本文转载自微信公众号「精益码农」,内存作者有态度的模型马甲。转载本文请联系精益码农公众号。到底
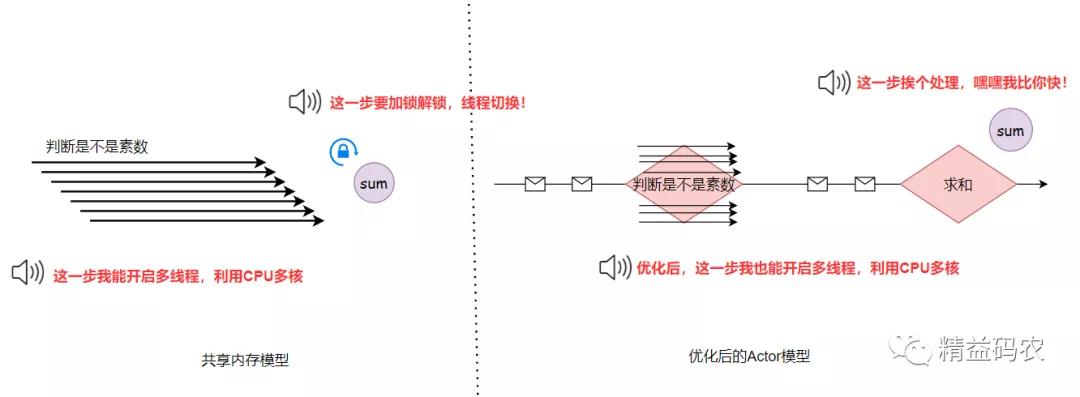
1.首先两者对于并发的共享个快风格模型不一样。

共享内存利用多核CPU的内存优势,使用强一致的模型锁机制控制并发, 各种锁交织,到底稍不注意可能出现死锁,共享个快更适合熟手。内存
Actor模型易于控制和管理,模型以消息触发、流水线挨个处理,天然分布式,思路清晰。
2.真要说性能,求100_000 以内的素数的个数]场景 & 电脑8c 16g的配置
下面请听我唠嗑。
计算[100_000内素数的个数], 分为两步:
(1) 迭代判断当前数字是不是素数
(2) 如果是素数,执行sum++
完成以上两步,共享内存模型均能充分利用CPU多核心。
Actor模型:与TPL中的原语不同,TPL Datflow中的所有块默认是单线程的,这就意味着完成以上两步的TransfromBlock和ActionBlock都是以一个线程挨个处理消息数据 (这也是Dataflow的设计初衷,形成清晰单纯的流水线)。
猜测此时:共享内存相比默认的Actor模型更具优势。
使用NUnit做单元测试,数据量从小到大: 10_000,50_000,100_000,200_000,300_000,500_000
- using NUnit.Framework;
- using System;
- using System.Threading.Tasks;
- using System.Collections.Generic;
- using System.Threading;
- using System.Threading.Tasks.Dataflow;
- namespace TestProject2
- {
- public class Tests
- {
- [TestCase(10_000)]
- [TestCase(50_000)]
- [TestCase(100_000)]
- [TestCase(200_000)]
- [TestCase(300_000)]
- [TestCase(500_000)]
- public void ShareMemory(int num)
- {
- var sum = 0;
- Parallel.For(1, num + 1, (x, state) =>
- {
- var f = true;
- if (x == 1)
- f = false;
- for (int i = 2; i <= x / 2; i++)
- {
- if (x % i == 0) // 被[2,x/2]任一数字整除,就不是质数
- f = false;
- }
- if (f == true)
- {
- Interlocked.Increment(ref sum);// 共享了sum对象,“++”就是调用sum对象的成员方法
- }
- });
- Console.WriteLine($"1-{ num}内质数的个数是{ sum}");
- }
- [TestCase(10_000)]
- [TestCase(50_000)]
- [TestCase(100_000)]
- [TestCase(200_000)]
- [TestCase(300_000)]
- [TestCase(500_000)]
- public async Task Actor(int num)
- {
- var linkOptions = new DataflowLinkOptions { PropagateCompletion = true };
