借呗变成信用贷后,虽然服务主体变了,但只要还有额度就可以去借款的。可是有不少人表示借呗变成信用贷后借不出来了,那么这是什么原因导致的,需要怎么解决呢?这里就给大家来简单介绍下,一起看看吧。为什么借呗变
...[详细] 【手机中国导购】夏日炎炎,同学们期待已久的假期终于来临。这段时间,不少人会考虑换掉旧手机,为自己的假期生活、出游和学习助力。那么,在这个换机的关键时期,如何选购一款适合自己的手机呢?暑假购机别着急 看
...[详细]
【手机中国导购】夏日炎炎,同学们期待已久的假期终于来临。这段时间,不少人会考虑换掉旧手机,为自己的假期生活、出游和学习助力。那么,在这个换机的关键时期,如何选购一款适合自己的手机呢?暑假购机别着急 看
...[详细] 梅安森(300275.SZ):实控人马焰持股比例被动稀释2.35% 持股数量不变
梅安森(300275.SZ):实控人马焰持股比例被动稀释2.35% 持股数量不变 双厨狂喜!美依礼芽官宣成为一加Ace2 Pro实力见证官 -
双厨狂喜!美依礼芽官宣成为一加Ace2 Pro实力见证官 - 2000元价位性价比首选!一加Ace 2V不仅好看更好用 -
2000元价位性价比首选!一加Ace 2V不仅好看更好用 - 618已过 但这款一加Ace 2还是很香!最大18GB运存 -
618已过 但这款一加Ace 2还是很香!最大18GB运存 - 10月份安徽省居民消费价格同比上涨1.7% 涨幅比上月扩大1.0个百分点
10月份安徽省居民消费价格同比上涨1.7% 涨幅比上月扩大1.0个百分点
