1. 什么是知识图谱
我们的现实世界中有多种类型的事物:

事物之间有多种类型的链接:

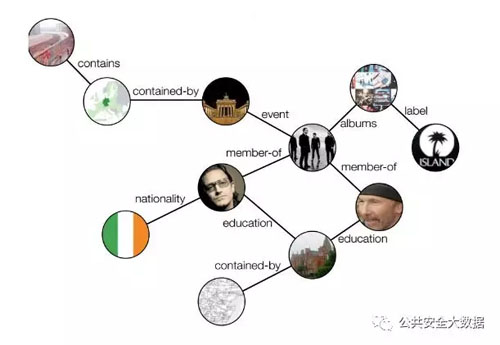
而知识图谱即用来描述真实世界中存在的各种实体或概念,以及它们之间的储实关联关系。

其中:
从抽象层面看,谱数本体最抽象,据存其次是储实知识库,***才是战解知识图谱,因此本体与知识图谱的大规区别在于以下三点:
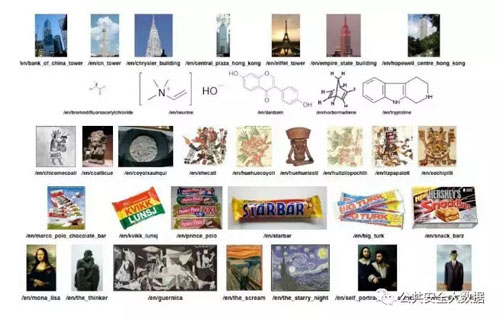
1.1 知识图谱的应用
知识图谱已经在人工和商业智能方面有了一系列的应用,包括聊天机器人,临床决策支持等。
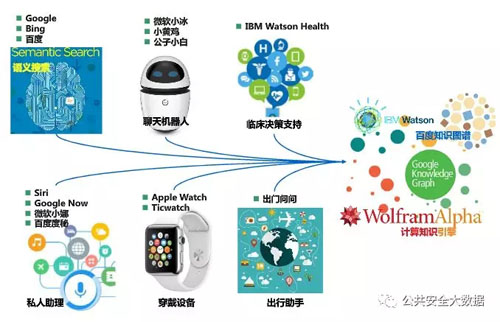
同时为了应对大数据应用的不同挑战,借助知识图谱,实现不同的业务需求。
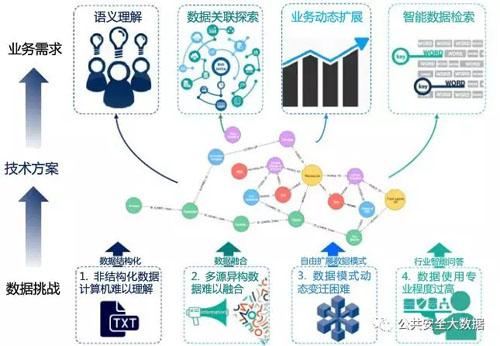
2. 知识图谱的适用场景
我们看到知识图谱有了如此多的应用,不过它最适合处理还是这些数据:
关系复杂的数据;
类型繁多的数据;
结构多变的数据。
作为数据融合与链接的纽带,知识图谱整合结构化、半结构化和非结构化数据,拥有如下的消费和数据场景
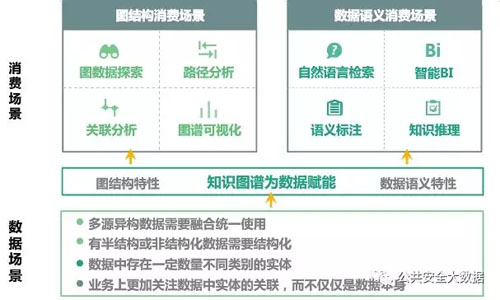
但知识图谱不是银弹!需要我们依据不同的问题寻找合适的方法,不要为了用知识图谱而用知识图谱。
知识图谱的不适用场景如下:
不适用的数据场景:
不适用的消费场景:
这些不适用场景都需要借助其它工具存储和处理,同时结合其它工具和方法使用,最终与知识图谱进行数据链接。
3. 知识图谱的存储
通过上面的内容,我们了解到知识图谱最适合处理关联密集型的数据,因此首先需要存放的是图谱中的节点和边的数据;知识图谱基于图数据库的优点,能够方便的存放这一类关系型的数据,对于大量其他类型的数据我们如何处理呢?