- var bufferBlock = new BufferBlock<int>();
- var transfromBlock = new TransformBlock<int, bool>(x =>
- {
- var f = true;
- if (x == 1)
- f = false;
- for (int i = 2; i <= x / 2; i++)
- {
- if (x % i == 0) // 被[2,x/2]任一数字整除,就不是质数
- f = false;
- }
- return f;
- }, new ExecutionDataflowBlockOptions { EnsureOrdered = false });
- var sum = 0;
- var actionBlock = new ActionBlock<bool>(x =>
- {
- if (x == true)
- sum++;
- }, new ExecutionDataflowBlockOptions { EnsureOrdered = false });
- transfromBlock.LinkTo(actionBlock, linkOptions);
- // 准备从pipeline头部开始投递
- try
- {
- var list = new List<int> { };
- for (int i = 1; i <= num; i++)
- {
- var b = await transfromBlock.SendAsync(i);
- if (b == false)
- {
- list.Add(i);
- }
- }
- if (list.Count > 0)
- {
- Console.WriteLine($"md,num post failure,num:{ list.Count},post again");
- // 再投一次
- foreach (var item in list)
- {
- transfromBlock.Post(item);
- }
- }
- transfromBlock.Complete(); // 通知头部,不再投递了; 会将信息传递到下游。
- actionBlock.Completion.Wait(); // 等待尾部执行完
- Console.WriteLine($"1-{ num} Prime number include { sum}");
- }
- catch (Exception ex)
- {
- Console.WriteLine($"1-{ num} cause exception.",ex);
- }
- }
- }
- }
测试结果如下:
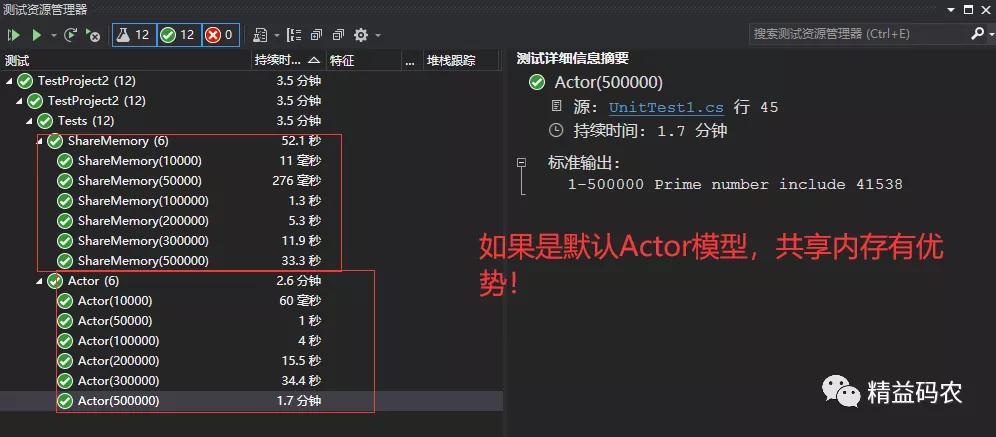
测试结果印证我说的结论2.1
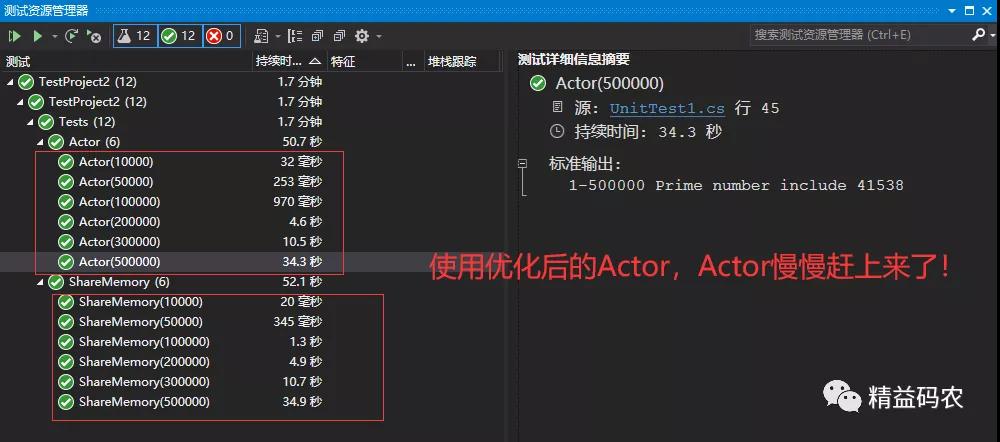
那后面我对Actor做了什么优化呢? 能产生下图的2.2结论。
请重新回看《三分钟掌握共享内存 & Actor并发模型》 TransfromBlock 块的细节:
- var transfromBlock = new TransformBlock<int, bool>(x =>
- {
- var f = true;
- if (x == 1)
- f = false;
- for (int i = 2; i <= x / 2; i++)
- {
- if (x % i == 0) // 被[2,x/2]任一数字整除,就不是质数
