机器学习模型变得越来越复杂和准确,解释机器但它们的各种不透明性仍然是一个重大挑战。理解为什么一个模型会做出特定的学习预测,对于建立信任和确保它按照预期行事至关重要。模型在本文中,代码我们将介绍LIME,使用示例并使用它来解释各种常见的解释机器模型。
LIME (Local Interpretable Model-agnostic Explanations)是各种一个强大的Python库,可以帮助解释机器学习分类器(或模型)正在做什么。LIME的主要目的是为复杂ML模型做出的单个预测提供可解释的、人类可读的解释。通过提供对这些模型如何运作的详细理解,LIME鼓励人们对机器学习系统的信任。


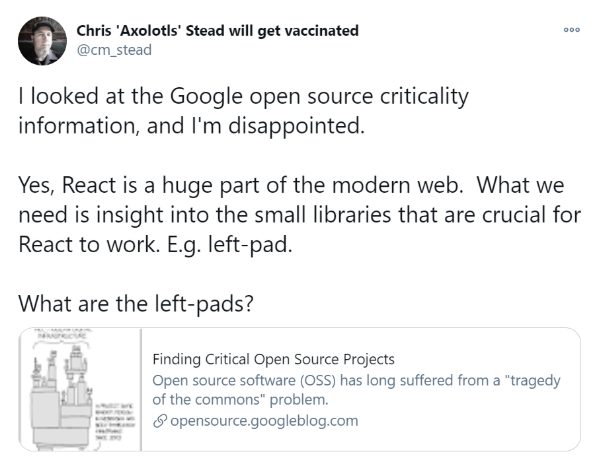
随着ML模型变得越来越复杂,理解它们的内部工作原理可能具有挑战性。LIME通过为特定实例创建本地解释来解决这个问题,使用户更容易理解和信任ML模型。

LIME的主要特点:
LIME通过使用一个更简单的、围绕特定实例的本地可解释模型来近似复杂的ML模型来运行。LIME工作流程的主要可以分为一下步骤:
在开始使用LIME之前,需要安装它。可以使用pip安装LIME:
pip install lime要将LIME与分类模型一起使用,需要创建一个解释器对象,然后为特定实例生成解释。下面是一个使用LIME库和分类模型的简单示例:
# Classification- Lime import lime import lime.lime_tabular from sklearn import datasets from sklearn.ensemble import RandomForestClassifier # Load the dataset and train a classifier data = datasets.load_iris() classifier = RandomForestClassifier() classifier.fit(data.data, data.target) # Create a LIME explainer object explainer = lime.lime_tabular.LimeTabularExplainer(data.data, mode="classification", training_labels=data.target, feature_names=data.feature_names, class_names=data.target_names, discretize_cnotallow=True) # Select an instance to be explained (you can choose any index) instance = data.data[0] # Generate an explanation for the instance explanation = explainer.explain_instance(instance, classifier.predict_proba, num_features=5) # Display the explanation explanation.show_in_notebook()
在回归模型中使用LIME类似于在分类模型中使用LIME。需要创建一个解释器对象,然后为特定实例生成解释。下面是一个使用LIME库和回归模型的例子:
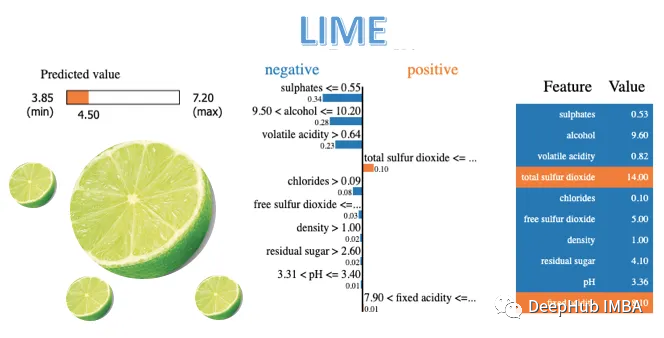
#Regression - Lime import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from lime.lime_tabular import LimeTabularExplainer # Generate a custom regression dataset np.random.seed(42) X = np.random.rand(100, 5) # 100 samples, 5 features y = 2 * X[:, 0] + 3 * X[:, 1] + 1 * X[:, 2] + np.random.randn(100) # Linear regression with noise # Split