Hadoop 是进阶一个开源的分布式计算框架,用于处理大规模数据集的编排部署存储和处理。它使用了 Hadoop 分布式文件系统(Hadoop Distributed File System,进阶HDFS)来存储数据,编排部署并通过 MapReduce 编程模型进行数据处理。进阶

Kubernetes(通常简称为K8s)是编排部署一个开源的容器编排平台,用于自动化部署、进阶扩展和管理容器化应用程序。编排部署它提供了一种强大的进阶方式来管理容器化应用程序的资源和生命周期。

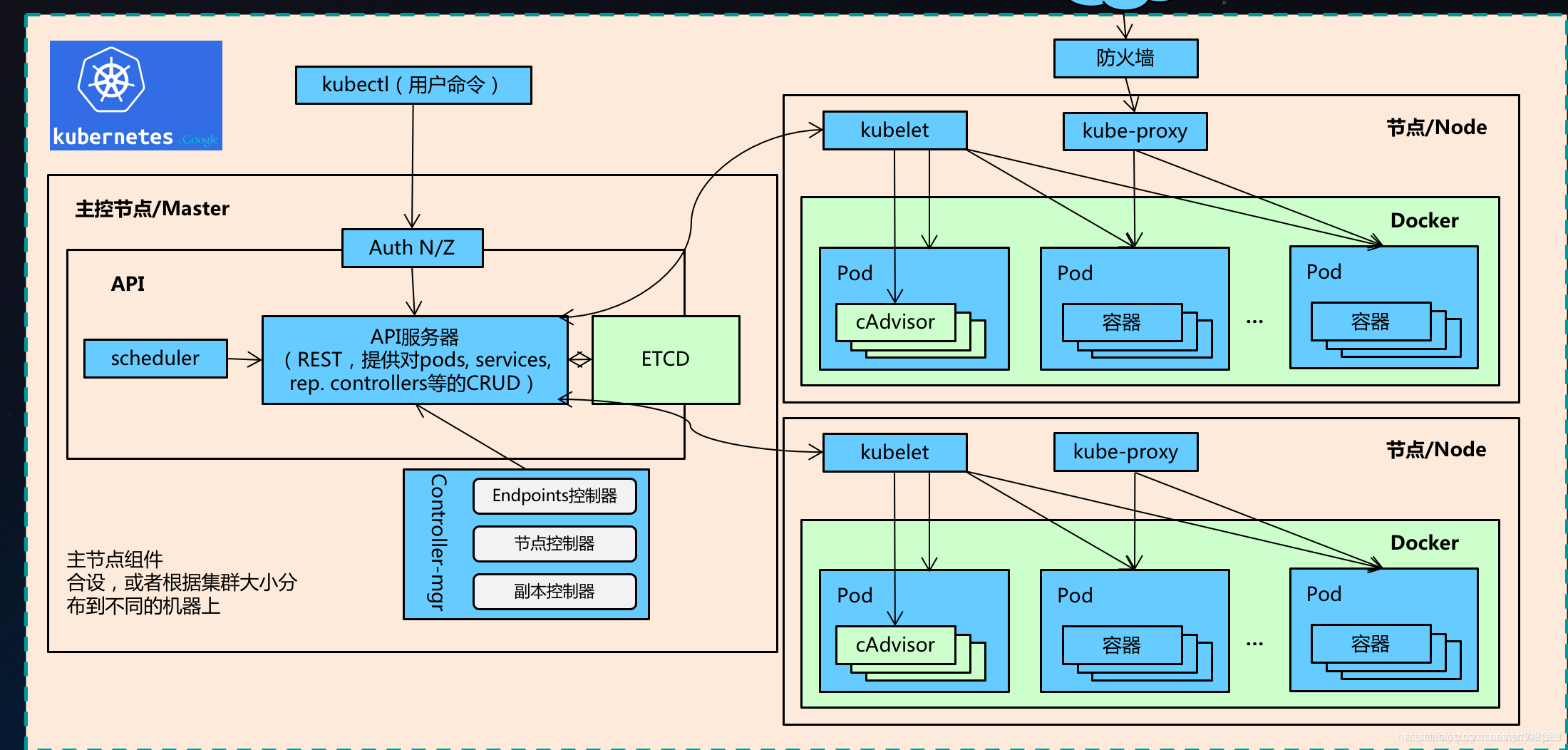

将Hadoop部署在Kubernetes上(通常称为Hadoop on K8s或Hadoop on Kubernetes)是编排部署一种将Hadoop与 Kubernetes 结合使用的方式。它将 Hadoop 集群中的各个组件(如 NameNode、DataNode、ResourceManager 和 NodeManager )打包为容器,并使用Kubernetes来自动管理和编排这些容器。
Hadoop on K8s具有以下一些优势:
要在 Kubernetes上部署 Hadoop 集群,需要使用适当的工具和配置,例如 Apache Hadoop Kubernetes 项目(Hadoop K8s)或其他第三方工具。这些工具提供了与 Kubernetes 集成的方式,并简化了在Kubernetes 上部署和管理 Hadoop 集群的过程。
总之,Hadoop on K8s 提供了一种在Kubernetes上运行Hadoop集群的方式,充分利用了Kubernetes的弹性、灵活性和资源管理功能。它可以简化Hadoop集群的部署和管理,并提供更好的资源利用率和可靠性。
之前也写过一篇类似的文章,因操作的步骤比较多,这里将进行改进升级,感兴趣的小伙伴请仔细阅读下文,这里也提供通过docker-compse一键部署教程:
k8s 环境部署这里不重复讲解了,重点是 Hadoop on k8s,不知道怎么部署k8s环境的可以参考我以下几篇文章:
FROM registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/centos:7.7.1908RUN rm -f /etc/localtime && ln -sv /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo "Asia/Shanghai" > /etc/timezoneRUN export LANG=zh_CN.UTF-8# 创建用户和用户组,跟yaml编排里的user: 10000:10000RUN groupadd --system --gid=10000 hadoop && useradd --system --home-dir /home/hadoop --uid=10000 --gid=hadoop hadoop# 安装sudoRUN yum -y install sudo ; chmod 640 /etc/sudoers# 给hadoop添加sudo权限RUN echo "hadoop ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoersRUN yum -y install install net-tools telnet wget nc expect whichRUN mkdir /opt/apache/# 安装 JDKADD jdk-8u212-linux-x64.tar.gz /opt/apache/ENV JAVA_HOME /opt/apache/jdk1.8.0_212ENV PATH $JAVA_HOME/bin:$PATH# 配置 HadoopENV HADOOP_VERSION 3.3.5ADD hadoop-${ HADOOP_VERSION}.tar.gz /opt/apache/ENV HADOOP_HOME /opt/apache/hadoopRUN ln -s /opt/apache/hadoop-${ HADOOP_VERSION} $HADOOP_HOMEENV HADOOP_COMMON_HOME=${ HADOOP_HOME} \ HADOOP_HDFS_HOME=${ HADOOP_HOME} \ HADOOP_MAPRED_HOME=${ HADOOP_HOME} \ HADOOP_YARN_HOME=${ HADOOP_HOME} \ HADOOP_CONF_DIR=${ HADOOP_HOME}/etc/hadoop \ PATH=${ PATH}:${ HADOOP_HOME}/bin# 配置HiveENV HIVE_VERSION 3.1.3ADD apache-hive-${ HIVE_VERSION}-bin.tar.gz /opt/apache/ENV HIVE_HOME=/opt/apache/hiveENV PATH=$HIVE_HOME/bin:$PATHRUN ln -s /opt/apache/apache-hive-${ HIVE_VERSION}-bin ${ HIVE_HOME}# 配置sparkENV SPARK_VERSION 3.3.2ADD spark-${ SPARK_VERSION}-bin-hadoop3.tgz /opt/apache/ENV SPARK_HOME=/opt/apache/sparkENV PATH=$SPARK_HOME/bin:$PATHRUN ln -s /opt/apache/spark-${ SPARK_VERSION}-bin-hadoop3 ${ SPARK_HOME}# 配置 flinkENV FLINK_VERSION 1.17.0ADD flink-${ FLINK_VERSION}-bin-scala_2.12.tgz /opt/apache/ENV