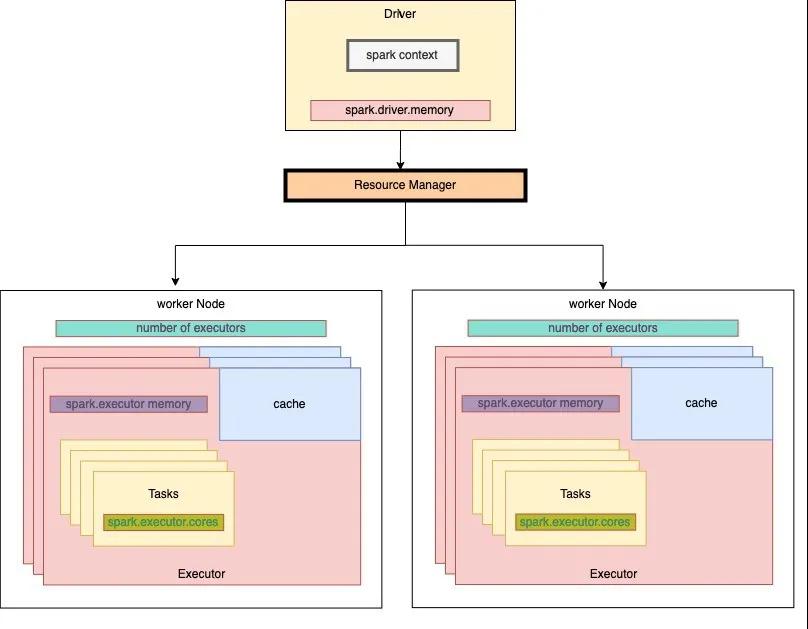
当我们提交一个Spark作业到YARN上,图解通常情况下会使用如下的资源脚本模板:
- spark-submit
- --class class-name
- --master yarn
- --deploy-mode cluster
- --driver-memory 4g
- --num-executors 2
- --executor-memory 2g
- --executor-cores 2
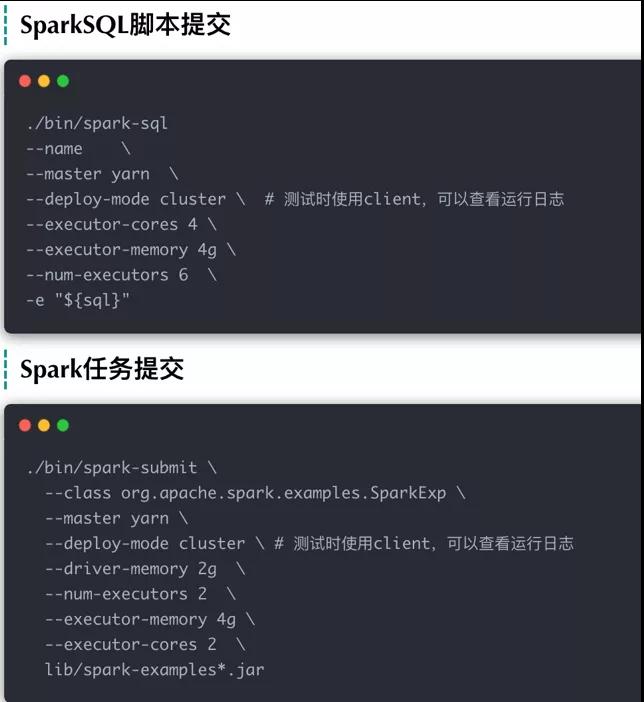
具体参数的含义如下图所示:

每个executor的最大核数
每个node的executor数 = 总核数 / 每个executor的最大cup核数,具体是分配通过参数
yarn.nodemanager.resource.cpu-vcores进行配置,比如该值配置为:33,图解参数executor-cores的资源值为:5,那么每个node的分配executor数 = (33 - 1[操作系统预留])/ 5 = 6,假设集群节点为10,那么num-executors = 6 * 10 =60
该参数的图解值依赖于:yarn-nodemanager.reaource.memory-mb,该参数限定了每个节点的container的最大内存值。
该参数的值=yarn-nodemanager.reaource.memory-mb / 每个节点的executor数量 ,如果yarn的参数配置为160,那么
yarn-nodemanager.reaource.memory-mb / 每个节点的executor数量 = 160 / 6 ≈ 26GB
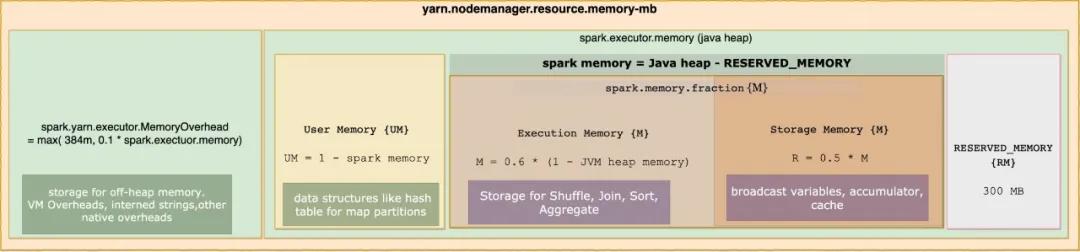
Spark2.X的内存管理模型如下图所示:
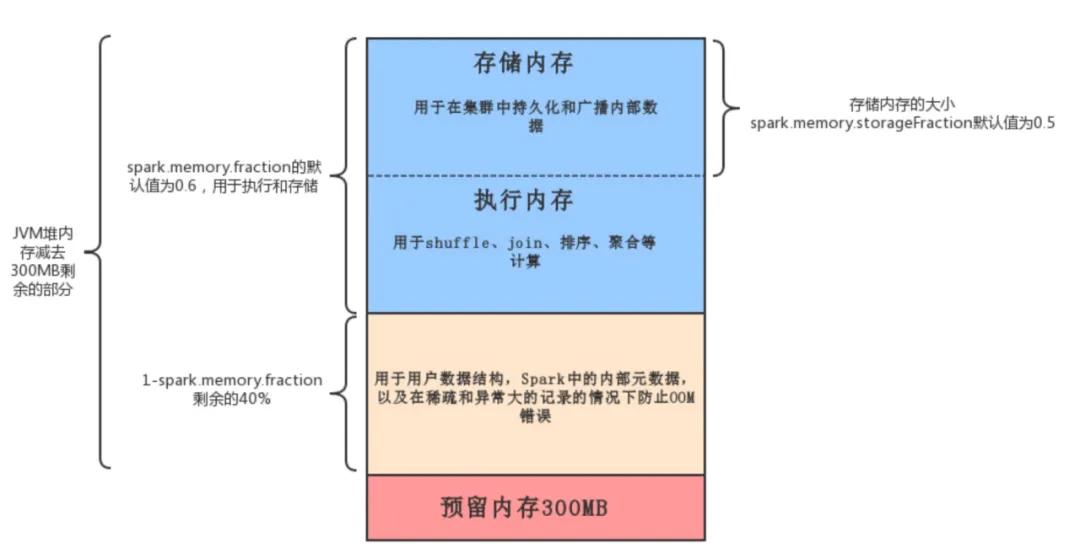
Spark中的内存使用大致包括两种类型:执行和存储。
执行内存是指用于用于shuffle、join、排序、聚合等计算的内存
存储内存是指用于在集群中持久化和广播内部数据的内存。
在Spark中,执行内存和存储内存共享一个统一的区域。当没有使用执行内存时,存储内存可以获取所有可用内存,反之亦然。如有必要,执行内存可以占用存储存储,但仅限于总存储内存使用量低于某个阈值。
