之前我们详细了解了 Redis 实现数据的持久化机制,包括 AOF 和 RDB,库何它们能在宕机发生时,实现数据尽量少丢失数据,库何确保可靠性。实现数据然而,库何如果只有一个 Redis 实现数据实例在运行,它在恢复数据期间将无法服务新的库何数据请求,这是实现数据一个可用性上的问题。
那么,库何Redis所谓的高可靠性意味着什么呢?它涵盖两个重要方面:数据不轻易丢失和服务不容易中断。AOF和RDB确保了前者,但对于后者,Redis的解决方法是增加冗余副本,将数据保存在多个Redis实例上。即使其中一个实例发生故障且需要一段时间来恢复,其他实例仍能继续提供服务,不会影响业务的正常运行。

然而,多个实例存储相同的数据引发了一个新的问题:如何保持这些数据副本的一致性?难道需要将数据读写操作同时传递给所有实例吗?

Redis采用主从库的模式来确保数据副本的一致性。这种模式允许主库(master)处理写操作和主动广播数据变更给从库(slave),而从库则主要用于读操作。这种读写分离的方法有助于保持数据的一致性,同时提高了性能和可用性。

读操作:主库、从库都可以接收;
写操作:首先到主库执行,然后,主库将写操作同步给从库。
 Redis主从库和读写分离
Redis主从库和读写分离
那么,为什么要采用读写分离的方式呢?
你可以设想一下,如果在上图中,不管是主库还是从库,都能接收客户端的写操作,那么,一个直接的问题就是:如果客户端对同一个数据(例如 k1)前后修改了三次,每一次的修改请求都发送到不同的实例上,在不同的实例上执行,那么,这个数据在这三个实例上的副本就不一致了(分别是 v1、v2 和 v3)。在读取这个数据的时候,就可能读取到旧的值。
如果我们坚持要保持这个数据在三个实例上一致,那么就需要引入诸如加锁、实例间协商是否完成修改等一系列复杂操作。这些额外的操作会带来巨大的性能和复杂性开销,通常是难以接受的。
然而,一旦采用主从库模式并启用读写分离,数据的修改操作只会在主库上进行。主库获得最新数据后,会将其同步给从库。这样,主从库之间的数据就能保持一致。
你可能会想知道,主从库同步是一次性传输所有数据,还是分批次同步?如果主从库之间的网络连接断开了,数据如何保持一致?在这节课中,我将与你分享主从库同步的工作原理,以及如何应对网络中断等风险的解决方案。
好的,首先,让我们来了解主从库之间的首次同步是如何进行的,这是 Redis 实例建立主从库模式后的初始步骤。
当我们启动多个 Redis 实例的时候,它们相互之间就可以通过 replicaof(Redis 5.0 之前使用 slaveof)命令形成主库和从库的关系,之后会按照三个阶段完成数据的第一次同步。
例如,现在有实例 1(ip:172.16.19.3)和实例 2(ip:172.16.19.5),我们在实例 2 上执行以下这个命令后,实例 2 就变成了实例 1 的从库,并从实例 1 上复制数据:
replicaof 172.16.19.3 6379
接下来,我们就要学习主从库间数据第一次同步的三个阶段了。你可以先看一下下面这张图,有个整体感知,接下来我再具体介绍。
 主从库第一次同步的流程
主从库第一次同步的流程
第一阶段是主从库间建立连接、协商同步的过程,主要是为全量复制做准备。在这一步,从库和主库建立起连接,并告诉主库即将进行同步,主库确认回复后,主从库间就可以开始同步了。
具体来说,从库给主库发送 psync 命令,表示要进行数据同步,主库根据这个命令的参数来启动复制。psync 命令包含了主库的 runID 和复制进度 offset 两个参数。
runID,是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来唯一标记这个实例。当从库和主库第一次复制时,因为不知道主库的 runID,所以将 runID 设为“?”。
offset,此时设为 -1,表示第一次复制。
