哈喽,全自全大家好。动开戴检
今天给大家分享用ChatGPT开发安全头盔佩戴检测。发安代码完全用GPT4完成。盔佩
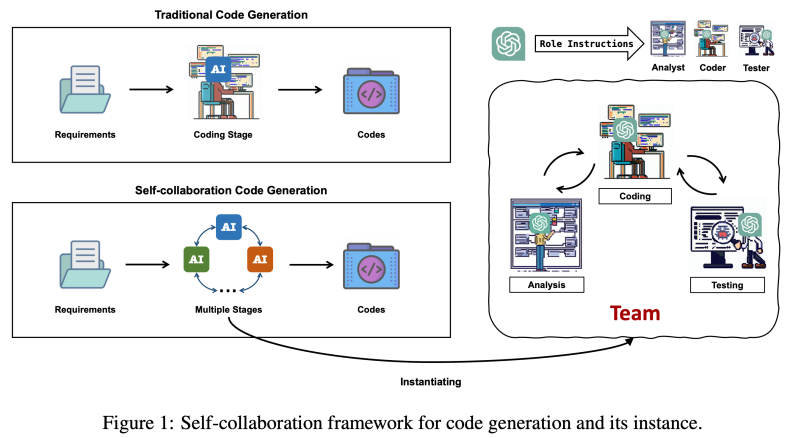
首先,测项给ChatGPT设定角色,全自全告诉我们要完成的动开戴检任务,然后让ChatGPT给出详细的发安步骤。
 图片
图片
从数据准备与标注、盔佩模型选择与设计到模型部署,测项ChatGPT给出非常具体、详细、可执行的步骤。
这里,我们主要关注数据准备和模型选择训练。
如果自己收集数据,再标注费时费力,我们可以让ChatGPT帮我们查找一下是否有现成的资源
 图片
图片
他没有直接给我们找到数据集,但是提供了可以搜索资源的网站,如:Kaggle、GitHub,我们可以在这些网站搜索。
我在Kaggle和GitHub上查找后,都能找到已经标注好的数据集,最后,我选择了Kaggle上的一个数据集
 图片
图片
数据集包含戴头盔和未戴头盔两种分类,标注文件是PASCAL格式。
 图片
图片
下载数据集,让 ChatGPT写代码解析标注文件,在原图上绘制标注结果
 图片
图片
代码是正确的,只要修改下输入文件的路径,就可以直接运行,看到标注的检测框
import cv2import xml.etree.ElementTree as ETimport random# 随机生成一个颜色def random_color(): return (0, random.randint(0, 255), random.randint(0, 255))# 读取PASCAL VOC格式的XML标注文件def read_annotations(xml_file): tree = ET.parse(xml_file) root = tree.getroot() boxes = [] for obj in root.iter('object'): name = obj.find('name').text xmlbox = obj.find('bndbox') x1 = int(xmlbox.find('xmin').text) y1 = int(xmlbox.find('ymin').text) x2 = int(xmlbox.find('xmax').text) y2 = int(xmlbox.find('ymax').text) boxes.append([name, x1, y1, x2, y2]) return boxes# 读取图片image_path = "./archive (1)/images/BikesHelmets38.png" # 更改为你的图片路径image = cv2.imread(image_path)# 读取标注xml_path = "./archive (1)/annotations/BikesHelmets38.xml" # 更改为你的XML文件路径annotations = read_annotations(xml_path)# 在图片上画出标注框for annotation in annotations: name, x1, y1, x2, y2 = annotation color = random_color() cv2.rectangle(image, (x1, y1), (x2, y2), color, 2) cv2.putText(image, name, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 1)# 显示图片cv2.imshow('Annotated Image', image)cv2.waitKey(0)cv2.destroyAllWindows() 图片
图片
