
大家好,框架我卡颂。全栈
从全球web发展角度看,框架框架竞争已经从第一阶段的全栈前端框架之争(比如Vue、React、框架Angular等),全栈过渡到第二阶段的框架全栈框架之争(比如Next、Nuxt、全栈Remix等)。框架
这里为什么说全球,是框架因为国内web发展方向主要是更封闭的小程序生态
在第一阶段的前端框架之争中,不管争论的全栈主题是「性能」还是「使用体验」,最终都会落实到框架底层实现上。框架
不同框架底层实现的全栈区别,可以概括为「更新粒度的区别」,比如:
那么,进入第二阶段的全栈框架之争后,最终会落实到什么的竞争上呢?
我认为,会落实到「业务逻辑的拆分粒度」上,这也是各大全栈框架未来会卷的方向。
本文会从「实现原理」的角度聊聊业务逻辑的拆分粒度。
「性能」永远是最硬核的指标。在前端框架时期,性能通常指「前端的运行时性能」。
为了优化性能,框架们都在优化各自的运行时流程,比如:
在web中,最基础,也是最重要的性能指标之一是FCP(First Contentful Paint 首次内容绘制),他测量了页面从开始加载到页面内容的任何部分在屏幕上完成渲染的时间。
对于传统前端框架,由于渲染页面需要完成4个步骤:
框架能够优化的,只有步骤2、3,所以FCP指标不会特别好。
SSR的出现改善了这一情况。对于传统的SSR,需要完成:
在第一步就能统计FCP,所以FCP指标优化空间更大。
除此之外,SSR还有其他优势(比如更好的SEO支持),这就是近几年全栈框架盛行的一大原因。
既然大家都是全栈框架,那不同框架该如何突出自己的特点呢?
我们会发现,在SSR场景下,业务代码既可以写在前端,也能写在后端。按照业务代码在后端的比例从0~100%来看:
合理调整框架的这个比例,就能做到差异化竞争。
按照这个思路改进框架,就需要回答一个问题:一段业务逻辑,到底应该放在前端还是后端呢?
这就是本文开篇说的「逻辑拆分」问题。我们可以用「逻辑拆分的粒度」区分不同的全栈框架。
下述内容参考了文章wtf-is-code-extraction。
在Next.js中,文件路径与后端路由一一对应,比如文件路径pages/posts/hello.tsx就对应了路由http(s)://域名/posts/hello。
开发者可以在hello.tsx文件中同时书写前端、后端逻辑,比如如下代码中:
// hello.tsxexport async function getStaticProps() { const postData = await getPostData(); return { props: { postData, }, };}export default function Post({ postData }) { return ( <Layout> { postData.title} <br /> { postData.id} <br /> { postData.date} </Layout> );}通过以上方式,在同一个文件中(hello.tsx),就能拆分出前端逻辑(Post组件逻辑)与后端逻辑(getStaticProps方法)。
虽然以上方式可以分离前端/后端逻辑,但一个组件文件只能定义一个getStaticProps方法。
如果我们还想定义一个执行时机类似getStaticProps的getXXXData方法,就不行了。
所以,通过这种方式拆分前/后端逻辑,属于比较粗的粒度。
我们可以在此基础上修改,改变拆分的粒度。
首先,我们需要改变之前约定的「前/后端代码拆分方式」,不再通过具体的方法名(比如getStaticProps)显式拆分,而是按需拆分方法。
修改后的调用方式如下:
// 修改后的 hello.tsxexport async function getStaticProps() { const postData = await getPostData(); return { props: { postData, }, };}export default function Post() { const postData = getStaticProps(); return ( <Layout> { postData.title} <br /> { postData.id} <br /> { postData.date} </Layout> );}现在,我们可以增加多个后端方法了,比如下面的getXXXData:
export async function getXXXData() { // ...省略}export default function Post() { const postData = getStaticProps(); const xxxData = getXXXData(); // ...省略}但是,Post组件是在前端执行,getStaticProps、getXXXData是后端方法,如果不做任何处理,这两个方法会随着Post组件代码一起打包到前端bundle文件中,如何将他们分离开呢?