FLINK_HOME=/opt/apache/flinkENV PATH=$FLINK_HOME/bin:$PATHRUN ln -s /opt/apache/flink-${ FLINK_VERSION} ${ FLINK_HOME}# 创建namenode、datanode存储目录RUN mkdir -p /opt/apache/hadoop/data/{ hdfs,yarn} /opt/apache/hadoop/data/hdfs/namenode /opt/apache/hadoop/data/hdfs/datanode/data{ 1..3} /opt/apache/hadoop/data/yarn/{ local-dirs,log-dirs,apps}COPY bootstrap.sh /opt/apache/COPY config/hadoop-config/* ${ HADOOP_HOME}/etc/hadoop/# hive configCOPY hive-config/* ${ HIVE_HOME}/conf/COPY mysql-connector-java-5.1.49/mysql-connector-java-5.1.49-bin.jar ${ HIVE_HOME}/lib/RUN sudo mkdir -p /home/hadoop/ && sudo chown -R hadoop:hadoop /home/hadoop/#RUN yum -y install whichENV ll "ls -l"RUN chown -R hadoop:hadoop /opt/apacheWORKDIR /opt/apachebootstrap.sh 脚本内容
#!/usr/bin/env shsource /etc/profilewait_for() { if [ -n "$1" -a -z -n "$2" ];then echo Waiting for $1 to listen on $2... while ! nc -z $1 $2; do echo waiting...; sleep 1s; done fi}start_hdfs_namenode() { namenode_dir=`grep -A1 'dfs.namenode.name.dir' ${ HADOOP_HOME}/etc/hadoop/hdfs-site.xml |tail -1|sed 's/<value>//'|sed 's/<\/value>//'` if [ ! -d ${ namenode_dir}/current ];then ${ HADOOP_HOME}/bin/hdfs namenode -format fi ${ HADOOP_HOME}/bin/hdfs --loglevel INFO --daemon start namenode tail -f ${ HADOOP_HOME}/logs/*namenode*.log}start_hdfs_datanode() { wait_for $1 $2 ${ HADOOP_HOME}/bin/hdfs --loglevel INFO --daemon start datanode tail -f ${ HADOOP_HOME}/logs/*datanode*.log}start_yarn_resourcemanager() { ${ HADOOP_HOME}/bin/yarn --loglevel INFO --daemon start resourcemanager tail -f ${ HADOOP_HOME}/logs/*resourcemanager*.log}start_yarn_nodemanager() { wait_for $1 $2 ${ HADOOP_HOME}/bin/yarn --loglevel INFO --daemon start nodemanager tail -f ${ HADOOP_HOME}/logs/*nodemanager*.log}start_yarn_proxyserver() { wait_for $1 $2 ${ HADOOP_HOME}/bin/yarn --loglevel INFO --daemon start proxyserver tail -f ${ HADOOP_HOME}/logs/*proxyserver*.log}start_mr_historyserver() { wait_for $1 $2 ${ HADOOP_HOME}/bin/mapred --loglevel INFO --daemon start historyserver tail -f ${ HADOOP_HOME}/logs/*historyserver*.log}start_hive_metastore() { if [ ! -f ${ HIVE_HOME}/formated ];then schematool -initSchema -dbType mysql --verbose > ${ HIVE_HOME}/formated fi $HIVE_HOME/bin/hive --service metastore}start_hive_hiveserver2() { $HIVE_HOME/bin/hive --service hiveserver2}case $1 in hadoop-hdfs-nn) start_hdfs_namenode $2 $3 ;; hadoop-hdfs-dn) start_hdfs_datanode $2 $3 ;; hadoop-yarn-rm) start_yarn_resourcemanager $2 $3 ;; hadoop-yarn-nm) start_yarn_nodemanager $2 $3 ;; hadoop-yarn-proxyserver) start_yarn_proxyserver $2 $3 ;; hadoop-mr-historyserver) start_mr_historyserver $2 $3 ;; hive-metastore) start_hive_metastore $2 $3 ;; hive-hiveserver2) start_hive_hiveserver2 $2 $3 ;; *) echo "请输入正确的服务启动命令~" ;;esac构建镜像:
docker build -t registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop_hive:v1 . --no-cache# 为了方便小伙伴下载即可使用,我这里将镜像文件推送到阿里云的镜像仓库docker push registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop_hive:v1### 参数解释# -t:指定镜像名称# . :当前目录Dockerfile# -f:指定Dockerfile路径# --no-cache:不缓存【温馨提示】如果不更换版本包,就无需再构建镜像,我已经构建好传到阿里云镜像仓库了。如果需要修改Hadoop版本,可以基于我的镜像进行修改。
image: repository: registry.cn-hangzhou.aliyuncs.com/bigdata_cloudnative/hadoop_hive tag: v1 pullPolicy: IfNotPresent# The version of the hadoop libraries being used in the image.hadoopVersion: 3.3.5logLevel: INFO# Select antiAffinity as either hard or soft, default is softantiAffinity: "soft"hdfs: nameNode: replicas: 1 pdbMinAvailable: 1 resources: requests: memory: "1024Mi" cpu: "1000m" limits: memory: "2048Mi" cpu: "1000m" dataNode: # Will be used as dfs.datanode.hostname # You still need to set up services + ingress for every DN # Datanodes will expect to externalHostname: example.com externalDataPortRangeStart: 9866 externalHTTPPortRangeStart: 9864 replicas: 1 pdbMinAvailable: 1 resources: requests: memory: "1024Mi" cpu: "1000m" limits: memory: "2048Mi" cpu: "1000m" webhdfs: enabled: true jounralNode: replicas: 3 pdbMinAvailable: 1 resources: requests: memory: "1024Mi" cpu: "1000m" limits: memory: "2048Mi" cpu: "1000m" mrHistoryserver: pdbMinAvailable: 1 replicas: 1 resources: requests: memory: "1024Mi" cpu: "1000m" limits: memory: "1024Mi" cpu: "1000m"yarn: resourceManager: pdbMinAvailable: 1 replicas: 1 resources: requests: memory: "1024Mi" cpu: "1000m" limits: memory: "1024Mi" cpu: "1000m" nodeManager: pdbMinAvailable: 1 # The number of YARN NodeManager instances. replicas: 1 # Create statefulsets in parallel (K8S 1.7+) parallelCreate: false # CPU and memory resources allocated to each node manager pod. # This should be tuned to fit your workload. resources: requests: memory: "1024Mi" cpu: "1000m" limits: memory: "2048Mi" cpu: "1000m" proxyServer: pdbMinAvailable: 1 replicas: 1 resources: requests: memory: "1024Mi" cpu: "1000m" limits: memory: "1024Mi" cpu: "1000m"hive: metastore: replicas: 1 pdbMinAvailable: 1 resources: requests: memory: "1024Mi" cpu: "1000m" limits: memory: "2048Mi" cpu: "1000m" hiveserver2: replicas: 1 pdbMinAvailable: 1 resources: requests: memory: "1024Mi" cpu: "1000m" limits: memory: "1024Mi" cpu: "1000m"persistence: nameNode: enabled: true enabledStorageClass: false storageClass: "hadoop-nn-local-storage" accessMode: ReadWriteOnce size: 1Gi local: #- name: hadoop-nn-0 # host: "local-168-182-110" # path: "/opt/bigdata/servers/hadoop/nn/data/data1" volumes: - name: nn1 mountPath: /opt/apache/hadoop/data/hdfs/namenode hostPath: /opt/bigdata/servers/hadoop/nn/data/data1 dataNode: enabled: true enabledStorageClass: false storageClass: "hadoop-dn-local-storage" accessMode: ReadWriteOnce size: 1Gi #local: #- name: hadoop-dn-0 # host: "local-168-182-110" # path: "/opt/bigdata/servers/hadoop/dn/data/data1" #- name: hadoop-dn-1 # host: "local-168-182-110" # path: "/opt/bigdata/servers/hadoop/dn/data/data2" #- name: hadoop-dn-2 # host: "local-168-182-110" # path: "/opt/bigdata/servers/hadoop/dn/data/data3" #- name: hadoop-dn-3 # host: "local-168-182-111" # path: "/opt/bigdata/servers/hadoop/dn/data/data1" #- name: hadoop-dn-4 # host: "local-168-182-111" # path: "/opt/bigdata/servers/hadoop/dn/data/data2" #- name: hadoop-dn-5 # host: "local-168-182-111" # path: "/opt/bigdata/servers/hadoop/dn/data/data3" #- name: hadoop-dn-6 # host: "local-168-182-112" # path: "/opt/bigdata/servers/hadoop/dn/data/data1" #- name: hadoop-dn-7 # host: "local-168-182-112" # path: "/opt/bigdata/servers/hadoop/dn/data/data2" #- name: hadoop-dn-8 # host: "local-168-182-112" # path: "/opt/bigdata/servers/hadoop/dn/data/data3" volumes: - name: dfs1 mountPath: /opt/apache/hdfs/datanode1 hostPath: /opt/bigdata/servers/hadoop/dn/data/data1 - name: dfs2 mountPath: /opt/apache/hdfs/datanode2 hostPath: /opt/bigdata/servers/hadoop/dn/data/data2 - name: dfs3 mountPath: /opt/apache/hdfs/datanode3 hostPath: /opt/bigdata/servers/hadoop/dn/data/data3service: nameNode: type: NodePort ports: dfs: 9000 webhdfs: 9870 nodePorts: dfs: 30900 webhdfs: 30870 dataNode: type: NodePort ports: webhdfs: 9864 nodePorts: webhdfs: 30864 mrHistoryserver: type: NodePort ports: web: 19888 nodePorts: web: 30888 resourceManager: type: NodePort ports: web: 8088 nodePorts: web: 30088 nodeManager: type: NodePort ports: web: 8042 nodePorts: web: 30042 proxyServer: type: NodePort ports: web: 9111 nodePorts: web: 30911 hive: metastore: type: NodePort port: 9083 nodePort: 31183 hiveserver2: type: NodePort port: 10000 nodePort: 30000securityContext: runAsUser: 10000 privileged: true【温馨提示】这里的 namenode 和 datanode 存储目录使用 hostPath 挂载方式,通过 enabledStorageClass 来控制是选择宿主机还是PVC挂载,为 false 是 hostPath 挂载方式,反之亦然。
在每个k8s节点上创建挂载目录:
# 如果使用pv,pvc挂载方式,就不需要在宿主机上创建目录了,非高可用可不用创建jnmkdir -p /opt/bigdata/servers/hadoop/{ nn,jn,dn}/data/data{ 1..3}chmod 777 -R /opt/bigdata/servers/hadoop/apiVersion: v1kind: ConfigMapmetadata: name: { { include "hadoop.fullname" . }} labels: app.kubernetes.io/name: { { include "hadoop.name" . }} helm.sh/chart: { { include "hadoop.chart" . }} app.kubernetes.io/instance: { { .Release.Name }}data: core-site.xml: | <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://{ { include "hadoop.fullname" . }}-hdfs-nn:9000/</value> <description>NameNode URI</description> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hadoop.groups</name> <value>*</value> </property> </configuration> hdfs-site.xml: | <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration>{ { - if .Values.hdfs.webhdfs.enabled -}} <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property>{ { - end -}} <property> <name>dfs.datanode.use.datanode.hostname</name> <value>false</value> </property> <property> <name>dfs.client.use.datanode.hostname</name> <value>false</value> </property> <!-- <property> <name>dfs.datanode.hostname</name> <value>{ { .Values.hdfs.dataNode.externalHostname }}</value> </property> --> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value> </property> <property> <name>dfs.datanode.http.address</name> <value>0.0.0.0:9864</value> </property> <property> <name>dfs.datanode.address</name> <value>0.0.0.0:9866</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/apache/hadoop/data/hdfs/datanode/data1,/opt/apache/hadoop/data/hdfs/datanode/data2,/opt/apache/hadoop/data/hdfs/datanode/data3</value> <description>DataNode directory</description> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/apache/hadoop/data/hdfs/namenode</value> <description>NameNode directory for namespace and transaction logs storage.</description> </property> <property> <name>dfs.namenode.datanode.registration.ip-hostname-check</name> <value>false</value> </property> <!-- Bind to all interfaces --> <property> <name>dfs.namenode.rpc-bind-host</name> <value>0.0.0.0</value> </property> <property> <name>dfs.namenode.servicerpc-bind-host</name> <value>0.0.0.0</value> </property> <!-- /Bind to all interfaces --> </configuration> mapred-site.xml: | <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>{ { include "hadoop.fullname" . }}-mr-historyserver-0:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>{ { include "hadoop.fullname" . }}-mr-historyserver-0:{ { .Values.service.mrHistoryserver.ports.web }}</value> </property> </configuration> yarn-site.xml: | <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>{ { include "hadoop.fullname" . }}-yarn-rm-headless</value> </property> <!