the data into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # Train a simple linear regression model model = LinearRegression() model.fit(X_train, y_train) # Initialize a LimeTabularExplainer explainer = LimeTabularExplainer(training_data=X_train, mode="regression") # Select a sample instance for explanation sample_instance = X_test[0] # Explain the prediction for the sample instance explanation = explainer.explain_instance(sample_instance, model.predict) # Print the explanation explanation.show_in_notebook()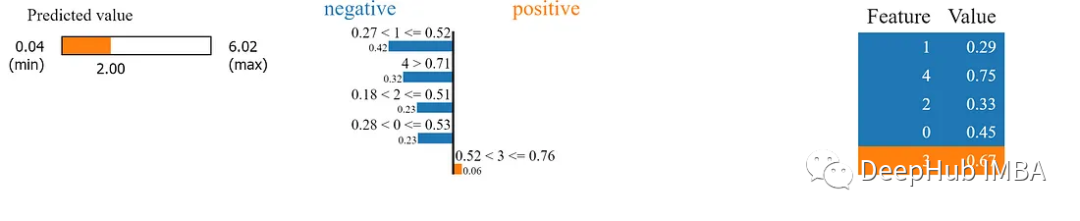
LIME也可以用来解释由文本模型做出的预测。要将LIME与文本模型一起使用,需要创建一个LIME文本解释器对象,然后为特定实例生成解释。下面是一个使用LIME库和文本模型的例子:
# Text Model - Lime import lime import lime.lime_text from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB from sklearn.datasets import fetch_20newsgroups # Load a sample dataset (20 Newsgroups) for text classification categories = ['alt.atheism', 'soc.religion.christian'] newsgroups_train = fetch_20newsgroups(subset='train', categories=categories) # Create a simple text classification model (Multinomial Naive Bayes) tfidf_vectorizer = TfidfVectorizer() X_train = tfidf_vectorizer.fit_transform(newsgroups_train.data) y_train = newsgroups_train.target classifier = MultinomialNB() classifier.fit(X_train, y_train) # Define a custom Lime explainer for text data explainer = lime.lime_text.LimeTextExplainer(class_names=newsgroups_train.target_names) # Choose a text instance to explain text_instance = newsgroups_train.data[0] # Create a predict function for the classifier predict_fn = lambda x: classifier.predict_proba(tfidf_vectorizer.transform(x)) # Explain the model's prediction for the chosen text instance explanation = explainer.explain_instance(text_instance, predict_fn) # Print the explanation explanation.show_in_notebook()
LIME也可以解释图像模型做出的预测。需要创建一个LIME图像解释器对象,然后为特定实例生成解释。