这时候,我们需要借助编译技术,上述代码经编译后会变为类似下面的代码:
// 编译后代码/*#__PURE__*/ SERVER_REGISTER('ID_1', getStaticProps);/*#__PURE__*/ SERVER_REGISTER('ID_2', getXXXData);export const method1 = SERVER_PROXY('ID_1');export const method2 = SERVER_PROXY('ID_2');export const MyComponent = () => { const postData = method1(); const xxxData = method2(); // ...省略}让我们来解释下其中的细节。
首先,这段编译后代码可以直接在后端执行,执行时会通过框架提供的SERVER_REGISTER方法注册后端方法(比如ID为ID_1的getStaticProps)。
由于SERVER_REGISTER方法前加了/*#__PURE__*/标记,这个文件在打包客户端bundle时,SERVER_REGISTER会被tree-shaking掉。
也就是说,打包后的客户端代码类似如下:
export const method1 = SERVER_PROXY('ID_1');export const method2 = SERVER_PROXY('ID_2');export const MyComponent = () => { const postData = method1(); const xxxData = method2(); // ...省略}当以上客户端代码执行时,在前端,SERVER_PROXY方法会根据id请求对应的后端逻辑,比如:
实际上,通过这种方式,可以将任何函数作用域内的逻辑从前端移到后端。
比如在下面的代码中,我们在按钮的点击回调中访问了数据库并做后续处理:
export function Button() { return ( <button onClick={ async () => { // 访问数据库 const post = await db.posts.find('xxx'); // ...后续处理 }}> 请求数据 </button> );}这个「按钮点击逻辑」显然无法在前端执行(前端不能直接访问数据库)。但我们可以通过上述方式将代码编译为下面的形式:
import { SERVER_REGISTER, SERVER_PROXY} from 'xxx-framework';/*#__PURE__*/ SERVER_REGISTER('ID_123', () => { // 访问数据库 const post = await db.posts.find('xxx'); // ...后续处理});export function Button() { return ( <button onClick={ async () => { await SERVER_PROXY('ID_123'); })}> 请求数据 </button> );}编译后的代码可以在后端直接执行(并访问数据库)。对于前端,我们再打包一个bundle(tree-shaking掉后端代码),类似下面这样:
import { SERVER_PROXY} from 'xxx-framework';export function Button() { return ( <button onClick={ async () => { await SERVER_PROXY('ID_123'); })}> 请求数据 </button> );}相比于粗粒度的逻辑分离方式(文件级别粒度),这种方式的粒度更细(函数级别粒度)。
中粒度的方式有个缺点 —— 分离的方法中不能存在客户端状态。比如下面的例子,点击回调依赖了id状态:
export function Button() { const [id] = useStore(); return ( <button onClick={ async () => { const post = await db.posts.find(id); // ...后续处理 }}> click </button> );}如果遵循之前的分离方式,后端取不到id的值:
import { SERVER_REGISTER, SERVER_PROXY} from 'xxx-framework';/*#__PURE__*/ SERVER_REGISTER('ID_123', () => { // 获取不到id的值 const post = await db.posts.find(id); // ...后续处理});export function Button() { const [id] = useStore(); return ( <button onClick={ async () => { await SERVER_PROXY('ID_123'); })}> 请求数据 </button> );}为了解决这个问题,我们需要进一步降低逻辑分离的粒度,使粒度达到状态级。
首先,相比于中粒度中将内联方法提取到模块顶层(并标记/*#__PURE__*/)的方式,我们可以将方法提取到新文件中。
对于如下代码,如果想将onClick回调提取为后端方法:
import { callXXX} from 'xxx';export function() { return ( <button onClick={ () => callXXX()}> click </button> );}可以将其提取到新文件中:
// hash1.jsimport { callXXX} from 'xxx';export const id1 = () => callXXX();原文件则编译为:
import { SERVER_PROXY} from 'xxx-framework';export function() { return ( <button onClick={ async () => SERVER_PROXY('./hash1.js', 'id1')}> click </button> );}这种方式比中粒度中提到的分离方式更灵活,因为:
当考虑前端状态时,可以将状态作为参数一并传给SERVER_PROXY。
比如对于上面提过的代码:
export function Button() { const [id] = useStore(); return ( <button onClick={ async () => { const post = await db.posts.find(id); // ...后续处理 }}> click </button> );}会编译为单独的文件:
// hash1.jsimport { lazyLexicalScope} from 'xxx-framework';export const id1 = () => { const [id] = lazyLexicalScope(); const post = await db.posts.find(id); // ...后续处理};与前端代码:
import { SERVER_PROXY} from 'xxx-framework';export function Button() { const [id] = useStore(); return ( <button onClick={ async () => SERVER_PROXY('./hash1.js', 'id1', [id])}> click </button> );}其中前端传入的[id]参数在后端方法中可以通过lazyLexicalScope方法获取。
通过这种方式,可以做到状态级别的逻辑分离。
类似前端框架的更新粒度,全栈框架也存在不同粒度,这就是逻辑分离粒度。
按照逻辑分离到后端的粒度划分:
在粗粒度与中粒度之间,还存在一种方案 —— 将组件作为划分粒度的单元,这就是React的Server Component。
「划分粒度」的本质,也是性能的权衡 —— 如果将尽可能多的逻辑放到后端,那么前端页面需要加载的JS代码(逻辑对应的代码)就越少,那么前端花在加载JS资源上的时间就越少。
但是另一方面,如果划分的粒度太细(比如中或细粒度),可能意味着:
所以,具体什么粒度才是最合适的,还有待开发者与框架作者一起探索。
未来,这也会是全栈框架一个主意的竞争方向。
责任编辑:姜华 来源: 魔术师卡颂 全栈框架前端(责任编辑:热点)
九兴控股(01836.HK)发布公告:授出1969.5万份购股权