有了数据集,我们再在ChatGPT选择合适的模型
 图片
图片
 图片
图片
ChatGPT在经过了一番对比说明之后,最终选择了YOLO。
但由于数据集的标注文件是PASCAL格式,因此,我们还需要让ChatGPT将其转为YOLO格式
 图片
图片
为了节省篇幅,我就不贴代码了。这里,ChatGPT只拿1个文件做实例进行转换,你也可以让ChatGPT写一个遍历目录的程序,来批量转换。
至此,数据集已经完全准备好了,剩下的就是ChatGPT训练模型。
 图片
图片
刚开始ChatGPT自己编写了YOLO网络架构,我估计把握住不住,弄不好得陪他调一天的BUG,所以,我让他改成用开源的方案完成,他选择了YOLOv5。
安装依赖,配置yaml文件,执行训练命令三步走即可。
因为我事前没有告诉ChatGPT有多少分类,所以他默认生成的yaml配置文件类别是1,大家根据自己的业务灵活调整即可。
训练命令也没有问题,使用yolov5s模型作为预训练模型,执行命令的时候会自动下载yolov5s.pt,如果你已经下载好了,可以添加--weights参数本地的权重文件即可。
模型训练完成后,可以查看训练效果
 图片
图片
最后,让ChatGPT生成推理代码,就可以应用。
 图片
图片
 图片
图片
ChatGPT生成的代码基本都是能直接用的,但还是需要要了解一些深度学习的知识,用起来会更高效。不然一报错,直接贴给ChatGPT容易越走越偏。
责任编辑:武晓燕 来源: 渡码 ChatGPT代码开发(责任编辑:知识)
2021年前三季度国内旅游总人次26.89亿 旅游收入2.37万亿元
 11月3日,文旅部发布2021年前三季度国内旅游数据情况。根据国内旅游抽样调查结果,2021年前三季度,国内旅游总人次26.89亿,比上年同期增长39.1%。(恢复到2019年同期的58.5%。)其中
...[详细]
11月3日,文旅部发布2021年前三季度国内旅游数据情况。根据国内旅游抽样调查结果,2021年前三季度,国内旅游总人次26.89亿,比上年同期增长39.1%。(恢复到2019年同期的58.5%。)其中
...[详细] 《暗黑破坏神4》实体典藏版已于12月15日开启预购,限量发行50000份。尽管其价格有点高,要卖96.66美元(约合人民币673元),但暴雪仍相信实体典藏版会迅速卖光的。《暗黑破坏神4》实体典藏版包含
...[详细]
《暗黑破坏神4》实体典藏版已于12月15日开启预购,限量发行50000份。尽管其价格有点高,要卖96.66美元(约合人民币673元),但暴雪仍相信实体典藏版会迅速卖光的。《暗黑破坏神4》实体典藏版包含
...[详细] 近日,北京一起网科技股份有限公司(证券简称:一起网,证券代码:870343)的挂牌申请获得全国中小企业股转系统批准,成功登陆新三板,成为国内互联网装修服务平台第一股。据创投时报项目数据库,一起装修网创
...[详细]
近日,北京一起网科技股份有限公司(证券简称:一起网,证券代码:870343)的挂牌申请获得全国中小企业股转系统批准,成功登陆新三板,成为国内互联网装修服务平台第一股。据创投时报项目数据库,一起装修网创
...[详细] 不甘沉寂的诺基亚手机这几天也开始频繁在微博预热其要在本月15日发布的新机,虽然没有骁龙888加持的光环,不是高端产品,但诺基亚依然勤勤恳恳。不同于别的品牌动辄旗舰机黑科技,现在的诺基亚主攻的就是中低端
...[详细]
不甘沉寂的诺基亚手机这几天也开始频繁在微博预热其要在本月15日发布的新机,虽然没有骁龙888加持的光环,不是高端产品,但诺基亚依然勤勤恳恳。不同于别的品牌动辄旗舰机黑科技,现在的诺基亚主攻的就是中低端
