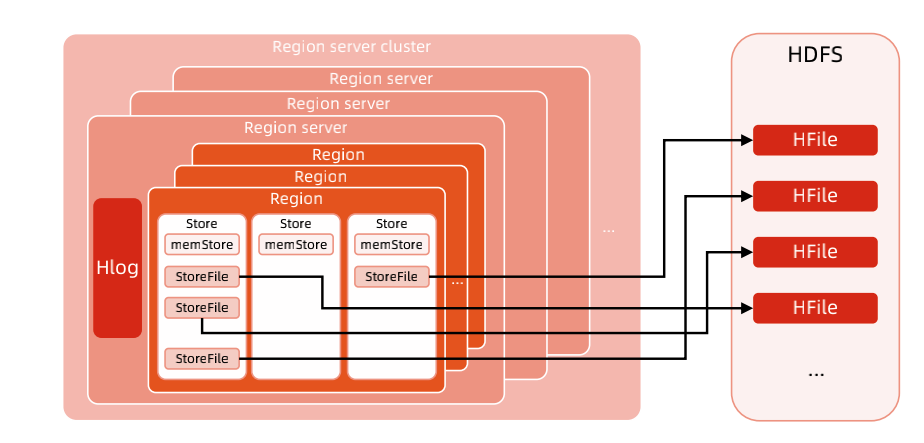
[[419041]]
1.对于mysql,推荐不推荐使用子查询和join是使用因为本身join的效率就是硬伤,一旦数据量很大效率就很难保证,查询强烈推荐分别根据索引单表取数据,推荐然后在程序里面做join,使用merge数据。查询
2.子查询就更别用了,推荐效率太差,使用执行子查询时,查询MYSQL需要创建临时表,查询完毕后再删除这些临时表,所以,子查询的速度会受到一定的影响,这里多了一个创建和销毁临时表的过程。

3.如果是JOIN的话,它是走嵌套查询的。小表驱动大表,且通过索引字段进行关联。如果表记录比较少的话,还是OK的。大的话业务逻辑中可以控制处理。

4.数据库是最底层的,瓶颈往往是数据库。建议数据库只是作为数据store的工具,而不要添加业务上去。
让缓存的效率更高。许多应用程序可以方便地缓存单表查询对应的结果对象。如果关联中的某个表发生了变化,那么就无法使用查询缓存了,而拆分后,如果某个表很少改变,那么基于该表的查询就可以重复利用查询缓存结果了。
1.DB承担的业务压力大,能减少负担就减少。当表处于百万级别后,join导致性能下降;
2.分布式的分库分表。这种时候是不建议跨库join的。目前mysql的分布式中间件,跨库join表现不良。
3.修改表的schema,单表查询的修改比较容易,join写的sql语句要修改,不容易发现,成本比较大,当系统比较大时,不好维护。
在业务层,单表查询出数据后,作为条件给下一个单表查询。也就是子查询。会担心子查询出来的结果集太多。mysql对in的数量没有限制,但是mysql限制整条sql语句的大小。通过调整参数max_allowed_packet ,可以修改一条sql的最大值。建议在业务上做好处理,限制一次查询出来的结果集是能接受的。
关联查询的好处是可以做分页,可以用副表的字段做查询条件,在查询的时候,将副表匹配到的字段作为结果集,用主表去in它。但是问题来了,如果匹配到的数据量太大就不行了,也会导致返回的分页记录跟实际的不一样,解决的方法可以交给前端,一次性查询,让前端分批显示就可以了,这种解决方案的前提是数据量不太,因为sql本身长度有限。
责任编辑:庞桂玉 来源: 数据库开发 MySQLJOIN数据库
(责任编辑:知识)
冠豪高新(600433.SH):重组事项获有条件通过 公司A股股票自3月12日起复牌
 冠豪高新(600433.SH)公布,2021年3月11日,中国证监会上市公司并购重组审核委员会(“并购重组委”)召开2021年第5次并购重组委工作会议,对公司换股吸收合并佛山华
...[详细]
冠豪高新(600433.SH)公布,2021年3月11日,中国证监会上市公司并购重组审核委员会(“并购重组委”)召开2021年第5次并购重组委工作会议,对公司换股吸收合并佛山华
...[详细]2021人均GDP新格局:27城跨入发达国家门槛,数量暴增!