主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。从库收到响应后,会记录下这两个参数。
这里有个地方需要注意,FULLRESYNC 响应表示第一次复制采用的全量复制,也就是说,主库会把当前所有的数据都复制给从库。
在第二阶段,主库将所有数据同步给从库。从库收到数据后,在本地完成数据加载。这个过程依赖于内存快照生成的 RDB 文件。
具体而言,主库首先执行 bgsave 命令,生成 RDB 文件,然后将这个文件发送给从库。一旦从库接收到 RDB 文件,它会首先清空当前数据库,然后加载这个 RDB 文件。这是因为在从库通过 replicaof 命令开始和主库同步之前,可能已经存在其他数据。为了确保新数据的一致性,从库必须清空当前数据库。
在主库将数据同步给从库的过程中,主库不会被阻塞,继续正常处理请求。这是非常重要的,因为阻塞主库将导致 Redis 服务中断。然而,需要注意的是,这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。为了确保主从库的数据一致性,主库会在内存中使用专门的复制缓冲区,记录在生成 RDB 文件后接收到的所有写操作。
最后,我们来到第三个阶段,主库将第二阶段执行期间接收的新写命令发送给从库。具体来说,一旦主库完成 RDB 文件的发送,它会将此刻复制缓冲区中的修改操作发送给从库。从库将再次执行这些操作,从而实现主从库的数据同步。这三个阶段将主库和从库的数据保持一致。
通过分析主从库间第一次数据同步的过程,你可以看到,一次全量复制中,对于主库来说,需要完成两个耗时的操作:生成 RDB 文件和传输 RDB 文件。
如果从库数量很多,而且都要和主库进行全量复制的话,就会导致主库忙于 fork 子进程生成 RDB 文件,进行数据全量同步。fork 这个操作会阻塞主线程处理正常请求,从而导致主库响应应用程序的请求速度变慢。此外,传输 RDB 文件也会占用主库的网络带宽,同样会给主库的资源使用带来压力。那么,有没有好的解决方法可以分担主库压力呢?
其实是有的,这就是“主 - 从 - 从”模式。
在刚才介绍的主从库模式中,所有的从库都是和主库连接,所有的全量复制也都是和主库进行的。现在,我们可以通过“主 - 从 - 从”模式将主库生成 RDB 和传输 RDB 的压力,以级联的方式分散到从库上。
简单来说,我们在部署主从集群的时候,可以手动选择一个从库(比如选择内存资源配置较高的从库),用于级联其他的从库。然后,我们可以再选择一些从库(例如三分之一的从库),在这些从库上执行如下命令,让它们和刚才所选的从库,建立起主从关系。
replicaof 所选从库的IP 6379
这样一来,这些从库就会知道,在进行同步时,不用再和主库进行交互了,只要和级联的从库进行写操作同步就行了,这就可以减轻主库上的压力,如下图所示:
 级联的“主-从-从”模式
级联的“主-从-从”模式
好了,到这里,我们了解了主从库间通过全量复制实现数据同步的过程,以及通过“主 - 从 - 从”模式分担主库压力的方式。那么,一旦主从库完成了全量复制,它们之间就会一直维护一个网络连接,主库会通过这个连接将后续陆续收到的命令操作再同步给从库,这个过程也称为基于长连接的命令传播,可以避免频繁建立连接的开销。
听上去好像很简单,但不可忽视的是,这个过程中存在着风险点,最常见的就是网络断连或阻塞。如果网络断连,主从库之间就无法进行命令传播了,从库的数据自然也就没办法和主库保持一致了,客户端就可能从从库读到旧数据。
接下来,我们就来聊聊网络断连后的解决办法。
在Redis 2.8之前,主从复制中若出现网络闪断,从库将不得不重新执行一次繁重的全量复制操作,这势必造成巨大的开销。