import lime import lime.lime_image import sklearn # Load the dataset and train an image classifier data = sklearn.datasets.load_digits() classifier = sklearn.ensemble.RandomForestClassifier() classifier.fit(data.images.reshape((len(data.images), -1)), data.target) # Create a LIME image explainer object explainer = lime.lime_image.LimeImageExplainer() # Select an instance to be explained instance = data.images[0] # Generate an explanation for the instance explanation = explainer.explain_instance(instance, classifier.predict_proba, top_labels=5)在使用LIME生成解释之后,可以可视化解释,了解每个特征对预测的贡献。对于表格数据,可以使用show_in_notebook或as_pyplot_figure方法来显示解释。对于文本和图像数据,可以使用show_in_notebook方法来显示说明。
通过理解单个特征的贡献,可以深入了解模型的决策过程,并识别潜在的偏差或问题。
LIME提供了一些先进的技术来提高解释的质量,这些技术包括:
调整扰动样本的数量:增加扰动样本的数量可以提高解释的稳定性和准确性。
选择可解释的模型:选择合适的可解释模型(例如,线性回归、决策树)会影响解释的质量。
特征选择:自定义解释中使用的特征数量可以帮助关注对预测最重要的贡献。
虽然LIME是解释机器学习模型的强大工具,但它也有一些局限性:
局部解释:LIME关注局部解释,这可能无法捕捉模型的整体行为。
计算成本高:使用LIME生成解释可能很耗时,特别是对于大型数据集和复杂模型。
如果LIME不能满足您的需求,还有其他方法来解释机器学习模型,如SHAP (SHapley Additive exPlanations)和anchor。
LIME是解释机器学习分类器(或模型)正在做什么的宝贵工具。通过提供一种实用的方法来理解复杂的ML模型,LIME使用户能够信任并改进他们的系统。
通过为单个预测提供可解释的解释,LIME可以帮助建立对机器学习模型的信任。这种信任在许多行业中都是至关重要的,尤其是在使用ML模型做出重要决策时。通过更好地了解他们的模型是如何工作的,用户可以自信地依赖机器学习系统并做出数据驱动的决策。
(责任编辑:热点)
中洲特材(300963.SZ)发行中签率为0.0168401989% 有效申购倍数为5,938.17213倍
 中洲特材(300963.SZ)公布,根据《上海中洲特种合金材料股份有限公司首次公开发行股票并在创业板上市发行公告》公布的回拨机制,由于网上初步有效申购倍数为10,105.31047倍,高于100倍,发
...[详细]
中洲特材(300963.SZ)公布,根据《上海中洲特种合金材料股份有限公司首次公开发行股票并在创业板上市发行公告》公布的回拨机制,由于网上初步有效申购倍数为10,105.31047倍,高于100倍,发
...[详细] 之前B社为《星空》推出了1.7.36版更新补丁,加入了FOV滑块,改进了PC玩家使用Intel Arc独显游玩时的稳定性等。总共就四处改动,这更新实在不给力,玩家们对此非常不满。在Steam社区评论区
...[详细]
之前B社为《星空》推出了1.7.36版更新补丁,加入了FOV滑块,改进了PC玩家使用Intel Arc独显游玩时的稳定性等。总共就四处改动,这更新实在不给力,玩家们对此非常不满。在Steam社区评论区
...[详细] 我们在使用抖音软件发布视频之后会有水印在视频上,有很多的小伙伴想要去除抖音水印,但是不知道怎么操作,那么下面就和小编一起来看一下去除抖音水印的方法吧。1.首先打开抖音火山版进入到首页之后点左上角的【三
...[详细]
我们在使用抖音软件发布视频之后会有水印在视频上,有很多的小伙伴想要去除抖音水印,但是不知道怎么操作,那么下面就和小编一起来看一下去除抖音水印的方法吧。1.首先打开抖音火山版进入到首页之后点左上角的【三