由此可知知识图谱数据的存储不等于图数据库。
接下来本文重点介绍知识图谱数据存储的几种常见方式。
3.1 知识图谱数据存储的几种常见方式
知识图谱的存储并不依赖特定的底层结构,一般的做法是按数据和应用的需求采用不同的底层存储。你甚至可以基于现有关系数据库或NoSQL数据库进行构建。我们来列举一下几种常见做法:
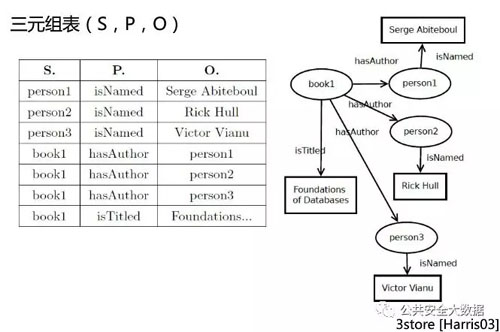
三元组表(S,P,O)
类似RDF存储结构(下文会进行介绍),以元组为单元进行存储。语义较为明确。
问题:大量自连接操作的开销巨大。
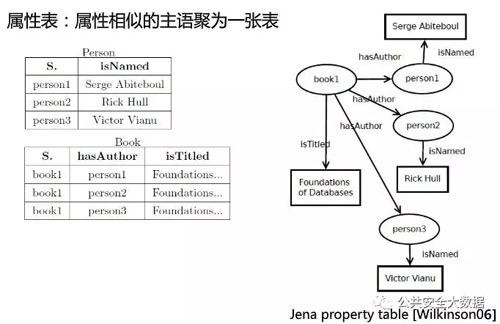
属性表:属性相似的主语聚为一张表
类似关系型数据结构,每一条数据代表一个实体,每一列代表一个属性。
问题:1.RDF灵活性(高于一阶的关系查询很复杂);2.查询时必须指定属性,无法做不确定属性的查询。
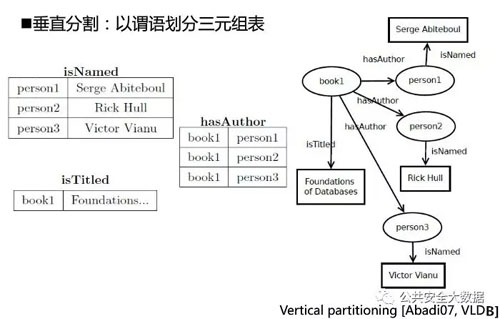
垂直分割:以谓语划分三元组表
根据属性的不同建立数据表,数据结构较为清晰。
问题:1.大量数据表;2.删除属性代价大。
以上这些方案都会有各自的优缺点,在实现时需要根据不同的应用场景来进行选择,并设计索引、约束等方法来解决查询效率问题。
目前图结构存储有两种通用的存储方案:RDF存储和图数据库(Graph Database)。下图为两种存储在http://db-engines.com/上的发展趋势:
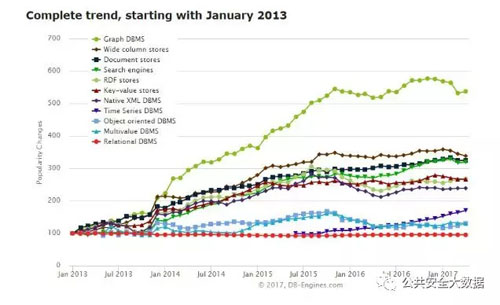
可以明显地看到基于图的存储方式在整个数据库存储领域的发展飞速。
3.1.1 RDF存储
RDF存储亦称三元组存储(triplestore),它是专为存储三元组形式的数据而设计的专用数据库,通过六重索引(SPO、SOP、PSO、POS、OSP、OPS)的方式解决了三元组搜索的效率问题。
其优点是:
三元组模式查询(triple pattern)的高效执行;
任意两个三元组模式的高效归并连接(merge-join)。
但缺点也很明显:
六重索引意味着6倍空间开销,如果是 (S, P, O, C) 四元组呢?