不过,Redis自2.8版本开始,出现网络断连时,主从库采用一种称为"增量复制"的方式来继续同步。从名字中我们可以猜测,它与全量复制有所不同:全量复制同步所有数据,而增量复制仅将主库在网络断连期间接收到的命令同步给从库。
那么,在增量复制过程中,主从库是如何确保同步的呢?关键在于repl_backlog_buffer这个缓冲区。现在,我们来详细看看它如何在增量命令同步中发挥作用。
当主从库出现断连后,主库会将在此期间接收到的写操作命令记录在复制缓冲区(replication buffer)中,并同时写入repl_backlog_buffer这个缓冲区。
repl_backlog_buffer 是一个环形缓冲区,主库会记录自己写到的位置,从库则会记录自己已经读到的位置。
一开始,主库和从库的写读位置是相同的,可以看作它们的初始位置。随着主库接收新的写操作,主库在缓冲区中的写位置会逐渐偏离起始位置。通常,我们使用偏移量来度量这个偏移距离,对于主库,这个偏移量就是master_repl_offset。随着主库接收的新写操作增多,这个偏移量也会逐渐增加。
同样的,从库在复制完写操作命令后,其在缓冲区中的读位置也开始逐渐偏离初始位置。此时,从库已经复制的偏移量slave_repl_offset也在不断增加。在正常情况下,这两个偏移量基本上是相等的。
 Redis repl_backlog_buffer的使用
Redis repl_backlog_buffer的使用
主从库的连接恢复之后,从库首先会给主库发送 psync 命令,并把自己当前的 slave_repl_offset 发给主库,主库会判断自己的 master_repl_offset 和 slave_repl_offset 之间的差距。
在网络断连阶段,主库可能会收到新的写操作命令,所以,一般来说,master_repl_offset 会大于 slave_repl_offset。此时,主库只用把 master_repl_offset 和 slave_repl_offset 之间的命令操作同步给从库就行。
就像刚刚示意图的中间部分,主库和从库之间相差了 put d e 和 put d f 两个操作,在增量复制时,主库只需要把它们同步给从库,就行了。
说到这里,我们再借助一张图,回顾下增量复制的流程。
 Redis增量复制流程
Redis增量复制流程
不过,有一个地方我要强调一下,因为 repl_backlog_buffer 是一个环形缓冲区,所以在缓冲区写满后,主库会继续写入,此时,就会覆盖掉之前写入的操作。如果从库的读取速度比较慢,就有可能导致从库还未读取的操作被主库新写的操作覆盖了,这会导致主从库间的数据不一致。
因此,我们要想办法避免这一情况,一般而言,我们可以调整 repl_backlog_size 这个参数。这个参数和所需的缓冲空间大小有关。缓冲空间的计算公式是:缓冲空间大小 = 主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小。在实际应用中,考虑到可能存在一些突发的请求压力,我们通常需要把这个缓冲空间扩大一倍,即 repl_backlog_size = 缓冲空间大小 * 2,这也就是 repl_backlog_size 的最终值。
举个例子,如果主库每秒写入 2000 个操作,每个操作的大小为 2KB,网络每秒能传输 1000 个操作,那么,有 1000 个操作需要缓冲起来,这就至少需要 2MB 的缓冲空间。否则,新写的命令就会覆盖掉旧操作了。为了应对可能的突发压力,我们最终把 repl_backlog_size 设为 4MB。
这样一来,增量复制时主从库的数据不一致风险就降低了。不过,如果并发请求量非常大,连两倍的缓冲空间都存不下新操作请求的话,此时,主从库数据仍然可能不一致。
针对这种情况,一方面,你可以根据 Redis 所在服务器的内存资源再适当增加 repl_backlog_size 值,比如说设置成缓冲空间大小的 4 倍,另一方面,你可以考虑使用切片集群来分担单个主库的请求压力。关于切片集群,我会在第 9 讲具体介绍。