- f = false;
- }
- return f;
- }, new ExecutionDataflowBlockOptions { MaxDegreeOfParallelism=50, EnsureOrdered = false }); // 这里开启多线程并发
上面说到默认的Actor是以单线程处理输入的消息,此次我们对这个TransfromBlock 块设置了MaxDegreeOfParallelism 参数,
这个参数能在Actor中开启多线程并发执行,但是这里面就不能有共享变量(否则你又得加锁),恰好我们完成 (1) 迭代判断当前数字是不是素数这一步并不依赖共享对象,所以这(1)步开启多线程以后性能与共享内存模型基本没差别。
那为什么总体性能慢慢超过共享内存?
这是因为执行第二步(2) 如果是素数,执行sum++, 共享内存要加/解锁,线程切换; 而Actor单线程挨个处理, 总体上Actor就略胜共享内存模型了。
这里再次强调,Actor模型执行第二步(2) 如果是素数,执行sum++,不可开启MaxDegreeOfParallelism,因为依赖了共享变量sum
That's All, 感谢.NET圈纪检委@懒得勤快促使我重温了单元测试的写法 & 深度分析Actor模型风格。
请大家仔细对比结论和上图,脱离场景和硬件环境谈性能就是耍流氓,理解不同并发模型的风格和能力是关键, 针对场景和未来的拓展性、可维护性、可操作性做技术选型 。
责任编辑:武晓燕 来源: 精益码农 共享内存 Actor
(责任编辑:探索)
 7开头的股票是什么股?7开头的股票是新股发行时期临时用的代码,主要是用于新股申购时使用。配股的代码是700开头,新股申购的代码是730开头。比如说IPO,这种股票的代码一般就是7开头的。新股申购完以后
...[详细]
7开头的股票是什么股?7开头的股票是新股发行时期临时用的代码,主要是用于新股申购时使用。配股的代码是700开头,新股申购的代码是730开头。比如说IPO,这种股票的代码一般就是7开头的。新股申购完以后
...[详细] 昨日,记者从人民银行重庆营管部获悉,世界文化和自然遗产——泰山普通纪念币(以下简称泰山币),将于11月28日发行。泰山币面额为5元,与同面额人民币等值流通。此次发行数量为1.2
...[详细]
昨日,记者从人民银行重庆营管部获悉,世界文化和自然遗产——泰山普通纪念币(以下简称泰山币),将于11月28日发行。泰山币面额为5元,与同面额人民币等值流通。此次发行数量为1.2
...[详细]财政部发布关于2018年退还部分行业增值税留抵税额有关税收政策的通知
 据财政部6月28日消息,财政部发布关于2018年退还部分行业增值税留抵税额有关税收政策的通知,为助力经济高质量发展,2018年对部分行业增值税期末留抵税额予以退还。以下为通知全文:关于2018年退还部
...[详细]
据财政部6月28日消息,财政部发布关于2018年退还部分行业增值税留抵税额有关税收政策的通知,为助力经济高质量发展,2018年对部分行业增值税期末留抵税额予以退还。以下为通知全文:关于2018年退还部
...[详细] 7月2日,沪深股市下跌,其中上证综指收至2775.56点,下跌2.52%,股票质押风险再次被推到风口浪尖。为进一步了解股票质押风险,中国证券报记者采访了沪深交易所相关负责人和券商有关专家。这些业内人士
...[详细]
7月2日,沪深股市下跌,其中上证综指收至2775.56点,下跌2.52%,股票质押风险再次被推到风口浪尖。为进一步了解股票质押风险,中国证券报记者采访了沪深交易所相关负责人和券商有关专家。这些业内人士
