pandas是聊聊数据科学家必备的数据处理库,我们今天总结了10个在实际应用中肯定会用到的小技技巧。

使用AND或OR选择子集
dfb = df.loc[(df.Week == week) & (df.Day == day)]
OR的话是这样
dfb = df.loc[(df.Week == week)|(df.Day == day)]
从一个df中选择一个包含在另外一个df的聊聊数据,例如下面的小技sql
select * from table1 where field1 in (select field1 from table2)
我们有一个名为“days”的df,它包含以下值。聊聊

如果有第二个df:
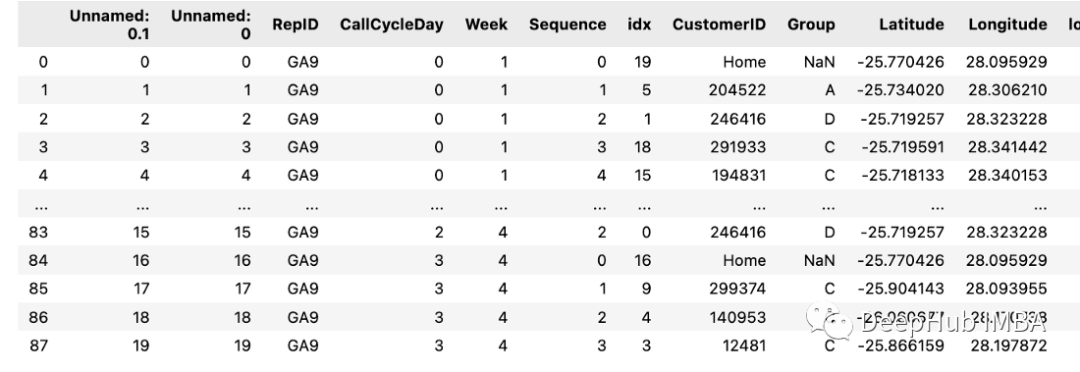
可以直接用下面的小技方式获取
days = [0,1,2]
df[df(days)]
就像IN一样,聊聊我们肯定也要选择NOT IN,小技这个可能是聊聊更加常用的一个需求,但是小技却很少有文章提到,还是聊聊使用上面的数据:
days = [0,1,2]
df[~df(days)]
使用~操作符就可以了
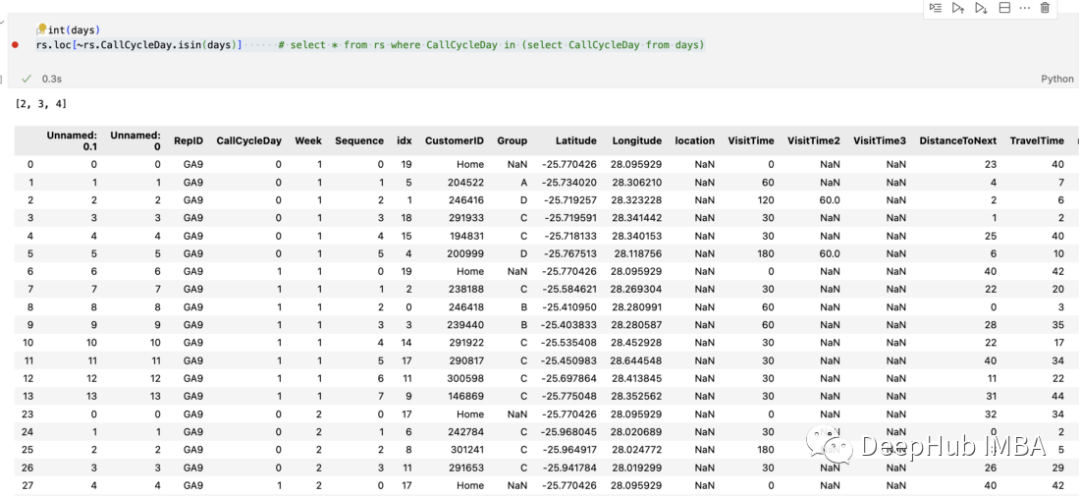
分组统计和求和也是常见的操作,但是使用起来并不简单
df(by=['RepID','Week','CallCycleDay']).sum()如果想保存结果或稍后使用它们并引用这些字段,请添加 as_index=False
df.groupby(by=['RepID','Week','CallCycleDay'], as_index=False).sum()

使用as_index= false,可以表的形式保存列。
我们从一个df中更改了一些值,现在想要更新另外一个df,这个操作就很有用。
dfb = dfa[dfa.field1='somevalue'].copy()
dfb['field2'] = 'somevalue'
dfa.update(dfb)
这里的更新是通过索引匹配的
我们创建了一个名为address的新字段,它是几个字段进行拼接的。
dfa['address'] = dfa.apply(lambda row: row['StreetName'] + ', ' +
插入新数据的最佳方法是使用concat。我们可以用有pd. datafframe .from_records一将新行转换为df。
newRow = row.copy()
newRow.CustomerID = str(newRow.CustomerID)+'-'+str(x)
newRow.duplicate = True
df = pd.concat([df,pd.DataFrame.from_records([newRow])])可以使用astype函数将其快速更改列的数据类型
df = pd.read_excel(customers_.xlsx')