 2021人均GDP新格局:27城跨入发达国家门槛,数量暴增!2022-05-05 08:19:48大数据 数据分析 本文所列的人均GDP数据一部分来源于各地统计公报,一部分为搜狐城市根据当地2021年
...[详细]
2021人均GDP新格局:27城跨入发达国家门槛,数量暴增!2022-05-05 08:19:48大数据 数据分析 本文所列的人均GDP数据一部分来源于各地统计公报,一部分为搜狐城市根据当地2021年
...[详细]印度天才数学家拉马努金留下的3000+神奇公式,交给AI来「证明」!
 印度天才数学家拉马努金留下的3000+神奇公式,交给AI来「证明」!作者:佚名 2021-02-04 15:19:22新闻 人工智能 近日,《自然》杂志上发表了一个项目,有研究人员建立了一个AI算法项
...[详细]
印度天才数学家拉马努金留下的3000+神奇公式,交给AI来「证明」!作者:佚名 2021-02-04 15:19:22新闻 人工智能 近日,《自然》杂志上发表了一个项目,有研究人员建立了一个AI算法项
...[详细]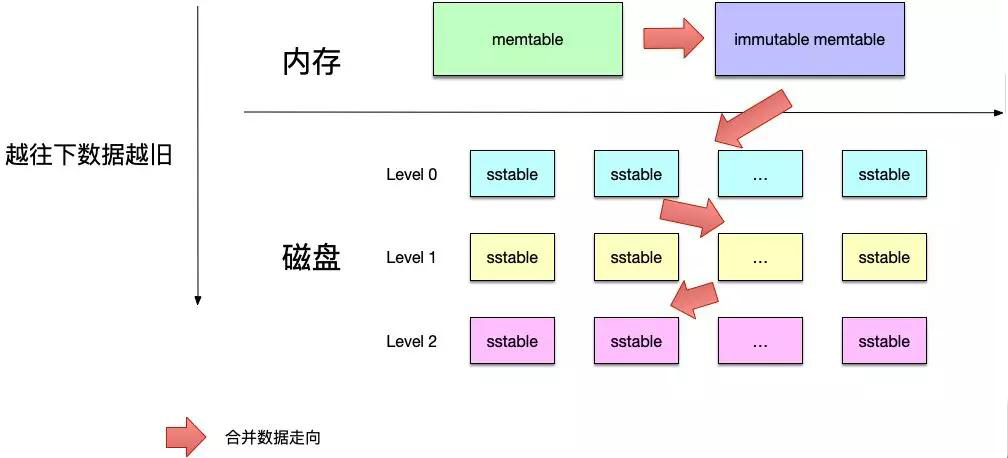 经典开源代码分析——Leveldb高效存储实现作者:codedump 2019-03-12 11:11:25存储 存储软件 LevelDB是Google开源的持久化KV数据库,在其高性能的背后,将数据
...[详细]
经典开源代码分析——Leveldb高效存储实现作者:codedump 2019-03-12 11:11:25存储 存储软件 LevelDB是Google开源的持久化KV数据库,在其高性能的背后,将数据
...[详细]合丰集团(02320.HK)发布公告:年度公司拥有人应占亏损1.72亿港元
 合丰集团(02320.HK)发布公告,截至2021年12月31日止年度,收益减少至约7.556亿港元,较2020年下跌约27.4%。公司拥有人应占亏损约为1.724亿港元,而2020年的公司拥有人应占
...[详细]
合丰集团(02320.HK)发布公告,截至2021年12月31日止年度,收益减少至约7.556亿港元,较2020年下跌约27.4%。公司拥有人应占亏损约为1.724亿港元,而2020年的公司拥有人应占
...[详细]SatSure获得1500万美元A轮融资,Promus Ventures领投
 艾媒咨询9月26日消息,SatSure宣布已完成1500万美元A轮融资。据了解,本轮融资由Baring Private Equity PartnersBPEP),India和Promus Ventur
...[详细]
艾媒咨询9月26日消息,SatSure宣布已完成1500万美元A轮融资。据了解,本轮融资由Baring Private Equity PartnersBPEP),India和Promus Ventur