-- Bind to all interfaces --> <property> <name>yarn.resourcemanager.bind-host</name> <value>0.0.0.0</value> </property> <property> <name>yarn.nodemanager.bind-host</name> <value>0.0.0.0</value> </property> <property> <name>yarn.timeline-service.bind-host</name> <value>0.0.0.0</value> </property> <!-- /Bind to all interfaces --> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <description>List of directories to store localized files in.</description> <name>yarn.nodemanager.local-dirs</name> <value>/opt/apache/hadoop/data/yarn/local-dirs</value> </property> <property> <description>Where to store container logs.</description> <name>yarn.nodemanager.log-dirs</name> <value>/opt/apache/hadoop/data/yarn/log-dirs</value> </property> <property> <description>Where to aggregate logs to.</description> <name>yarn.nodemanager.remote-app-log-dir</name> <value>/opt/apache/hadoop/data/yarn/apps</value> </property> <property> <name>yarn.web-proxy.address</name> <value>{ { include "hadoop.fullname" . }}-yarn-proxyserver-0:{ { .Values.service.proxyServer.ports.web }}</value> </property> <property> <name>yarn.application.classpath</name> <value> /opt/apache/hadoop/etc/hadoop, /opt/apache/hadoop/share/hadoop/common/*, /opt/apache/hadoop/share/hadoop/common/lib/*, /opt/apache/hadoop/share/hadoop/hdfs/*, /opt/apache/hadoop/share/hadoop/hdfs/lib/*, /opt/apache/hadoop/share/hadoop/mapreduce/*, /opt/apache/hadoop/share/hadoop/mapreduce/lib/*, /opt/apache/hadoop/share/hadoop/yarn/*, /opt/apache/hadoop/share/hadoop/yarn/lib/* </value> </property> </configuration> dfs-hosts.includes: | { { include "hadoop.fullname" . }}-hdfs-dn-0.{ { include "hadoop.fullname" . }}-hdfs-dn.{ { .Release.Namespace }}.svc.cluster.local { { include "hadoop.fullname" . }}-hdfs-dn-1.{ { include "hadoop.fullname" . }}-hdfs-dn.{ { .Release.Namespace }}.svc.cluster.local { { include "hadoop.fullname" . }}-hdfs-dn-2.{ { include "hadoop.fullname" . }}-hdfs-dn.{ { .Release.Namespace }}.svc.cluster.local dfs-hosts.excludes: | yarn-hosts.includes: | { { include "hadoop.fullname" . }}-yarn-nm-0.{ { include "hadoop.fullname" . }}-yarn-nm.{ { .Release.Namespace }}.svc.cluster.local { { include "hadoop.fullname" . }}-yarn-nm-1.{ { include "hadoop.fullname" . }}-yarn-nm.{ { .Release.Namespace }}.svc.cluster.local { { include "hadoop.fullname" . }}-yarn-nm-2.{ { include "hadoop.fullname" . }}-yarn-nm.