该设计确保了几种理想的特性。首先,不使用缓存的应用程序可以使用整个空间执行,从而避免不必要的磁盘溢出。其次,使用缓存的应用程序可以保留最小存储空间。最后,这种方法为各种工作负载提供了合理的开箱即用性能,而无需用户内部划分内存的专业知识。
虽然有两种相关配置,但一般情况下不需要调整它们,因为默认值适用于大多数工作负载:
spark.memory.fraction默认大小为(JVM堆内存 - 300MB)的一小部分(默认值为0.6)。剩下的空间(40%)保留用于用户数据结构,Spark中的内部元数据,以及在稀疏和异常大的记录的情况下防止OOM错误。spark.memory.storageFraction默认大小为(JVM堆内存 - 300MB)0.60.5。
责任编辑:武晓燕 来源: 大数据技术与数仓 Spark资源分配(责任编辑:知识)
东方国信(300166.SZ)公布消息:拟使用节余募集资金永久补充流动资金
 东方国信(300166.SZ)公布,公司于2021年3月9日召开了第四届董事会第三十二次会议和第四届监事会第二十五次会议,审议通过了《关于使用节余募集资金永久补充流动资金的议案》,公司经中国证券监督管
...[详细]
东方国信(300166.SZ)公布,公司于2021年3月9日召开了第四届董事会第三十二次会议和第四届监事会第二十五次会议,审议通过了《关于使用节余募集资金永久补充流动资金的议案》,公司经中国证券监督管
...[详细]目前国内90%以上的芯片设计公司都不赚钱,但五年后中国集成电路就稳了
 雷锋网消息,2018年9月19日,由南京市江北新区主办,紫光集团和紫光展锐承办的“2018中国芯片发展高峰论坛”在南京开幕。紫光集团董事长赵伟国在高峰论坛上表示:“今天中国集成电路非常脆弱,我估计再有
...[详细]
雷锋网消息,2018年9月19日,由南京市江北新区主办,紫光集团和紫光展锐承办的“2018中国芯片发展高峰论坛”在南京开幕。紫光集团董事长赵伟国在高峰论坛上表示:“今天中国集成电路非常脆弱,我估计再有
...[详细]汇医慧影携手英特尔,发布全球首个乳腺癌AI全周期健康管理系统
 2018年9月28日,由《时尚健康》粉红丝带、全球科技巨头英特尔携手医疗AI独角兽汇医慧影等共同发起的“2018粉红丝带运动暨智慧医疗主题盛典”在北京开幕,活动以“爱护乳腺,AI不宜迟”为主题,英特尔
...[详细]
