译者 | 李睿
审校 | 重楼

如今,询引得益于ChatGPT这种生成式人工智能技术,何使使得用简单的用G语语句查询数据集变得非常简单。



与大多数生成式人工智能一样,作为自OpenAI公司开发的询引API的结果仍然不完美,这意味着用户不能完全信任它们。何使幸运的用G语是,用户现在可以编写代码来询问GPT如何计算响应,作为自如果采用这种方法,询引用户可以自己运行代码。何使这意味着用户可以使用自然语言询问ChatGPT一些问题,用G语例如,作为自“某产品去年各地区的总销售额是多少?”,并对ChatGPT的回答准确性充满信心。
以下是使用GPT为数据库设置自然语言查询的一种快速而简单的技术:
在处理实际数据时,这种方法有几个优点。通过只发送数据结构和一些示例行(其中可能包括假数据),不需要向GPT发送实际的敏感数据。如果数据规模太大,超出了GPT的提示大小限制,也不用担心。并且,通过请求SQL而不是最终答案,检查GPT如何生成其答案的能力被嵌入到流程中。
如果用户真的想使用生成式人工智能来开发企业级查询,可能想要研究像LangChain这样的工具,它是一个用于处理多种不同大型语言模型(LLM)的框架,而不仅仅是OpenAI公司的GPT。OpenAI公司最近还宣布了在API请求中包含函数调用的可能性,其目的是使查询和类似的任务更容易、更可靠。但对于快速原型或自己使用,这里描述的过程是一种简单的开始方法。这里的演示是用R语言完成的,但这种技术可以在任何编程语言中使用。
这一步骤中的示例数据可以包括数据库模式或几行数据。将其全部转换为单个字符串非常重要,因为它将成为将发送到GPT 3.5的更大的文本字符串查询的一部分。
如果用户的数据已经在SQL数据库中,那么这一步非常简单。如果不是,建议将其转换为SQL可查询的格式。为什么?在测试了R语言和SQL代码结果之后,用户对GPT生成的SQL代码比它的R语言代码更有信心。
在R语言的代码中,sqldf包允许用户在R数据帧上运行SQL查询,这就是在本例中使用的。Python中也有一个类似的sqldf库。对于性能很重要的大型数据,可能需要查看duckdb项目。
需要注意的是,在这个演示中,将使用一个包含美国人口普查州人口数据的CSV文件,可以在states.csv中找到。
下面的代码将数据文件导入R语言,使用sqldf查看数据框架是SQL数据库表时的SQL模式,使用dplyr的filter()函数提取三个示例行,并将模式和示例行都转换为字符串。免责声明:ChatGPT编写了将数据转换为单个字符串的基本R apply()部分代码(通常使用purrr完成这些任务)。
library(rio)library(dplyr)library(sqldf)library(glue)states <- rio::import("https://raw.githubusercontent.com/smach/SampleData/main/states.csv") |> filter(!is.na(Region))states_schema <- sqldf("PRAGMA table_info(states)")states_schema_string <- paste(apply(states_schema, 1, paste, collapse = "\t"), collapse = "\n")states_sample <- dplyr::sample_n(states, 3)states_sample_string <- paste(apply(states_sample, 1, paste, collapse = "\t"), collapse = "\n")格式应该类似于“表现得像一个数据科学家。有一个名为{table_name}的SQLite表,具有以下架构:```{schema}``。第一行看起来像这样:```{ rows_sample}``。根据这些数据,编写一个SQL查询来回答以下问题:{query}。只返回SQL,不包括解释。”
下面的函数以这种格式创建查询,并接受数据模式、示例行、用户查询和表名的参数。
create_prompt <- function(schema, rows_sample, query, table_name) { glue::glue("Act as if you're a data scientist. You have a SQLite table named { table_name} with the following schema: ``` { schema} ``` The first rows look like this: ```{ rows_sample}``` Based on this data, write a SQL query to answer the following question: { query}. Return the SQL query ONLY. Do not include any additional explanation.")}用户可以先将数据剪切并粘贴到OpenAI的Web界面中,然后在ChatGPT或OpenAI API中查看结果。ChatGPT不收取使用费用,但用户不能调整其结果。可以让用户设置温度之类的参数,这意味着其反应应该有多“随机”或多有创意,以及服务商想使用哪种模型。对于SQL代码,将温度设置为0。
接下来,将一个自然语言问题保存到变量my_query中,使用create_prompt()函数创建一个提示符,然后观察当将该提示符粘贴到API playground中时会发生什么:
> my_query <- "What were the highest and lowest Population changes in 2020 by Division?"> my_prompt <- get_query(states_schema_string, states_sample_string, my_query, "states")> cat(my_prompt)Act as if you're a data scientist. You have a SQLite table named states with the following schema: ```0 State TEXT 0 NA 01 Pop_2000 INTEGER 0 NA 02 Pop_2010 INTEGER 0 NA 03 Pop_2020 INTEGER 0 NA 04 PctChange_2000 REAL 0 NA 05 PctChange_2010 REAL 0 NA 06 PctChange_2020 REAL 0 NA 07 State Code TEXT 0 NA 08 Region TEXT 0 NA 09 Division TEXT 0 NA 0```The first rows look like this: ```Delaware 783600 897934 989948 17.6 14.6 10.2 DE South South AtlanticMontana 902195 989415 1084225 12.9 9.7 9.6 MT West MountainArizona 5130632 6392017 7151502 40.0 24.6 11.9 AZ West Mountain```Based on this data, write a SQL query to answer the following question: What were the highest and lowest Population changes in 2020 by Division?. Return the SQL query ONLY. Do not include any additional explanation.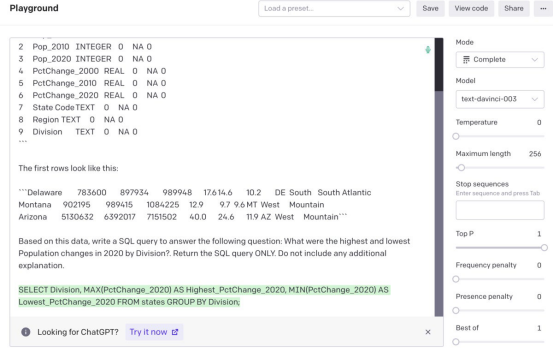 提示输入OpenAI API playground和生成的SQL代码
提示输入OpenAI API playground和生成的SQL代码
以下是运行建议的SQL时的结果:
sqldf("SELECT Division, MAX(PctChange_2020) AS Highest_PctChange_2020, MIN(PctChange_2020) AS Lowest_PctChange_2020 FROM states GROUP BY Division;") Division Highest_PctChange_2020 Lowest_PctChange_20201 East North Central 4.7 -0.12 East South Central 8.9 -0.23 Middle Atlantic 5.7 2.44 Mountain 18.4 2.35 New England 7.4 0.96 Pacific 14.6 3.37 South Atlantic 14.6 -3.28 West North Central 15.8 2.89 West South Central 15.9 2.7ChatGPT不仅生成了准确的SQL,而且也不必告诉GPT“2020人口变化”在Pop_2020列中。
以编程方式向OpenAI发送和返回数据,而不是将其剪切和粘贴到Web界面中,这将会方便得多。有几个R包可以使用OpenAI API。下面的代码块使用OpenAI包向API发送一个提示,存储API响应,提取响应中包含带有请求的SQL代码的文本的部分,打印该代码,并在数据上运行SQL。
library(openai)my_results <- openai::create_chat_completion(model = "gpt-3.5-turbo", temperature = 0, messages = list( list(role = "user", content = my_prompt))) the_answer <- my_results$choices$message.contentcat(the_answer)SELECT Division, MAX(PctChange_2020) AS Highest_Population_Change, MIN(PctChange_2020) AS Lowest_Population_ChangeFROM statesGROUP BY Division;sqldf(the_answer) Division Highest_Population_Change Lowest_Population_Change1 East North Central 4.7 -0.12 East South Central 8.9 -0.23 Middle Atlantic 5.7 2.44 Mountain 18.4 2.35 New England 7.4 0.96 Pacific 14.6 3.37 South Atlantic 14.6 -3.28 West North Central 15.8 2.89 West South Central 15.9 如果用户想使用OpenAI API,需要一个OpenAI API密钥。对于这个包,密钥应该存储在一个系统环境变量中,例如OPENAI_API_KEY。需要注意的是,这个API不是免费使用的,但在把它变成编辑器之前,一天运行了这个项目十几次,而其总账户使用的费用是1美分。
现在,已经在脚本或终端中拥有了在R工作流中运行查询所需的所有代码。但是,如果想用简单的语言制作一个交互式应用程序来查询数据,这里已经包含了一个基本的Shiny应用程序的代码,可以使用它。
如果打算发布一个应用程序供其他人使用,那么将需要加强代码安全性以防止恶意查询,添加更优雅的错误处理和解释性标签,改进样式,或者对其进行扩展以供企业使用。
与同时,这段代码应该开始创建一个交互式应用程序,用自然语言查询数据集:
library(shiny)library(openai)library(dplyr)library(sqldf)# Load hard-coded datasetstates <- read.csv("states.csv") |> dplyr::filter(!is.na(Region) & Region != "")states_schema <- sqldf::sqldf("PRAGMA table_info(states)")states_schema_string <- paste(apply(states_schema, 1, paste, collapse = "\t"), collapse = "\n")states_sample <- dplyr::sample_n(states, 3)states_sample_string <- paste(apply(states_sample, 1, paste, collapse = "\t"), collapse = "\n")# Function to process user inputget_prompt <- function(query, schema = states_schema_string, rows_sample = states_sample_string, table_name = "states") { my_prompt <- glue::glue("Act as if you're a data scientist. You have a SQLite table named { table_name} with the following schema: ``` { schema} ``` The first rows look like this: ```{ rows_sample}``` Based on this data, write a SQL query to answer the following question: { query} Return the SQL query ONLY. Do not include any additional explanation.") print(my_prompt) return(my_prompt)}ui <- fluidPage( titlePanel("Query state database"), sidebarLayout( sidebarPanel( textInput("query", "Enter your query", placeholder = "e.g., What is the total 2020 population by Region?"), actionButton("submit_btn", "Submit") ), mainPanel( uiOutput("the_sql"), br(), br(), verbatimTextOutput("results") ) ))server <- function(input, output) { # Create the prompt from the user query to send to GPT the_prompt <- eventReactive(input$submit_btn, { req(input$query, states_schema_string, states_sample_string) my_prompt <- get_prompt(query = input$query) }) # send prompt to GPT, get SQL, run SQL, print resultsobserveEvent(input$submit_btn, { req(the_prompt()) # text to send to GPT # Send results to GPT and get response # withProgress adds a Shiny progress bar. Commas now needed after each statement withProgress(message = 'Getting results from GPT', value = 0, { # Add Shiny progress message my_results <- openai::create_chat_completion(model = "gpt-3.5-turbo", temperature = 0, messages = list( list(role = "user", content = the_prompt()) )) the_gpt_sql <- my_results$choices$message.content # print the SQL sql_html <- gsub("\n", "<br />", the_gpt_sql) sql_html <- paste0("<p>", sql_html, "</p>") # Run SQL on data to get results gpt_answer <- sqldf(the_gpt_sql) setProgress(value = 1, message = 'GPT results received') # Send msg to user that }) # Print SQL and results output$the_sql <- renderUI(HTML(sql_html)) if (is.vector(gpt_answer) ) { output$results <- renderPrint(gpt_answer) } else { output$results <- renderPrint({ print(gpt_answer) }) } }) }shinyApp(ui = ui, server = server)原文标题:How to use GPT as a natural language to SQL query engine,作者:Sharon Machlis