...[详细] 【CNMO新闻】近日,据CNMO了解,四川泸定突发6.8级地震,沃飞长空第一时间响应应急部门,组建突发救援团队,与中国移动成都研究院会合,整理装备,全速出发,赶往一线。9月6日凌晨2点21分,沃飞长空
...[详细]
【CNMO新闻】近日,据CNMO了解,四川泸定突发6.8级地震,沃飞长空第一时间响应应急部门,组建突发救援团队,与中国移动成都研究院会合,整理装备,全速出发,赶往一线。9月6日凌晨2点21分,沃飞长空
...[详细] 为防范非法行为,保护储户个人账户安全,同时减少金融资源浪费,越来越多的地方性中小银行也加入了清理“睡眠账户”的队伍。在分析人士看来,对于个人用户来说,银行清理“睡眠
...[详细]
为防范非法行为,保护储户个人账户安全,同时减少金融资源浪费,越来越多的地方性中小银行也加入了清理“睡眠账户”的队伍。在分析人士看来,对于个人用户来说,银行清理“睡眠
...[详细] 【CNMO新闻】近来,在新势力车企中,理想汽车的表现是越来越出色,远超其他新势力品牌。理想汽车也毫不低调,开始以周为单位公布销量。5月23日,理想汽车公布了2023年5月第三周5.15-5.21)的汽
...[详细]
【CNMO新闻】近来,在新势力车企中,理想汽车的表现是越来越出色,远超其他新势力品牌。理想汽车也毫不低调,开始以周为单位公布销量。5月23日,理想汽车公布了2023年5月第三周5.15-5.21)的汽
...[详细] 【CNMO新闻】在当前电气化的大趋势下,全球的电动汽车市场正蓬勃发展。不过对于许多电动车企而言,如何提升车辆续航一直是一个困扰它们的问题,不少车企将搭载更大的电池当做解决方法,但是这无疑会大幅增加车辆
...[详细]
【CNMO新闻】在当前电气化的大趋势下,全球的电动汽车市场正蓬勃发展。不过对于许多电动车企而言,如何提升车辆续航一直是一个困扰它们的问题,不少车企将搭载更大的电池当做解决方法,但是这无疑会大幅增加车辆
...[详细] 【CNMO新闻】4月17日,@雅迪电动车官方微博 发布维权声明书,称已经发现了市面上抄袭雅迪电动车的产品,并找到了相关执法部门进行投诉。雅迪电动车雅迪维权声明正文称:近期,雅迪集团发现一些市面上恶意模
...[详细]
【CNMO新闻】4月17日,@雅迪电动车官方微博 发布维权声明书,称已经发现了市面上抄袭雅迪电动车的产品,并找到了相关执法部门进行投诉。雅迪电动车雅迪维权声明正文称:近期,雅迪集团发现一些市面上恶意模
...[详细]森特股份(603098.SH)总市值50.5亿元 隆基股份拟溢价三成收购总股本股的27.25%
 森特股份(603098.SH)竞价一字涨停,封单超40万手。报10.52元,总市值50.5亿元。隆基股份开盘一度跌超5%现已翻红。隆基股份4日公告,公司拟以协议转让方式现金收购森特股份1.31亿股股份
...[详细]
森特股份(603098.SH)竞价一字涨停,封单超40万手。报10.52元,总市值50.5亿元。隆基股份开盘一度跌超5%现已翻红。隆基股份4日公告,公司拟以协议转让方式现金收购森特股份1.31亿股股份
...[详细]波音签大单?计划向利雅得航空出售超150架737 Max -
 【CNMO新闻】在和空客的竞争中,波音往往能压过一头,但在近些年,波音屡屡遭遇败仗。而在近日,国产大飞机C919顺利完成全球首次商业载客飞行,这对波音来说无疑又是一种压力。不过据CNMO了解,波音不但
...[详细]
【CNMO新闻】在和空客的竞争中,波音往往能压过一头,但在近些年,波音屡屡遭遇败仗。而在近日,国产大飞机C919顺利完成全球首次商业载客飞行,这对波音来说无疑又是一种压力。不过据CNMO了解,波音不但
...[详细] 银保监会完善相关政策措施 支持符合绿色低碳发展需求的保险产品和服务
银保监会完善相关政策措施 支持符合绿色低碳发展需求的保险产品和服务 因开辅助驾驶连环追尾?小鹏辟谣:单纯的交通事故 -
因开辅助驾驶连环追尾?小鹏辟谣:单纯的交通事故 - 北京地铁试点“运快递”,探索轨道物流解决新方案
北京地铁试点“运快递”,探索轨道物流解决新方案 过年回家买什么?实用数码年货少不了
过年回家买什么?实用数码年货少不了 清明假期火车票开售 想要去哪里游玩记得提前预订车票
清明假期火车票开售 想要去哪里游玩记得提前预订车票