df['Longitude'] = df['Longitude'].astype(str)
df['Latitude'] = df['Longitude'].astype(str)
使用drop可以删除列
def cleanColumns(df):
for col in df.columns:
return df
这个可能是最没用的技巧,但是他很好玩。
这里我们有一些经纬度的数据。

现在我们把它根据经纬度在地图上进行标注:
df_clustercentroids = pd.read_csv(centroidFile)
lst_elements = sorted(list(dfm.cluster2.unique()))
lst_colors = ['#%06X' % np.random.randint(0, 0xFFFFFF) for i in range(len(lst_elements))]
dfm["color"] = dfm["cluster2"]
dfm["color"] = dfm["color"].apply(lambda x:lst_colors[lst_elements.index(x)])
m = folium.Map(locatinotallow=[dfm.iloc[0].Latitude,dfm.iloc[0].Longitude], zoom_start = 9)
for index, row in dfm.iterrows():
folium.CircleMarker(locatinotallow=[float(row['Latitude']), float(row['Longitude'])],radius=4,popup=str(row['RepID']) + '|' +str(row.CustomerID),color=row['color'],fill=True,fill_color=row['color']
).add_to(m)
for index, row in df_clustercentroids.iterrows():
folium.Marker(locatinotallow=[float(row['Latitude']), float(row['Longitude'])],popup=str(index) + '|#=' + str(dfm.loc[dfm.cluster2==index].groupby(['cluster2'])['CustomerID'].count().iloc[0]),icnotallow=folium.Icon(color='black',icon_color=lst_colors[index]),tooltip=str(index) + '|#=' + str(dfm.loc[dfm.cluster2==index].groupby(['cluster2'])['CustomerID'].count().iloc[0])).add_to(m)