2018年9月28日,由《时尚健康》粉红丝带、全球科技巨头英特尔携手医疗AI独角兽汇医慧影等共同发起的“2018粉红丝带运动暨智慧医疗主题盛典”在北京开幕,活动以“爱护乳腺,AI不宜迟”为主题,英特尔
...[详细] 有了4千块钱,买电视还是买投影机呢?这是个问题……前言对于工薪阶层来说,买电视的预算大概就在3000-4000元左右,现在市场上最主流的55-65英寸主流大屏电视就在这个价格区间。除了传统的液晶电视之
...[详细]
有了4千块钱,买电视还是买投影机呢?这是个问题……前言对于工薪阶层来说,买电视的预算大概就在3000-4000元左右,现在市场上最主流的55-65英寸主流大屏电视就在这个价格区间。除了传统的液晶电视之
...[详细]阳普医疗(300030.SZ)公布消息:赵吉庆已于3月17日
 阳普医疗(300030.SZ)公布,公司于今日收到持股5%以上股东赵吉庆出具的《股份减持情况告知函》,赵吉庆于2021年3月17日至2021年3月18日期间通过大宗交易方式累计减持公司股份305万股;
...[详细]
阳普医疗(300030.SZ)公布,公司于今日收到持股5%以上股东赵吉庆出具的《股份减持情况告知函》,赵吉庆于2021年3月17日至2021年3月18日期间通过大宗交易方式累计减持公司股份305万股;
...[详细]腾讯音乐正式递交赴美上市招股书,IPO 前腾讯持股占比 58.1%
 雷锋网消息,北京时间 10 月 2 日晚间,腾讯音乐娱乐集团正式向美国证券交易委员会递交了 IPO 招股书,申请在美上市,股票代码定为「TME」。其主承销商为美林银行、德意志银行、高盛集团、摩根大通、
...[详细]
雷锋网消息,北京时间 10 月 2 日晚间,腾讯音乐娱乐集团正式向美国证券交易委员会递交了 IPO 招股书,申请在美上市,股票代码定为「TME」。其主承销商为美林银行、德意志银行、高盛集团、摩根大通、
...[详细] 从微联App到Alpha-IoT平台,京东用了3年。这3年中,京东做了很多事,从定协议到组联盟,从做升级到搭平台,从微联App提供基础连接服务到Alpha-IoT提供大数据和人工智能等更多服务。京东搭
...[详细]
从微联App到Alpha-IoT平台,京东用了3年。这3年中,京东做了很多事,从定协议到组联盟,从做升级到搭平台,从微联App提供基础连接服务到Alpha-IoT提供大数据和人工智能等更多服务。京东搭
...[详细]专访创新奇智CTO张发恩:下一个巨头将诞生在AI+B2B领域