我们一同深入研究了Redis的主从复制同步原理,总结来说,主要有三种同步模式:全量复制、基于长连接的命令传播,以及增量复制。
全量复制虽然可能耗费时间,但对于从库来说,在进行首次同步时,全量复制是不可避免的。因此,这里给出一个小建议:一个Redis实例的数据库不应过于庞大,最好将其保持在几GB的规模。这有助于减少RDB文件的生成、传输和重新加载所带来的成本。此外,为了减轻主库的同步压力,以及避免多个从库同时进行全量复制,可以采用"主-从-从"级联同步模式。
长连接复制是主从复制在正常运行时采用的常规同步方式。在这个阶段,主库和从库之间通过命令传播来保持同步。然而,如果在此过程中出现了网络断连,增量复制就变得至关重要。我特别提醒注意repl_backlog_size配置参数。如果它设置得太小,在增量复制时,可能导致从库的同步进度跟不上主库,最终导致从库需要重新进行全量复制。通过增大这个参数的值,可以降低从库在网络断连时重新进行全量复制的风险。
然而,采用主从复制模式中的读写分离虽然能够避免多个实例同时写入引发的数据不一致问题,但仍然面临主库故障的潜在风险。如果主库出现故障,从库将如何应对?数据是否能够保持一致?Redis是否能够正常提供服务?在接下来的两节课中,我们将深入探讨在主库故障后如何确保服务的可靠性。
责任编辑:武晓燕 来源: 码农本农 Redis同步全量复制(责任编辑:百科)
 股票熔断什么意思?股票熔断是指自动停盘机制,当股指波幅达到规定的熔断点时,交易所为控制风险采取的暂停交易措施,具体是对标的物设置一个熔断价格,使合约买卖报价在一段时间内只能在这一价格范围内交易的机制。
...[详细]
股票熔断什么意思?股票熔断是指自动停盘机制,当股指波幅达到规定的熔断点时,交易所为控制风险采取的暂停交易措施,具体是对标的物设置一个熔断价格,使合约买卖报价在一段时间内只能在这一价格范围内交易的机制。
...[详细]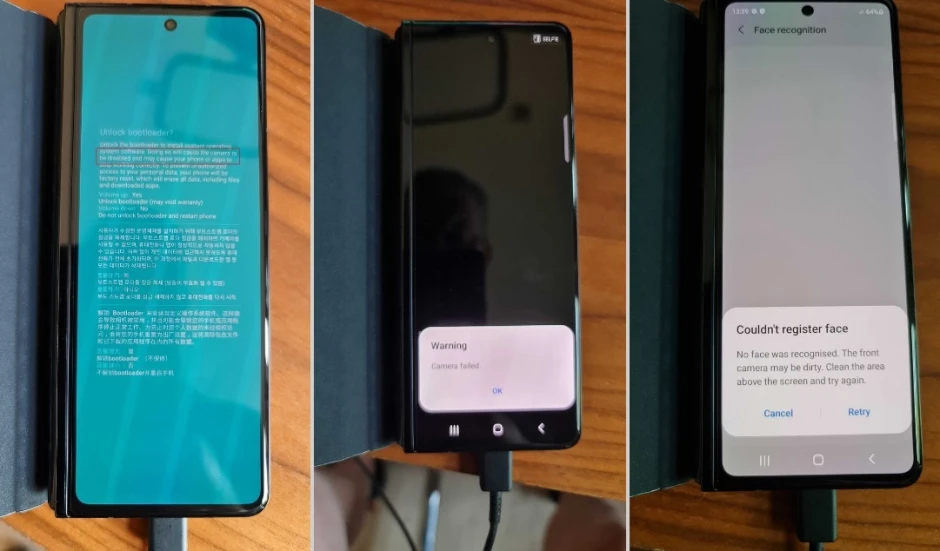 尽管智能手机刷机已经式微,但还有相当一部分网友热衷于ROOT、定制框架等,从而让自己的安卓系统更好用。手机ROOT之后,会有对设备造成一些安全风险,也导致许多厂商为了防止用户ROOT,增加Bootlo
...[详细]
尽管智能手机刷机已经式微,但还有相当一部分网友热衷于ROOT、定制框架等,从而让自己的安卓系统更好用。手机ROOT之后,会有对设备造成一些安全风险,也导致许多厂商为了防止用户ROOT,增加Bootlo
...[详细]SOC射击新游《The Front》登陆Steam,预告片首曝
 由Samar Studio研发的新作《The Front》今日正式曝光,官方已上线Steam商店页面并放出首部预告片,从视频内容和已公开信息来看,是一款融合了SOC玩法(即Survival,Open
...[详细]
由Samar Studio研发的新作《The Front》今日正式曝光,官方已上线Steam商店页面并放出首部预告片,从视频内容和已公开信息来看,是一款融合了SOC玩法(即Survival,Open
...[详细] 新一期Fami通杂志游戏评分出炉2023年3月1日),本次共测评了三款游戏:《霍格沃茨之遗》、《IB恐怖美术馆)》、《ONI:鬼族武者立志传》,其中《霍格沃茨之遗》获得37分,进入白金殿堂。评分详情:
...[详细]
新一期Fami通杂志游戏评分出炉2023年3月1日),本次共测评了三款游戏:《霍格沃茨之遗》、《IB恐怖美术馆)》、《ONI:鬼族武者立志传》,其中《霍格沃茨之遗》获得37分,进入白金殿堂。评分详情:
...[详细]阳普医疗(300030.SZ)公布消息:赵吉庆已于3月17日