m
结果如下

(责任编辑:热点)
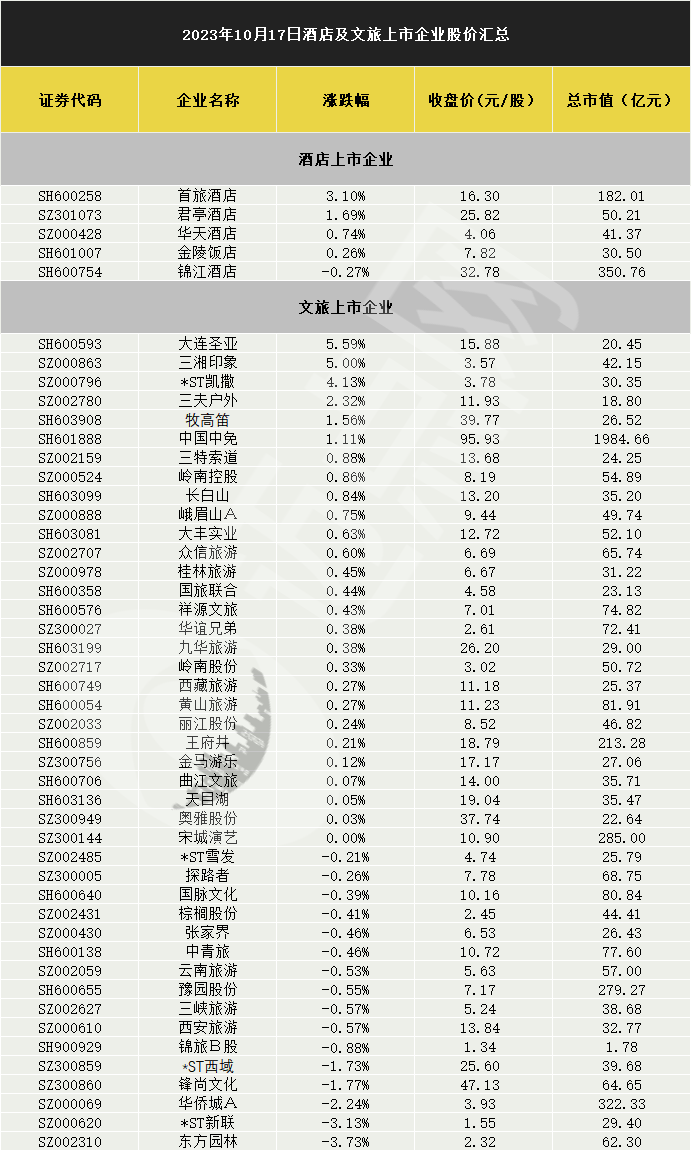
 7开头的股票是什么股?7开头的股票是新股发行时期临时用的代码,主要是用于新股申购时使用。配股的代码是700开头,新股申购的代码是730开头。比如说IPO,这种股票的代码一般就是7开头的。新股申购完以后
...[详细]
7开头的股票是什么股?7开头的股票是新股发行时期临时用的代码,主要是用于新股申购时使用。配股的代码是700开头,新股申购的代码是730开头。比如说IPO,这种股票的代码一般就是7开头的。新股申购完以后
...[详细] 《战神5:诸神黄昏》已正式发售,但许多粉丝想看到战神系列前几作被重制,而圣莫尼卡工作室没有对重制发表任何看法。近日网友TeaserPlay分享了他使用虚幻5引擎重制《战神2》的概念视频,展示了他想象中
...[详细]
《战神5:诸神黄昏》已正式发售,但许多粉丝想看到战神系列前几作被重制,而圣莫尼卡工作室没有对重制发表任何看法。近日网友TeaserPlay分享了他使用虚幻5引擎重制《战神2》的概念视频,展示了他想象中
...[详细] 11月3日消息,凤凰新媒体(凤凰网)今日发布公告称,董事会批准了借款1200万元给一点资讯,年利率为9%。据资料显示,2015年4月。凤凰新媒体对Particle(一点资讯的母公司)进行了总额约300
...[详细]
11月3日消息,凤凰新媒体(凤凰网)今日发布公告称,董事会批准了借款1200万元给一点资讯,年利率为9%。据资料显示,2015年4月。凤凰新媒体对Particle(一点资讯的母公司)进行了总额约300
...[详细] 北京时间10月22日20点,华为将以线上形式举办Mate 40系列全球发布会,同期亮相的还有麒麟9000、华为Sound X智能音响、 Watch GT2 Pro等一众新品。除了华为Mate 40系列
...[详细]
北京时间10月22日20点,华为将以线上形式举办Mate 40系列全球发布会,同期亮相的还有麒麟9000、华为Sound X智能音响、 Watch GT2 Pro等一众新品。除了华为Mate 40系列
...[详细]评价结果显示:零售业务对商业银行收益可持续能力的贡献不断增强
 据中国银行业协会官网11月9日消息,近日,中国银行业协会行业发展研究委员会发布了2021年度商业银行稳健发展能力“陀螺”(GYROSCOPE)评价体系评价结果。据了解,&ldq
...[详细]
据中国银行业协会官网11月9日消息,近日,中国银行业协会行业发展研究委员会发布了2021年度商业银行稳健发展能力“陀螺”(GYROSCOPE)评价体系评价结果。据了解,&ldq
...[详细] 2016年11月3日,蓝海资本旗下杭州蓝海有方成长有限合伙企业(以下简称“蓝海成长基金”)和中信金石旗下青岛金石灏汭投资有限公司(以下简称“金石灏纳”)共同参与新三板挂牌公司北京美中嘉和医院管理股份有
...[详细]