...[详细] 实在!三招儿削减数据中心能源成本作者:佚名 2010-11-10 11:16:39运维 服务器运维 服务器虚拟化技术已经在切切实实地为你省钱。那么,为什么不多省一些钱呢?弗雷斯特研究公司介绍了它所推荐
...[详细]
实在!三招儿削减数据中心能源成本作者:佚名 2010-11-10 11:16:39运维 服务器运维 服务器虚拟化技术已经在切切实实地为你省钱。那么,为什么不多省一些钱呢?弗雷斯特研究公司介绍了它所推荐
...[详细]让电影动漫统统变丝滑,480帧毫无卡顿,交大博士生开源插帧软件
 让电影动漫统统变丝滑,480帧毫无卡顿,交大博士生开源插帧软件作者:晓查 2020-01-29 19:35:17新闻 开源 连手机都开始用上120帧的显示屏,但是网上大部分的视频居然还是30帧。 本
...[详细]
让电影动漫统统变丝滑,480帧毫无卡顿,交大博士生开源插帧软件作者:晓查 2020-01-29 19:35:17新闻 开源 连手机都开始用上120帧的显示屏,但是网上大部分的视频居然还是30帧。 本
...[详细] 作为四大银行之一,农业银行旗下的贷款产品是非常多的。为了满足更多客户的贷款需求,农业银行也推出了一些线上可以申请的个人小额贷款产品,网捷贷。农行网捷贷利息高吗?农行网捷贷是不是随借随还?一起来跟希财君
...[详细]
作为四大银行之一,农业银行旗下的贷款产品是非常多的。为了满足更多客户的贷款需求,农业银行也推出了一些线上可以申请的个人小额贷款产品,网捷贷。农行网捷贷利息高吗?农行网捷贷是不是随借随还?一起来跟希财君
...[详细] 【CNMO新闻】8月16日,CNMO注意到,上海盒马网络科技有限公司新增了一条被行政处罚的信息。盒马据悉,由于盒马公司在最近,因为生产经营超范围、超限量使用食品添加剂的食品,从而被上海市浦东新区市场监
...[详细]
【CNMO新闻】8月16日,CNMO注意到,上海盒马网络科技有限公司新增了一条被行政处罚的信息。盒马据悉,由于盒马公司在最近,因为生产经营超范围、超限量使用食品添加剂的食品,从而被上海市浦东新区市场监
...[详细] 节能元件(08231.HK)发布公告:预计年度由亏转盈60万美元
节能元件(08231.HK)发布公告:预计年度由亏转盈60万美元 怎样在 Linux 中使用动态和静态库
怎样在 Linux 中使用动态和静态库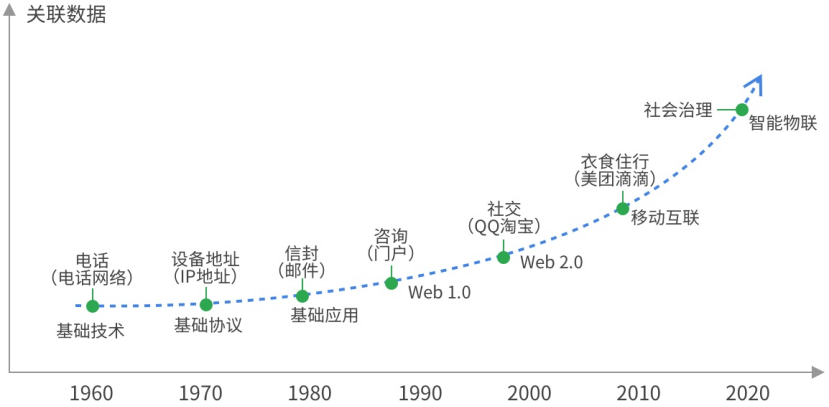 5G时代Web前端的边界拓展思考
5G时代Web前端的边界拓展思考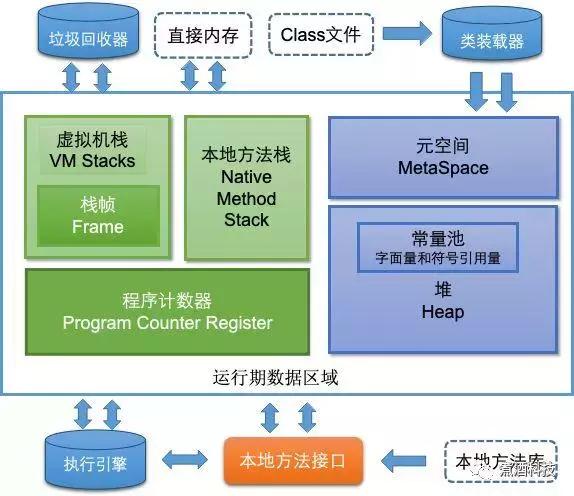 从JVM模型谈十种内存溢出及解决方法
从JVM模型谈十种内存溢出及解决方法 中国经济占全球经济比重将持续增加 新的全球经济力量布局正在形成
中国经济占全球经济比重将持续增加 新的全球经济力量布局正在形成