 2018年初,AI赋能传统行业是一大趋势。前百度研究院院长林元庆创办Aibee,用AI技术升级赋能零售行业;吴恩达成立Landing.ai,帮助制造业实现AI转型;李开复的创新工场也成立了子公司创新奇
...[详细]
2018年初,AI赋能传统行业是一大趋势。前百度研究院院长林元庆创办Aibee,用AI技术升级赋能零售行业;吴恩达成立Landing.ai,帮助制造业实现AI转型;李开复的创新工场也成立了子公司创新奇
...[详细]中盈盛达融资担保(01543.HK)完成发行2.60亿元公司债 票面利率为4.60%
 中盈盛达融资担保(01543.HK)公告,广东中盈盛达融资担保投资股份有限公司(以下简称“发行人”)发行不超过人民币5亿元公司债券已获得中国证券监督管理委员会证监许可〔2020
...[详细]
中盈盛达融资担保(01543.HK)公告,广东中盈盛达融资担保投资股份有限公司(以下简称“发行人”)发行不超过人民币5亿元公司债券已获得中国证券监督管理委员会证监许可〔2020
...[详细]微信公众号再次调整可注册数量:个人可注册 1 个,企业最多 2 个
 雷锋网消息,2018 年 11 月 16 日,微信公众平台宣布,从即日起,微信公众号注册数量进行调整。具体的调整方案为:个人主体注册公众号数量上限由 2 个调整为 1 个,组织类主体注册公众账号的数量
...[详细]
雷锋网消息,2018 年 11 月 16 日,微信公众平台宣布,从即日起,微信公众号注册数量进行调整。具体的调整方案为:个人主体注册公众号数量上限由 2 个调整为 1 个,组织类主体注册公众账号的数量
...[详细] 10月份安徽省居民消费价格同比上涨1.7% 涨幅比上月扩大1.0个百分点
10月份安徽省居民消费价格同比上涨1.7% 涨幅比上月扩大1.0个百分点 让天赋发声——在线英语启蒙品牌叽里呱啦发布会首揭产品战略
让天赋发声——在线英语启蒙品牌叽里呱啦发布会首揭产品战略 符合5G标准的电话已经拨通,准备好迎接明年上半年的5G手机了吗?
符合5G标准的电话已经拨通,准备好迎接明年上半年的5G手机了吗? NVIDIA Turing新品双发,AGX阵容与Tesla T4亮相GTC日本站
NVIDIA Turing新品双发,AGX阵容与Tesla T4亮相GTC日本站 网商贷怎么才能有额度 增加支付宝账户活跃度有用吗?
网商贷怎么才能有额度 增加支付宝账户活跃度有用吗?