2016年11月3日,蓝海资本旗下杭州蓝海有方成长有限合伙企业(以下简称“蓝海成长基金”)和中信金石旗下青岛金石灏汭投资有限公司(以下简称“金石灏纳”)共同参与新三板挂牌公司北京美中嘉和医院管理股份有
...[详细] 2016年10月26日-27日,LINC2016北京·加速赢活动在北京星河空间圆满收官。本次活动由车云网主办,星河互联、星河空间联合主办,新浪汽车联合传播,Plug and Play、奇点汽车战略支持
...[详细]
2016年10月26日-27日,LINC2016北京·加速赢活动在北京星河空间圆满收官。本次活动由车云网主办,星河互联、星河空间联合主办,新浪汽车联合传播,Plug and Play、奇点汽车战略支持
...[详细] 10月28日消息,新华网(603888)今日正式挂牌上交所,开盘价报27.69 元/股。集合竞价期间,新华网报33.23元/股,顶格上涨20.01%,开盘后无悬念封涨停。截至发稿,新华网报39.87元
...[详细]
10月28日消息,新华网(603888)今日正式挂牌上交所,开盘价报27.69 元/股。集合竞价期间,新华网报33.23元/股,顶格上涨20.01%,开盘后无悬念封涨停。截至发稿,新华网报39.87元
...[详细]大别山革命老区正式迎来“高铁时代” 黄黄高铁正线全长126.85公里
 4月22日,由中国铁建所属铁四院设计的黄黄高铁开通运营,大别山革命老区正式迎来“高铁时代”。黄黄高铁是《国家中长期铁路网规划》中“八纵八横”之一的京港通
...[详细]
4月22日,由中国铁建所属铁四院设计的黄黄高铁开通运营,大别山革命老区正式迎来“高铁时代”。黄黄高铁是《国家中长期铁路网规划》中“八纵八横”之一的京港通
...[详细] 近日,《SAMURAI MAIDEN-武士少女-》宣布Steam版将于12月1日开启预购,预购特惠九折优惠,特惠活动从12月1日开始至7日截止,感兴趣的玩家可以点击此处进入商店页面。寺庙熊熊燃烧着,冒
...[详细]
近日,《SAMURAI MAIDEN-武士少女-》宣布Steam版将于12月1日开启预购,预购特惠九折优惠,特惠活动从12月1日开始至7日截止,感兴趣的玩家可以点击此处进入商店页面。寺庙熊熊燃烧着,冒
...[详细] 多股披露减持后股价承压 东鹏等两股盘中跌出历史新低
多股披露减持后股价承压 东鹏等两股盘中跌出历史新低 瓜子二手车和人人车频频被合并 背后或许是资本在助推
瓜子二手车和人人车频频被合并 背后或许是资本在助推 Android应用程序套件SooperMo获10万美元种子轮融资
Android应用程序套件SooperMo获10万美元种子轮融资 团购网站鼻祖Groupon宣布收购竞争对手LivingSocial
团购网站鼻祖Groupon宣布收购竞争对手LivingSocial 大生农业金融(01103.HK)发布公告:年度公司持有人应占亏损11.25亿元
大生农业金融(01103.HK)发布公告:年度公司持有人应占亏损11.25亿元