更新维护代价大。
现在越来越多的RDF数据库通过列式存储的方式来对三元组进行存储,进一步提高六重索引下的查询效率。
3.1.2 图数据库
图数据库的结构定义相比RDF数据库更为通用,实现了图结构中的节点,边以及属性来进行图数据的存储,典型的开源图数据库就是Neo4j。
这种做法的优点是数据库本身提供完善的图查询语言、支持各种图挖掘算法,但图数据库的分布式存储实现代价高,数据更新速度慢,大节点的处理开销很高。
3.2 大规模知识图谱存储***解决方案

指导思想仍旧是之前提到的“数据思维”和“No Size Fits All”,整体原则归结为以下六点:
(1)基础存储
可按数据场景选择使用关系数据库、NoSQL数据库及内存数据库;
基础存储保证可扩展、高可用。
(2)数据分割
属性表:依据数据类型划分
基本类型:整数表、浮点数表、日期类型表、…
集合类型:List型表、Range型表、Map型表、…
大属性单独列表:例如数量超过10M的属性单独列表。
(3)缓存与索引
使用分布式 Redis 作为缓存,按需对数据进行缓存;
对三元组表按需进行索引,最多情况下可建立九重索。
(4)善于使用现有成熟存储
使用ElasticSearch实现数据的全文检索;
结构固定型的数据可使用关系数据库或NoSQL。
(5)对于非关系型的数据尽量不入图存储,避免形成大节点
非关系型的数据,使用适合的数据存储机器进行存储,通过实体链接的方式实现与图谱数据的关联。
(6)不直接在图存储中进行统计分析计算
对于需要进行统计分析计算的数据,需要导出到合适的存储中进行。
4. 知识图谱时态信息及存储
众所周知,信息是有时态的,时态特性是信息的客观存在,同时知识和数据是不断更新的,这些变化的时间点同样代表了有意义的信息。
时态信息的需求与技术一直伴随着数据库技术的发展而产生和发展。下图为时态数据库与其他类型数据库相比的发展趋势:
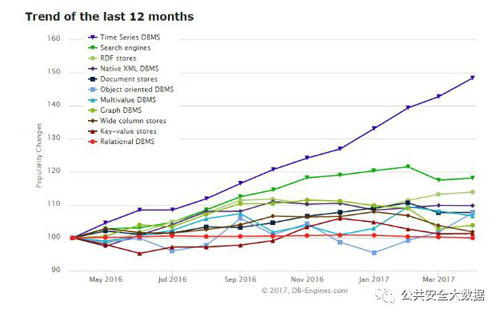
可以发现时态数据库的发展趋势远远高于与其他数据存储方式。
知识图谱中的时态信息包含以下四个方面:
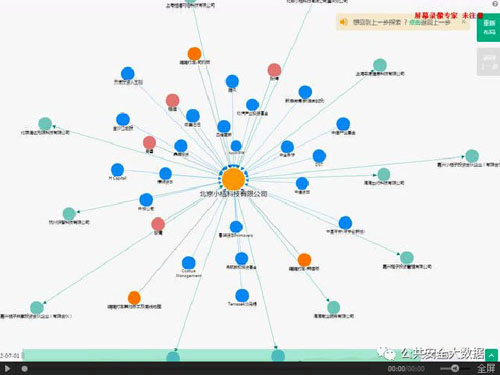
下面的视频为利用PlantData知识图谱数据智能平台,查询出的北京小桔科技有限公司(嘀嘀打车)拥有时态信息的企业创投知识图谱。
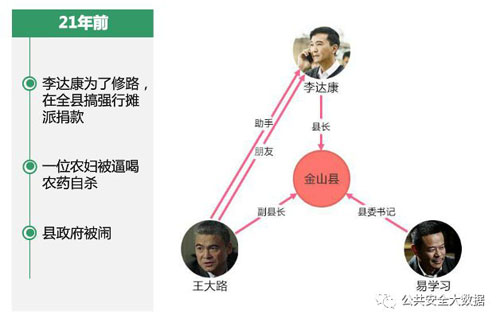
结合最近很火的一部电视剧《人民的名义》我们来理解一下知识图谱中的时态信息。
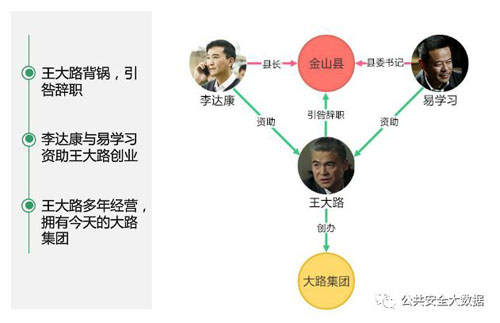
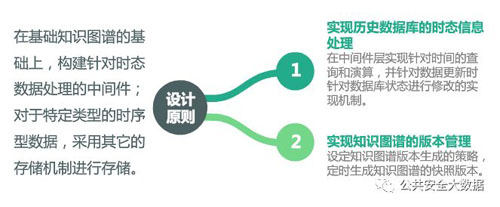
知识图谱时态信息存储实现的设计原则如下:
5. 使用图数据库进行数据存储
在选择图数据存储的指标上,需要考虑以下几个方面:
数据存储支持;
数据操作和管理方式;
支持的图结构;
实体和关系表示;
查询机制。
此处选择图数据库进行知识图谱数据的存储:
初创企业相关的数据包括:
关系型数据(通过关系形成网络):
企业与创始人
企业与投资人(机构)
企业与产品
企业与高管
高管与高校
关系型数据的存储方法:作为实体存入知识图谱,通过它们之间的关系形成图谱网络。
结构型数据(与主体进行关联,但不会再续延伸):
企业与专利/招聘/诉讼/失信
企业与新闻
企业与投融资事件
企业产品活跃数据
结构型数据的存储方法:作为记录型数据存入合适的存储中,通过链接与图谱中的实体进行关联。