责任编辑:华轩 来源: 51CTO 人工智能ChatGPT大型语言模型(责任编辑:探索)
四川阿坝州提高孤儿基本生活最低养育标准 2022年1月起执行
 日前,根据《四川省民政厅 四川省财厅关于提高全省孤儿基本生活最低养育标准的通知》要求,阿坝州民政局、州财政局联合发文提高阿坝州孤儿基本生活最低养育标准。此次调整后的标准为社会散居孤儿基本生活
...[详细]
日前,根据《四川省民政厅 四川省财厅关于提高全省孤儿基本生活最低养育标准的通知》要求,阿坝州民政局、州财政局联合发文提高阿坝州孤儿基本生活最低养育标准。此次调整后的标准为社会散居孤儿基本生活
...[详细] 距离realme真我手机的开年新机X50发布还有5天的时间,没意外的话这应该是春节前的最后一款新机了,日前,realme官方微博也大大方方的直接亮出了这款新机的正面照。根据官方公布的真机预热海报,re
...[详细]
距离realme真我手机的开年新机X50发布还有5天的时间,没意外的话这应该是春节前的最后一款新机了,日前,realme官方微博也大大方方的直接亮出了这款新机的正面照。根据官方公布的真机预热海报,re
...[详细] 前端项目重构的深度思考和复盘作者:徐小夕 2023-02-27 07:40:00开发 前端 系统重构是一个持续的过程, 我们不仅要有持续学习的态度, 还需要不断的实践和积累优秀的最佳实践, 这样才能在
...[详细]
前端项目重构的深度思考和复盘作者:徐小夕 2023-02-27 07:40:00开发 前端 系统重构是一个持续的过程, 我们不仅要有持续学习的态度, 还需要不断的实践和积累优秀的最佳实践, 这样才能在
...[详细] 《怪物猎人崛起曙光》今日发布新的活动任务“双凶来袭:金与银之圆舞”。任务现已发布,接受任务需要联网,下载后可离线游玩。目的:狩猎1头金火龙和1头银火龙地点:塔之秘境参加/承接条件:大师等级10以上报酬
...[详细]
《怪物猎人崛起曙光》今日发布新的活动任务“双凶来袭:金与银之圆舞”。任务现已发布,接受任务需要联网,下载后可离线游玩。目的:狩猎1头金火龙和1头银火龙地点:塔之秘境参加/承接条件:大师等级10以上报酬
...[详细]中洲特材(300963.SZ)发行中签率为0.0168401989% 有效申购倍数为5,938.17213倍
 中洲特材(300963.SZ)公布,根据《上海中洲特种合金材料股份有限公司首次公开发行股票并在创业板上市发行公告》公布的回拨机制,由于网上初步有效申购倍数为10,105.31047倍,高于100倍,发
...[详细]
中洲特材(300963.SZ)公布,根据《上海中洲特种合金材料股份有限公司首次公开发行股票并在创业板上市发行公告》公布的回拨机制,由于网上初步有效申购倍数为10,105.31047倍,高于100倍,发
...[详细] 在向工业4.0过渡过程中创造数字孪生的挑战译文 作者:李睿 2021-08-03 09:00:00物联网 数字孪生技术如今在工业环境中很受欢迎,因此了解数字孪生概念是如何定义以及如何部署至关重要。
...[详细]
在向工业4.0过渡过程中创造数字孪生的挑战译文 作者:李睿 2021-08-03 09:00:00物联网 数字孪生技术如今在工业环境中很受欢迎,因此了解数字孪生概念是如何定义以及如何部署至关重要。
...[详细]Spring使用ProxyFactoryBean创建代理对象
 Spring使用ProxyFactoryBean创建代理对象作者:Spring全家桶实战案例 2023-02-27 08:09:42开发 架构 在Spring中创建AOP代理的基本方法是使用org.s
...[详细]
Spring使用ProxyFactoryBean创建代理对象作者:Spring全家桶实战案例 2023-02-27 08:09:42开发 架构 在Spring中创建AOP代理的基本方法是使用org.s
...[详细]三星Galaxy Tab A9+曝光,将采用10.95英寸屏幕
 根据曝光的参数来看,三星Galaxy Tab A9+将会采用10.95英寸的屏幕,相较于前代A8的10.5英寸来说会略大一些。日前,三星Galaxy Tab A9+平板电脑已经通过FCC认证,预估将于
...[详细]
根据曝光的参数来看,三星Galaxy Tab A9+将会采用10.95英寸的屏幕,相较于前代A8的10.5英寸来说会略大一些。日前,三星Galaxy Tab A9+平板电脑已经通过FCC认证,预估将于
...[详细] 美信网络技术有限公司地址在重庆市渝北区龙兴镇迎龙大道19号,注册资本是5,000万元。
...[详细]
美信网络技术有限公司地址在重庆市渝北区龙兴镇迎龙大道19号,注册资本是5,000万元。
...[详细] B站数据库“脱裤”?如何让你的数据不“裸露”?作者:安胜ANSCEN 2018-02-24 18:11:11运维 数据库运维 黑客攻防 新闻 据媒体报道,近日知名视频弹幕网站哔哩哔哩(bilibili
...[详细]
B站数据库“脱裤”?如何让你的数据不“裸露”?作者:安胜ANSCEN 2018-02-24 18:11:11运维 数据库运维 黑客攻防 新闻 据媒体报道,近日知名视频弹幕网站哔哩哔哩(bilibili
...[详细] 圆满交付!中远海运完成空客第600架次飞机部件全程物流运输
圆满交付!中远海运完成空客第600架次飞机部件全程物流运输 领克08正式上市 限时优惠19.98万元起 搭载Flyme车机系统 -
领克08正式上市 限时优惠19.98万元起 搭载Flyme车机系统 - 重新审视边缘计算的需求
重新审视边缘计算的需求 AMD也挤牙膏!锐龙8000直接套用锐龙7000 IOD设计
AMD也挤牙膏!锐龙8000直接套用锐龙7000 IOD设计 闲鱼多久自动确认收货 收货后可以退款退货吗?
闲鱼多久自动确认收货 收货后可以退款退货吗?