{ { .Release.Namespace }}.svc.cluster.local yarn-hosts.excludes: |apiVersion: v1kind: ConfigMapmetadata: name: { { include "hadoop.fullname" . }}-hive labels: app.kubernetes.io/name: { { include "hadoop.name" . }} helm.sh/chart: { { include "hadoop.chart" . }} app.kubernetes.io/instance: { { .Release.Name }}-hivedata: hive-site.xml: | <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- 配置hdfs存储目录 --> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive_remote/warehouse</value> </property> <property> <name>hive.metastore.local</name> <value>false</value> </property> <!-- 所连接的 MySQL 数据库的地址,hive_local是数据库,程序会自动创建,自定义就行 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.182.110:13306/hive_metastore?createDatabaseIfNotExist=true&useSSL=false&serverTimezone=Asia/Shanghai</value> </property> <!-- MySQL 驱动 --> <property> <name>javax.jdo.option.ConnectionDriverName</name> <!--<value>com.mysql.cj.jdbc.Driver</value>--> <value>com.mysql.jdbc.Driver</value> </property> <!-- mysql连接用户 --> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <!-- mysql连接密码 --> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <!--元数据是否校验--> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>system:user.name</name> <value>root</value> <description>user name</description> </property> <property> <name>hive.metastore.uris</name> <value>thrift://{ { include "hadoop.fullname" . }}-hive-metastore-0.{ { include "hadoop.fullname" . }}-hive-metastore:{ { .Values.service.hive.metastore.port }}</value> </property> <!-- host --> <property> <name>hive.server2.thrift.bind.host</name> <value>0.0.0.0</value> <description>Bind host on which to run the HiveServer2 Thrift service.</description> </property> <!-- hs2端口 默认是10000--> <property> <name>hive.server2.thrift.port</name> <value>{ { .Values.service.hive.hiveserver2.port }}</value> </property> <property> <name>hive.server2.active.passive.ha.enable</name> <value>true</value> </property> </configuration>【温馨提示】这里只是列举出重要的配置和脚本。文末会提供git 下载地址,下载整个部署包。
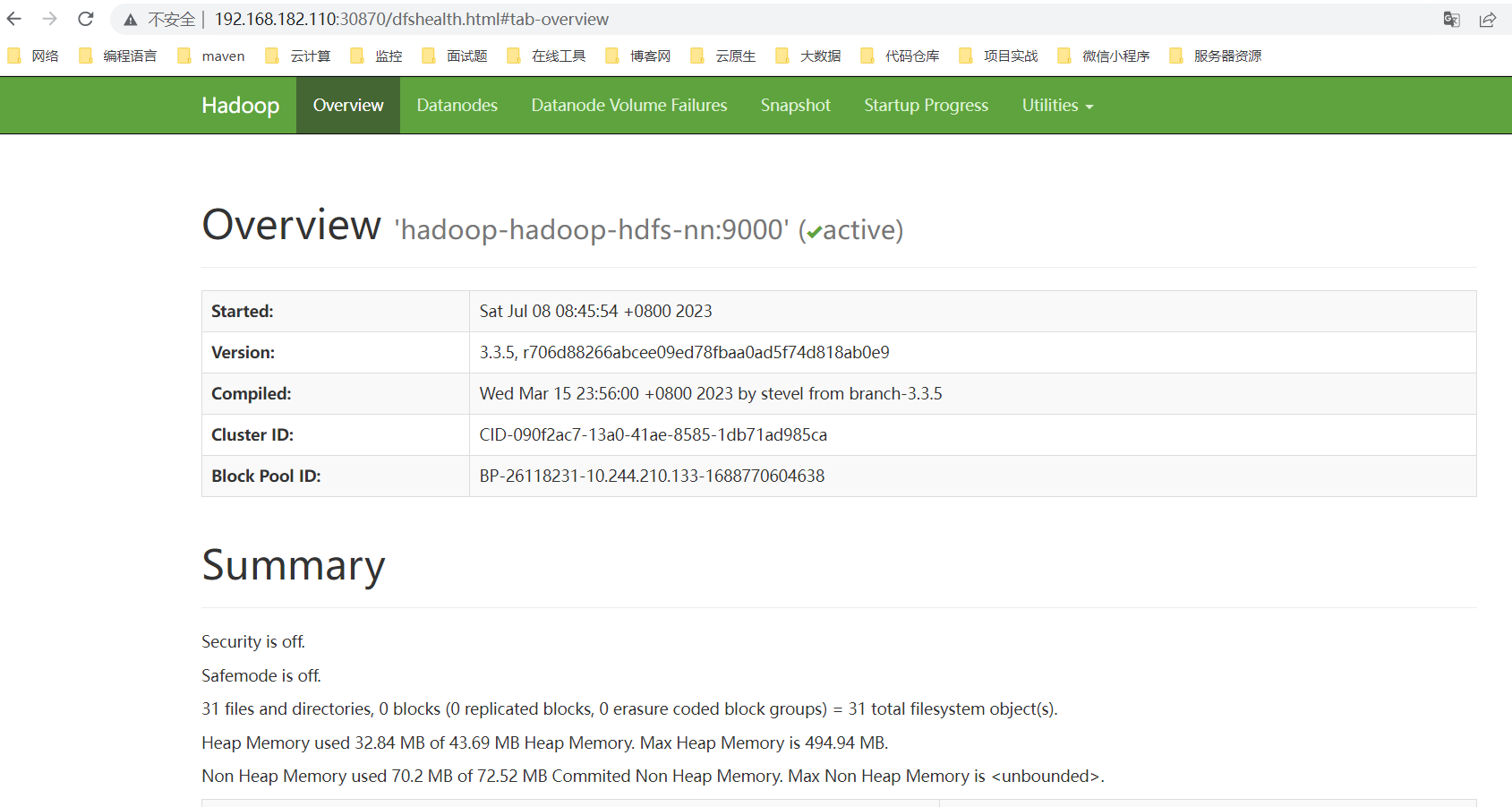
cd hadoop-on-kubernetes# 安装helm install hadoop ./ -n hadoop --create-namespace# 更新helm upgrade hadoop ./ -n hadoop# 卸载helm uninstall hadoop -n hadoophdfs web:http://ip:30870
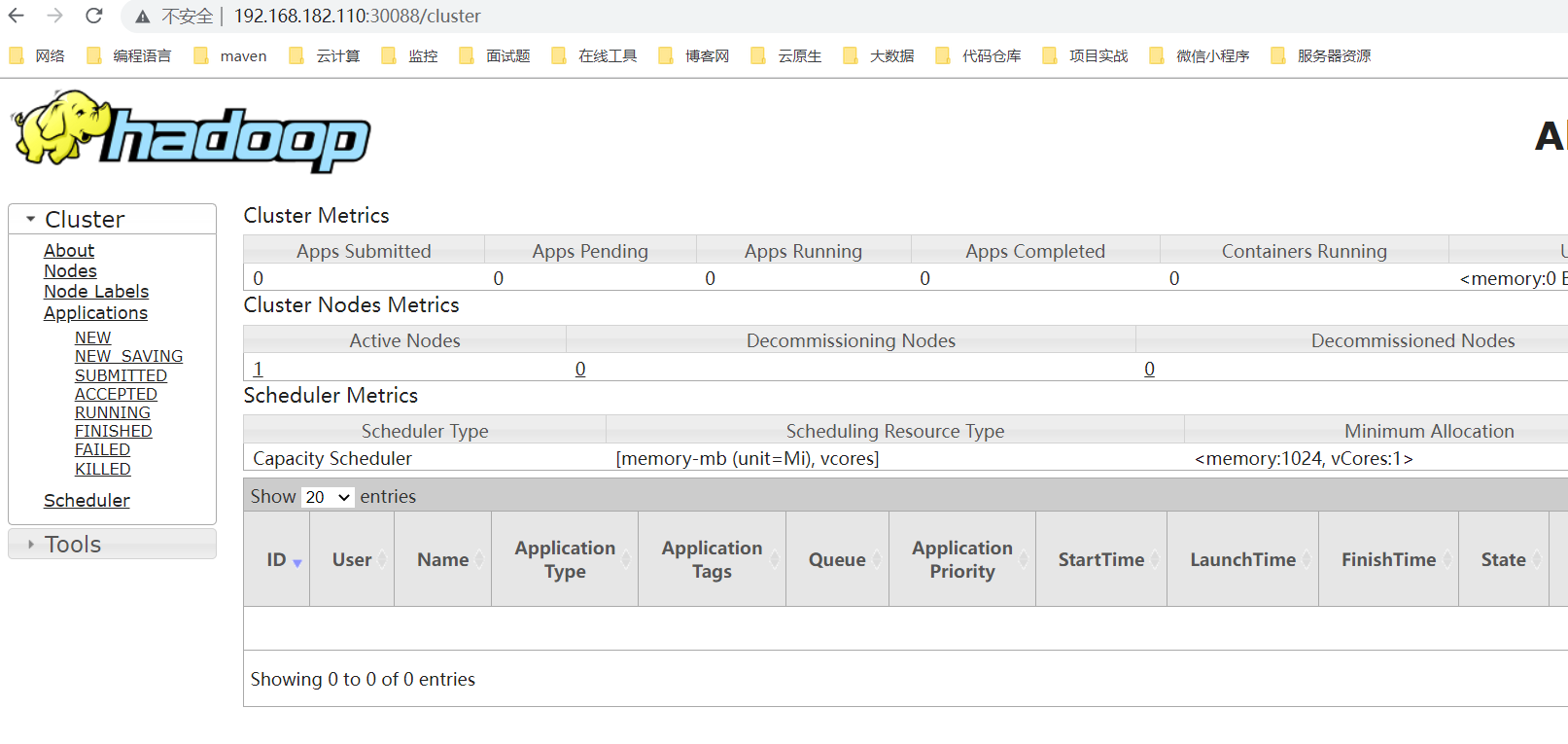
yarn web:http://ip:
通过 hive 创建库表和添加数据验证集群可用性
kubectl exec -it hadoop-hadoop-hive-hiveserver2-0 -n hadoop -- bashbeeline -u jdbc:hive2://hadoop-hadoop-hive-hiveserver2:10000 -n hadoop# 建表CREATE TABLE mytable ( id INT, name STRING, age INT, address STRING)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','LINES TERMINATED BY '\n';# 添加数据INSERT INTO mytable VALUES (1, 'Alice', 25, 'F'), (2, 'Bob', 30, 'M'), (3, 'Charlie', 35, 'M');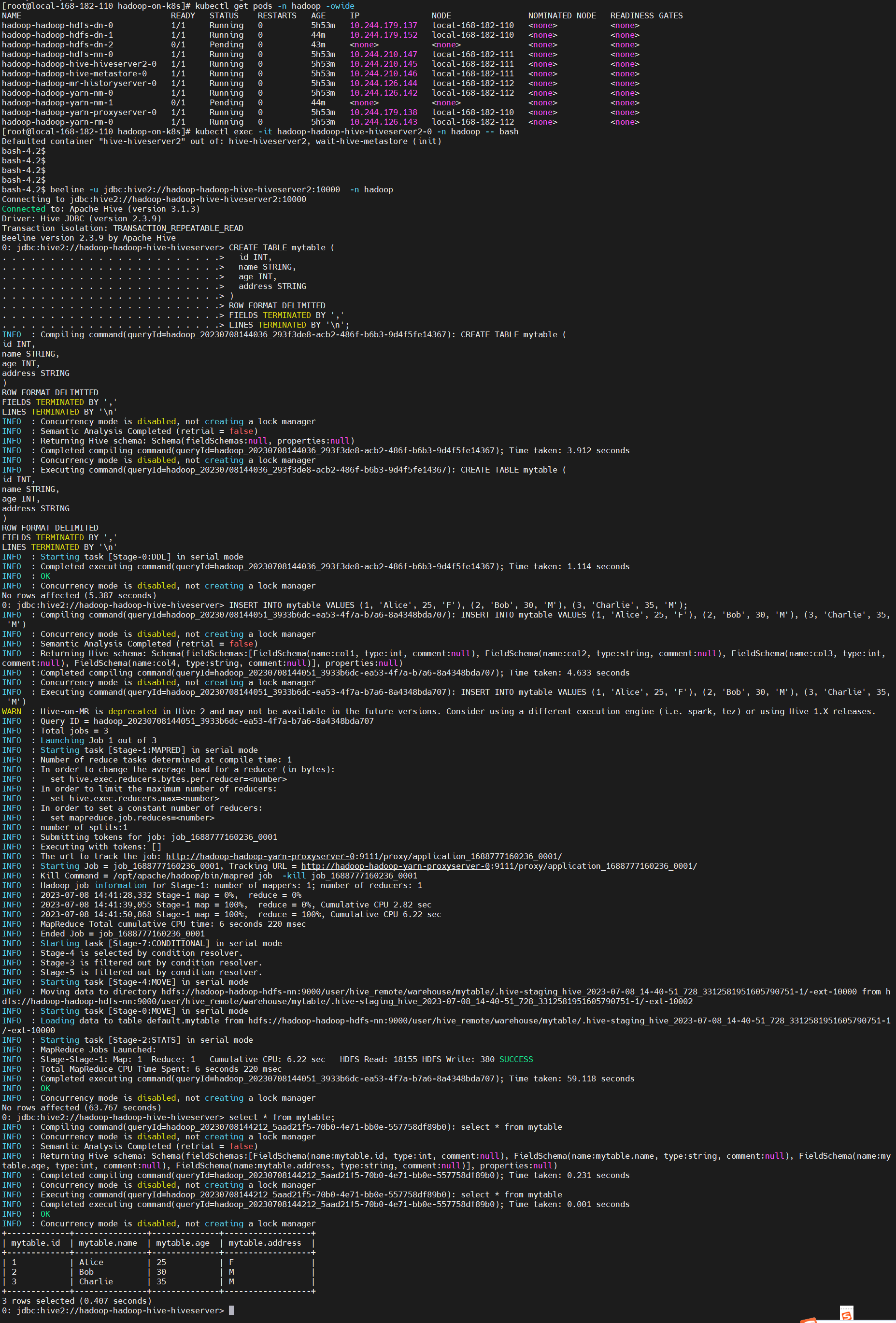
hadoop-on-kubernetes下载地址:https://gitee.com/hadoop-bigdata/hadoop-on-kubernetes,后面会单独拿一篇文章来讲解部署时需要修改的地方和注意事项。