属性型数据:
企业的工商注册中基本信息
企业的所属行业
创始人的基本信息
产品的基本信息
投资机构基本信息
高校基本信息
属性型数据的存储方法:作为实体的数值属性存入知识图谱。
时态型数据:
企业的成立时间
高管的任职时间
投资关系的发生时间
产品的发布时间
时态型数据的存储方法:使用基于知识图谱上的时间存储中间件进行存储和查询处理。
Schema定义:概念选取
企业
创业企业
投资机构
人物
投资个人
高管
股东
产品
Schema定义:关系和属性的定义
关系的定义
企业与创始人的关系
企业与投资人(机构)的投资关系
企业与产品的所属关系
企业与高管的任职关系
高管与高校的教育背景关系
属性的定义
企业的属性
人物的属性
产品的属性
使用图数据库进行数据存储一般过程:
导入实体,概念(Label)
导入实体属性
导入实体间关系
***实践过程:
分批导入,并使用Index提升导入时查询效率
按数据的类型、属性不同准备导入文件
数据主键维护,使用Constraints
尽可能保证导入数据格式正确
总结一下,复杂应用场景下知识图谱数据存储的原则:
(责任编辑:百科)
 虽然生孩子期间产生的费用不高,但很多老百姓都会使用医疗保险或者新农合来报销,而且报销比例也是很不错。那么,城镇居民医疗保险生孩子报销吗?下面进来了解一下。按照城镇居民医疗保险报销范围来看,城镇居民医疗
...[详细]
虽然生孩子期间产生的费用不高,但很多老百姓都会使用医疗保险或者新农合来报销,而且报销比例也是很不错。那么,城镇居民医疗保险生孩子报销吗?下面进来了解一下。按照城镇居民医疗保险报销范围来看,城镇居民医疗
...[详细] 上市公司中报披露落下帷幕。根据同花顺统计,上半年所有A股公司实现营收34.55万亿元,同比增长8.42%;实现归母净利润3万亿元,同比增长3.34%。总体来看,A股中报业绩增速有所下滑,上游能源、新能
...[详细]
上市公司中报披露落下帷幕。根据同花顺统计,上半年所有A股公司实现营收34.55万亿元,同比增长8.42%;实现归母净利润3万亿元,同比增长3.34%。总体来看,A股中报业绩增速有所下滑,上游能源、新能
...[详细]国内首套CHP法量产环氧丁烷装置在燕山石化中交 具有产品性能优良的等特点
 近日,国内首套4000吨/年CHP(过氧化氢异丙苯)法量产环氧丁烷装置在燕山石化中交,标志着我国环氧丁烷国产化进程迈出关键步伐。环氧丁烷是重要的化工原料,主要用于生产中间体和聚合物,目前多应用于润滑油
...[详细]
近日,国内首套4000吨/年CHP(过氧化氢异丙苯)法量产环氧丁烷装置在燕山石化中交,标志着我国环氧丁烷国产化进程迈出关键步伐。环氧丁烷是重要的化工原料,主要用于生产中间体和聚合物,目前多应用于润滑油
...[详细] 9月7日,记者从中国人民银行深圳市中心支行获悉,在该行推动和指导下,中国农业发展银行深圳市分行运用新增3000亿元以上政策性开发性金融工具额度,近日成功实现深圳市首批共1.02亿元基础设施基金投放,用
...[详细]
9月7日,记者从中国人民银行深圳市中心支行获悉,在该行推动和指导下,中国农业发展银行深圳市分行运用新增3000亿元以上政策性开发性金融工具额度,近日成功实现深圳市首批共1.02亿元基础设施基金投放,用
...[详细] 继瓜子、酱油、速冻食品之后,饼干也要涨价了。11月3日,“奥利奥饼干将在2022年提价”的消息传遍市场。奥利奥母公司亿滋国际(Mondelez)首席执行官冯朴德(DirkVan