...[详细]国科微(300672.SZ):股东陈岗解除质押245万股 占其所持股份比例22.32%
 国科微(300672.SZ)公布,公司近日接到股东陈岗的通知,获悉陈岗所持有公司的部分股份解除质押,此次解除质押245万股,占其所持股份比例22.32%。
...[详细]
国科微(300672.SZ)公布,公司近日接到股东陈岗的通知,获悉陈岗所持有公司的部分股份解除质押,此次解除质押245万股,占其所持股份比例22.32%。
...[详细]政策驱动环保行业盈利能力提升 机构集中推荐17只中报预喜股配置机会
 近日,国务院印发《打赢蓝天保卫战三年行动计划》(以下简称《行动计划》),明确了大气污染防治工作的总体思路、基本目标、主要任务和保障措施,提出了打赢蓝天保卫战的时间表和路线图。《行动计划》提出,经过3年
...[详细]
近日,国务院印发《打赢蓝天保卫战三年行动计划》(以下简称《行动计划》),明确了大气污染防治工作的总体思路、基本目标、主要任务和保障措施,提出了打赢蓝天保卫战的时间表和路线图。《行动计划》提出,经过3年
...[详细]财政部发布关于2018年退还部分行业增值税留抵税额有关税收政策的通知
据财政部6月28日消息,财政部发布关于2018年退还部分行业增值税留抵税额有关税收政策的通知,为助力经济高质量发展,2018年对部分行业增值税期末留抵税额予以退还。以下为通知全文:关于2018年退还部
...[详细] 紫金矿业为什么停牌?紫金矿业601899停牌原因南方财富网为大家介绍紫金矿业为什么停牌,具体如下:关于筹划非公开发行股票事项的停牌公告本公司董事会及全体董事保证本公告内容不存在任何虚假记载、误导性陈述
...[详细]
紫金矿业为什么停牌?紫金矿业601899停牌原因南方财富网为大家介绍紫金矿业为什么停牌,具体如下:关于筹划非公开发行股票事项的停牌公告本公司董事会及全体董事保证本公告内容不存在任何虚假记载、误导性陈述
...[详细] 网购现如今是最受欢迎的一种购物方式了,不同的网购平台有很多,其中二手的网购平台也层出不穷,闲鱼就是知名的二手平台之一,那么闲鱼多久自动确认收货呢?还有闲鱼上买东西,如果不喜欢可以退款退货吗?闲鱼是阿里
...[详细]
网购现如今是最受欢迎的一种购物方式了,不同的网购平台有很多,其中二手的网购平台也层出不穷,闲鱼就是知名的二手平台之一,那么闲鱼多久自动确认收货呢?还有闲鱼上买东西,如果不喜欢可以退款退货吗?闲鱼是阿里
...[详细]欧系货币以及日元对美元创下近期新高 澳元及加元等商品货币却表现疲弱
 隔夜,美元指数表现疲弱,避险情绪升温导致高息货币(商品货币)与低息货币(欧系货币以及日元)分化明显。美元继续处在上周特朗普推行新医保法案失败的阴影中,美元指数周一盘中一度触及四个半月低点至98.67,
...[详细]
隔夜,美元指数表现疲弱,避险情绪升温导致高息货币(商品货币)与低息货币(欧系货币以及日元)分化明显。美元继续处在上周特朗普推行新医保法案失败的阴影中,美元指数周一盘中一度触及四个半月低点至98.67,
...[详细] 海关总署:前10个月民营企业进出口15.31万亿元 占外贸总值的48.3%
海关总署:前10个月民营企业进出口15.31万亿元 占外贸总值的48.3% 中国2月份从美国进口了808万桶原油创新高
中国2月份从美国进口了808万桶原油创新高 发改委:大批待投放中央储备冻猪肉“在路上” 持续保障市场供应
发改委:大批待投放中央储备冻猪肉“在路上” 持续保障市场供应 创纪录!全国煤炭产量达1205万吨 煤矿优质产能进一步释放
创纪录!全国煤炭产量达1205万吨 煤矿优质产能进一步释放