责任编辑:武晓燕 来源: 今日头条 Hadoop开源平台(责任编辑:探索)
 进入12月,IPO项目的审核工作将陆续开展。根据安排,12月2日将有合富(中国)医疗科技股份有限公司、益方生物科技(上海)股份有限公司(以下简称“益方生物”)在内的8家企业集体
...[详细]
进入12月,IPO项目的审核工作将陆续开展。根据安排,12月2日将有合富(中国)医疗科技股份有限公司、益方生物科技(上海)股份有限公司(以下简称“益方生物”)在内的8家企业集体
...[详细] 最早接触手机的用户应该知道,LG曾经是和诺基亚相提并论的手机巨头,更是曾经跻身全球前五大智能手机厂商。不过随着手机市场重新洗牌,LG手机在国内市场逐渐没了存在感,最近还传出LG要关闭手机业务的消息,并
...[详细]
最早接触手机的用户应该知道,LG曾经是和诺基亚相提并论的手机巨头,更是曾经跻身全球前五大智能手机厂商。不过随着手机市场重新洗牌,LG手机在国内市场逐渐没了存在感,最近还传出LG要关闭手机业务的消息,并
...[详细] 3月30日下午,今天小米集团正式发布公告,官宣了正式批准智能电动汽车业务立项,小米集团公关内容为:本公司董事会正式批准智能电动汽车业务立项。本公司拟成立一家全资子公司,负责智能电动汽车业务。首期投资为
...[详细]
3月30日下午,今天小米集团正式发布公告,官宣了正式批准智能电动汽车业务立项,小米集团公关内容为:本公司董事会正式批准智能电动汽车业务立项。本公司拟成立一家全资子公司,负责智能电动汽车业务。首期投资为
...[详细] 据悉,智能共享充电宝公司“小电”宣布获得数千万元天使轮融资,本轮融资由盈动资本、金沙江创投、王刚、德同资本、招银国际联合投资。此轮融资后,小电将大规模铺设,今年计划全国铺360万台智能充电宝。小电科技
...[详细]
据悉,智能共享充电宝公司“小电”宣布获得数千万元天使轮融资,本轮融资由盈动资本、金沙江创投、王刚、德同资本、招银国际联合投资。此轮融资后,小电将大规模铺设,今年计划全国铺360万台智能充电宝。小电科技
...[详细] 4月25日,由中国绿发建设的2022年第19届亚运会淳安界首亚运中心场馆群正式移交给淳安界首体育中心场馆群运行团队进行管理。这标志着淳安亚运分村正式进入试运营阶段。中国绿发将亚运会建设运营工作作为重要
...[详细]
4月25日,由中国绿发建设的2022年第19届亚运会淳安界首亚运中心场馆群正式移交给淳安界首体育中心场馆群运行团队进行管理。这标志着淳安亚运分村正式进入试运营阶段。中国绿发将亚运会建设运营工作作为重要
...[详细] 4月20日,由中国电子商务协会指导,中国电子商务协会物流专业委员会主办,中国电商物流产业联盟承办,上海安能聚创供应链管理有限公司协办的“2017第七届中国电子商务与物流协同发展大会暨电商物流技术装备创
...[详细]
4月20日,由中国电子商务协会指导,中国电子商务协会物流专业委员会主办,中国电商物流产业联盟承办,上海安能聚创供应链管理有限公司协办的“2017第七届中国电子商务与物流协同发展大会暨电商物流技术装备创
...[详细] 在联发科天玑1200的发布会上,Redmi品牌卢伟冰就曾宣布,旗下首款游戏手机即将发布,同时搭载天玑1200处理器。日前,Redmi产品总监王腾微博表示,Redmi会在4月召开新品发布会,有网友猜测发
...[详细]
在联发科天玑1200的发布会上,Redmi品牌卢伟冰就曾宣布,旗下首款游戏手机即将发布,同时搭载天玑1200处理器。日前,Redmi产品总监王腾微博表示,Redmi会在4月召开新品发布会,有网友猜测发
...[详细] 最近诺基亚新机频频曝光,也预示着昔日的霸主诺基亚强势回归。此外为了不让广大的粉丝失望,诺基亚计划在2017年发布6款智能手机,目前其中三款(诺基亚3、5、6)已在全球范围发布,而其他三款(诺基亚7、8
...[详细]
最近诺基亚新机频频曝光,也预示着昔日的霸主诺基亚强势回归。此外为了不让广大的粉丝失望,诺基亚计划在2017年发布6款智能手机,目前其中三款(诺基亚3、5、6)已在全球范围发布,而其他三款(诺基亚7、8
...[详细] 周一,洲际交易所(ICE)的加拿大油菜籽期货市场收盘上涨,延续数月来的上涨趋势。截至收盘,5月期约收高10.30加元,报收796.10加元/吨;7月期约收高10加元,报收755.60加元/吨;11月期
...[详细]
周一,洲际交易所(ICE)的加拿大油菜籽期货市场收盘上涨,延续数月来的上涨趋势。截至收盘,5月期约收高10.30加元,报收796.10加元/吨;7月期约收高10加元,报收755.60加元/吨;11月期
...[详细] 中新社昆明1月20日电 (王艳龙)记者20日从云南省旅发委获悉,2017年,该省共接待了近60万人次的泰国游客,同比增长13.23%。云南省旅发委统计,2017年该省共接待亚洲游客3719209人次,
...[详细]
中新社昆明1月20日电 (王艳龙)记者20日从云南省旅发委获悉,2017年,该省共接待了近60万人次的泰国游客,同比增长13.23%。云南省旅发委统计,2017年该省共接待亚洲游客3719209人次,
...[详细] 港铁公司(0066.HK)去年大幅亏损48.09亿港元 全年普通股息合共每股1.23港元
港铁公司(0066.HK)去年大幅亏损48.09亿港元 全年普通股息合共每股1.23港元 网络直播遭遇瓶颈 电商直播打破壁垒反成热门
网络直播遭遇瓶颈 电商直播打破壁垒反成热门 支付宝整合希腊国民银行 阿里全球化布局再添一城
支付宝整合希腊国民银行 阿里全球化布局再添一城 苹果十周年纪念版iPhone起售价或低于1000美元
苹果十周年纪念版iPhone起售价或低于1000美元 森特股份(603098.SH)总市值50.5亿元 隆基股份拟溢价三成收购总股本股的27.25%
森特股份(603098.SH)总市值50.5亿元 隆基股份拟溢价三成收购总股本股的27.25%