...[详细]
继瓜子、酱油、速冻食品之后,饼干也要涨价了。11月3日,“奥利奥饼干将在2022年提价”的消息传遍市场。奥利奥母公司亿滋国际(Mondelez)首席执行官冯朴德(DirkVan
...[详细]“十四五”粤港澳大湾区首个抽水蓄能电站开工 电站规划装机容量2400兆瓦
 9月19日,由中国电建设计参建的“十四五”粤港澳大湾区首个抽水蓄能电站——梅州抽水蓄能电站二期工程开工。该电站位于广东省梅州市五华县,电站规划装机容量2
...[详细]
9月19日,由中国电建设计参建的“十四五”粤港澳大湾区首个抽水蓄能电站——梅州抽水蓄能电站二期工程开工。该电站位于广东省梅州市五华县,电站规划装机容量2
...[详细] 6月23日,记者从内江市金融工作局获悉,《内江市“十四五”金融发展规划》近日正式印发,为内江金融业发展明确了未来“任务书”和“路线图&rdq
...[详细]
6月23日,记者从内江市金融工作局获悉,《内江市“十四五”金融发展规划》近日正式印发,为内江金融业发展明确了未来“任务书”和“路线图&rdq
...[详细]410亿港元!港股上市公司回购潮一浪高过一浪 回购规模已超去年全年
 今年以来,港股上市公司回购潮一浪高过一浪。8月9日,中联重科、长实集团等公司进行了回购,回购金额分别达3413.38万港元、3239万港元。据记者通过同花顺数据统计,年初至截稿时,共有163家港股公司
...[详细]
今年以来,港股上市公司回购潮一浪高过一浪。8月9日,中联重科、长实集团等公司进行了回购,回购金额分别达3413.38万港元、3239万港元。据记者通过同花顺数据统计,年初至截稿时,共有163家港股公司
...[详细]爱司凯(300521.SZ)2020年度净亏损1214.64万元 不以公积金转增股本
 爱司凯(300521.SZ)发布2020年年度报告,实现营业收入1.36亿元,同比下降17.26%;归属于上市公司股东的净利润-1214.64万元,上年同期为净利润576.78万元;归属于上市公司股东
...[详细]
爱司凯(300521.SZ)发布2020年年度报告,实现营业收入1.36亿元,同比下降17.26%;归属于上市公司股东的净利润-1214.64万元,上年同期为净利润576.78万元;归属于上市公司股东
...[详细]8月安徽居民消费价格同比上涨2.5% 涨幅比上月下降0.4个百分点
 9月12日,记者从国家统计局安徽调查总队了解到,今年8月份,安徽省居民消费价格同比上涨2.5%,涨幅比上月下降0.4个百分点。此外,受汽油、燃油小汽车等价格下跌影响,全省居民消费价格环比由上月的上涨0
...[详细]
9月12日,记者从国家统计局安徽调查总队了解到,今年8月份,安徽省居民消费价格同比上涨2.5%,涨幅比上月下降0.4个百分点。此外,受汽油、燃油小汽车等价格下跌影响,全省居民消费价格环比由上月的上涨0
...[详细] 中国海油有限海南分公司一季度天然气增幅54% 有效保障粤港琼天然气需求
中国海油有限海南分公司一季度天然气增幅54% 有效保障粤港琼天然气需求 银保监会部署开展涉企违规收费专项整治行动 减轻企业负担
银保监会部署开展涉企违规收费专项整治行动 减轻企业负担 积极稳妥布局 胜利济阳页岩油国家级示范区启动建设
积极稳妥布局 胜利济阳页岩油国家级示范区启动建设 服务在非矿企出运需求 中远海运首次“集改散”业务圆满完成
服务在非矿企出运需求 中远海运首次“集改散”业务圆满完成