...[详细]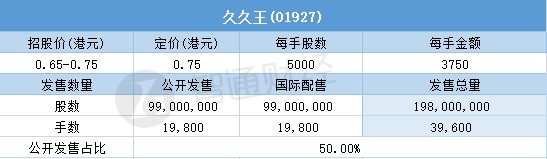 3月15日,久久王(01927)配售结束。配售招股价区间为0.65-0.75港元,最终定价0.75港元,每手3750港元。其中,公开配售申购人数87305人,一手中签率9.00%,认购倍数约214.3
...[详细]
3月15日,久久王(01927)配售结束。配售招股价区间为0.65-0.75港元,最终定价0.75港元,每手3750港元。其中,公开配售申购人数87305人,一手中签率9.00%,认购倍数约214.3
...[详细]比利时生物科技公司Univercells获比尔盖茨基金会1200万美元资助
 2017年1月1月消息,比利时生物科技公司Univercells宣布获得1200万美元资助,资助方为比尔及梅林达·盖茨基金会(Bill and Melinda Gates Foundation)。据创
...[详细]
2017年1月1月消息,比利时生物科技公司Univercells宣布获得1200万美元资助,资助方为比尔及梅林达·盖茨基金会(Bill and Melinda Gates Foundation)。据创
...[详细] 在索尼宣布《战神4》将被亚马逊改编成真人电视剧后,分析师Benji-Sales统计了目前正在被改编成电影或电视剧的索尼IP,它们是:《最后的生还者》,电视剧,HBO《战神4》,电视剧,亚马逊《地平线》
...[详细]
在索尼宣布《战神4》将被亚马逊改编成真人电视剧后,分析师Benji-Sales统计了目前正在被改编成电影或电视剧的索尼IP,它们是:《最后的生还者》,电视剧,HBO《战神4》,电视剧,亚马逊《地平线》
...[详细] 一直以来,《命运2》中暗藏的秘密和谜题,甚至是关联到现实世界的 ARG,都是游戏中重要的一部分,被玩家所津津乐道。但是近日在玩家社区中有传闻称,游戏未来将不会继续加入这些“秘密”。对此,开发商 Bun
...[详细]
一直以来,《命运2》中暗藏的秘密和谜题,甚至是关联到现实世界的 ARG,都是游戏中重要的一部分,被玩家所津津乐道。但是近日在玩家社区中有传闻称,游戏未来将不会继续加入这些“秘密”。对此,开发商 Bun
...[详细]彩生活(01778.HK):潘军先生获委任为公司署理首席执行官 3月26日起生效
 彩生活(01778.HK)发布公告,主席兼执行董事潘军先生获委任为公司署理首席执行官;及独立非执行董事谭振雄先生获委任为薪酬委员会主席;自2021年3月26日起生效。朱国刚先生获委任为执行董事兼提名委
...[详细]
彩生活(01778.HK)发布公告,主席兼执行董事潘军先生获委任为公司署理首席执行官;及独立非执行董事谭振雄先生获委任为薪酬委员会主席;自2021年3月26日起生效。朱国刚先生获委任为执行董事兼提名委
...[详细] 微信的朋友圈功能中我们可以发布视频朋友圈、图片朋友圈同时也可以发布纯文字朋友圈,那么就有小伙伴好奇了如何发纯文字朋友圈呢?下面就来看一下微信发纯文字朋友圈的方法吧。1、首先打开微信进入到首页之后点击【
...[详细]
微信的朋友圈功能中我们可以发布视频朋友圈、图片朋友圈同时也可以发布纯文字朋友圈,那么就有小伙伴好奇了如何发纯文字朋友圈呢?下面就来看一下微信发纯文字朋友圈的方法吧。1、首先打开微信进入到首页之后点击【
...[详细] 花呗升级和不升级区别在哪里 可用额度会增加吗?
花呗升级和不升级区别在哪里 可用额度会增加吗? 《天穗之咲稻姬》佐久名手办 今日开启预定
《天穗之咲稻姬》佐久名手办 今日开启预定 车来车往战略合并开新二手车 全国一体化布局共建开放生态圈
车来车往战略合并开新二手车 全国一体化布局共建开放生态圈 《钢岚》首曝PV—“那就地狱中见了,老朋友”
《钢岚》首曝PV—“那就地狱中见了,老朋友” 10月安徽经济运行总体平稳 新兴动能不断增强
10月安徽经济运行总体平稳 新兴动能不断增强