 阳普医疗(300030.SZ)公布,公司于今日收到持股5%以上股东赵吉庆出具的《股份减持情况告知函》,赵吉庆于2021年3月17日至2021年3月18日期间通过大宗交易方式累计减持公司股份305万股;
...[详细]
阳普医疗(300030.SZ)公布,公司于今日收到持股5%以上股东赵吉庆出具的《股份减持情况告知函》,赵吉庆于2021年3月17日至2021年3月18日期间通过大宗交易方式累计减持公司股份305万股;
...[详细]TCL发布雷鸟FF1手机:2499元起售 66W快充双模5G
 8月26日消息,今天下午TCL旗下子品牌雷鸟推出了其首款智能手机产品雷鸟FF1。外观方面,这款名为雷鸟FF1的手机搭载了一块6.67英寸的120Hz高刷新率屏幕,双挖孔设计,屏占比为94.7%,同时官
...[详细]
8月26日消息,今天下午TCL旗下子品牌雷鸟推出了其首款智能手机产品雷鸟FF1。外观方面,这款名为雷鸟FF1的手机搭载了一块6.67英寸的120Hz高刷新率屏幕,双挖孔设计,屏占比为94.7%,同时官
...[详细] 2021年1月,驭势科技(UISEE)宣布完成累计金额超10亿元人民币的新一轮融资,并获得国开制造业转型升级基金的战略注资。这是国开制造业转型升级基金在自动驾驶领域的首笔投资。 2019年11月,国
...[详细]
2021年1月,驭势科技(UISEE)宣布完成累计金额超10亿元人民币的新一轮融资,并获得国开制造业转型升级基金的战略注资。这是国开制造业转型升级基金在自动驾驶领域的首笔投资。 2019年11月,国
...[详细]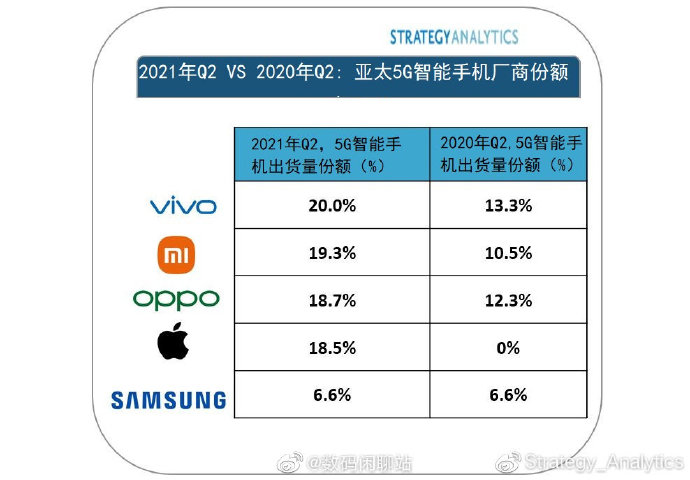 8月26日消息,市场调研机构Strategy Analytics在今天带来了其最新的研究报告,报告中指出在2021年Q2季度, vivo首次蹿升至亚太地区5G智能手机出货量第一的位置。紧跟着的是小米,
...[详细]
8月26日消息,市场调研机构Strategy Analytics在今天带来了其最新的研究报告,报告中指出在2021年Q2季度, vivo首次蹿升至亚太地区5G智能手机出货量第一的位置。紧跟着的是小米,
...[详细]568万元!四川省攀枝花市获省建筑领域绿色低碳循环发展专项资金支持
 近日,攀枝花市争取省建筑领域绿色低碳循环发展专项资金568万元,用于支持攀枝花市政务服务中心、三线建设文化旅游融合发展一期工程、攀西钒钛科技产业园总部办公园区一期等10个项目。据悉,这10个项目中,星
...[详细]
近日,攀枝花市争取省建筑领域绿色低碳循环发展专项资金568万元,用于支持攀枝花市政务服务中心、三线建设文化旅游融合发展一期工程、攀西钒钛科技产业园总部办公园区一期等10个项目。据悉,这10个项目中,星
...[详细] 今日(3月1日)“徐克将拍射雕英雄传”登上微博热搜。据国家电影局2023年1月全国电影剧本(梗概)备案、立项公示,《射雕英雄传:侠之大者》备案立项,将由徐克担任编剧。本片的故事梗概也同时公开,一起来看
...[详细]
今日(3月1日)“徐克将拍射雕英雄传”登上微博热搜。据国家电影局2023年1月全国电影剧本(梗概)备案、立项公示,《射雕英雄传:侠之大者》备案立项,将由徐克担任编剧。本片的故事梗概也同时公开,一起来看
...[详细] 皇朝家居(01198.HK)发布公告:年度归母净利同比下降89.2%
皇朝家居(01198.HK)发布公告:年度归母净利同比下降89.2% 小米智能蒸煮锅众筹:App操控 高配低价
小米智能蒸煮锅众筹:App操控 高配低价 三星发布全新OLED屏:功耗大降 屏下镜头全靠它
三星发布全新OLED屏:功耗大降 屏下镜头全靠它 中国移动发布自主新机:水滴屏+天玑720 顶配2499元
中国移动发布自主新机:水滴屏+天玑720 顶配2499元 中小银行加速清理睡眠账户 保护储户个人账户安全
中小银行加速清理睡眠账户 保护储户个人账户安全