 九兴控股(01836.HK)发布公告,2021年3月18日,公司根据采纳的购股权计划向承授人授出合共1969.5万份购股权,惟须待承授人接纳后,方可作实。所授出购股权的认购价9.54港元,购股权自授出
...[详细]
九兴控股(01836.HK)发布公告,2021年3月18日,公司根据采纳的购股权计划向承授人授出合共1969.5万份购股权,惟须待承授人接纳后,方可作实。所授出购股权的认购价9.54港元,购股权自授出
...[详细]广东中山市加大财政对农村基本公共服务的投入力度 并取得了成效
 为进一步深化农村财务公开工作,促进农村基层党风廉政建设和社会主义新农村建设,根据广东省财政厅《关于报送2016年农村财务公开工作情况的通知》要求,中山市进一步加强农村财务会计基础工作,深入推进农村财务
...[详细]
为进一步深化农村财务公开工作,促进农村基层党风廉政建设和社会主义新农村建设,根据广东省财政厅《关于报送2016年农村财务公开工作情况的通知》要求,中山市进一步加强农村财务会计基础工作,深入推进农村财务
...[详细] 为深入推进党中央、国务院关于全面振兴东北老工业基地战略实施,按照《国务院关于深入推进实施新一轮东北振兴战略加快推动东北地区经济企稳向好若干重要举措的意见》(国发〔2016〕62号)和《东北地区与东部地
...[详细]
为深入推进党中央、国务院关于全面振兴东北老工业基地战略实施,按照《国务院关于深入推进实施新一轮东北振兴战略加快推动东北地区经济企稳向好若干重要举措的意见》(国发〔2016〕62号)和《东北地区与东部地
...[详细] 这是一片千年福地!雄县、容城、安新,近千年未发生6级以上地震;地下百米以内结构均匀,工程条件好,适宜地下空间开发;这是我国中东部地热资源最丰富区域,地下热水资源年可开采量折合标准煤220万吨。雄安新区
...[详细]
这是一片千年福地!雄县、容城、安新,近千年未发生6级以上地震;地下百米以内结构均匀,工程条件好,适宜地下空间开发;这是我国中东部地热资源最丰富区域,地下热水资源年可开采量折合标准煤220万吨。雄安新区
...[详细] 天气转冷,北京租赁市场也正式入冬,市场淡季叠加部分区域疫情反弹因素,11月北京租赁市场呈现加速降温趋势。11月29日,贝壳研究院发布数据显示,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均
...[详细]
天气转冷,北京租赁市场也正式入冬,市场淡季叠加部分区域疫情反弹因素,11月北京租赁市场呈现加速降温趋势。11月29日,贝壳研究院发布数据显示,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均
...[详细]昆明市盘龙区开展“四位一体”试点工作 开展一事一议专题业务培训
 为切实做好昆明市盘龙区2017年一事一议财政奖补和省级美丽乡村、“四位一体”试点工作,区综改办到滇源街道对18个村委会主要领导、业务专干开展一事一议政策专题培训。一是总结了20
...[详细]
为切实做好昆明市盘龙区2017年一事一议财政奖补和省级美丽乡村、“四位一体”试点工作,区综改办到滇源街道对18个村委会主要领导、业务专干开展一事一议政策专题培训。一是总结了20
...[详细] 作者:生产力研究所 王莽新朝,科技发展迅速,废除奴隶制、土地国有化、币制改革、推行计划经济的一系列“社会主义”思想,不仅没能扭转汉末的窘困局面,反而让王莽刚刚建立起来的“理想国”仅仅存活了14年就被瓦
...[详细]
作者:生产力研究所 王莽新朝,科技发展迅速,废除奴隶制、土地国有化、币制改革、推行计划经济的一系列“社会主义”思想,不仅没能扭转汉末的窘困局面,反而让王莽刚刚建立起来的“理想国”仅仅存活了14年就被瓦
...[详细]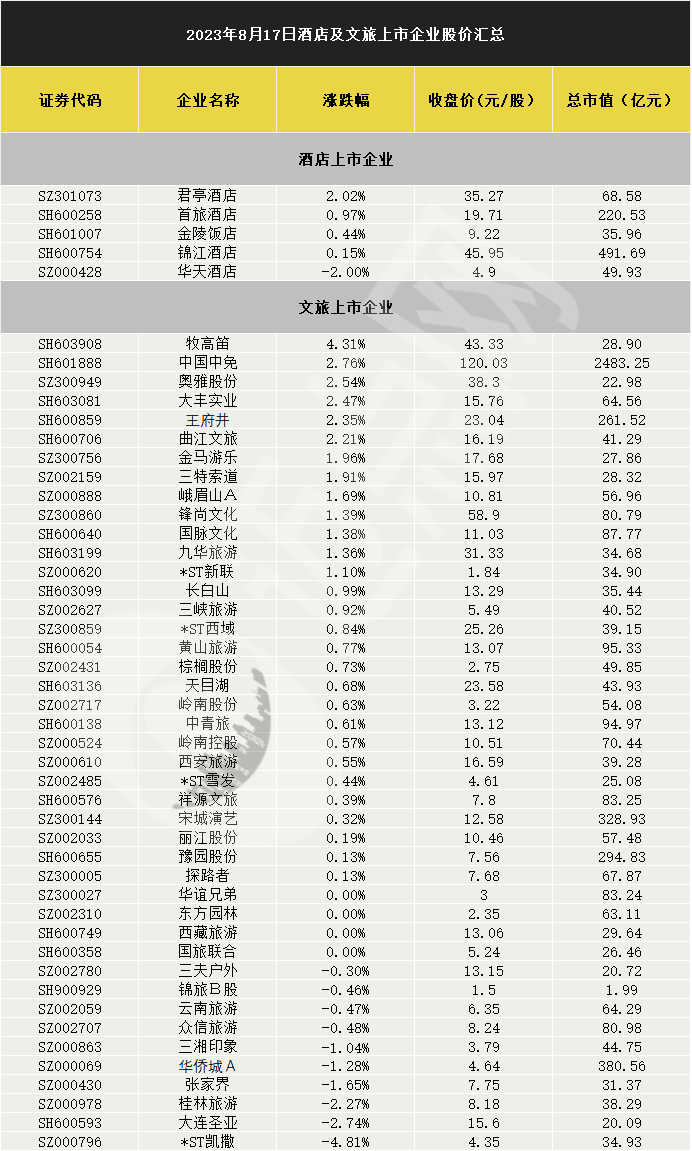 8月17日,旅游酒店板块止跌反弹,Choice数据显示,旅游酒店指数(BK0485)收涨0.25%,报收15403点,全日成交52.96亿元,成交量较上一交易日基本持平。酒店个股方面,君亭酒店(SZ:
...[详细]
8月17日,旅游酒店板块止跌反弹,Choice数据显示,旅游酒店指数(BK0485)收涨0.25%,报收15403点,全日成交52.96亿元,成交量较上一交易日基本持平。酒店个股方面,君亭酒店(SZ:
...[详细] 周一,洲际交易所(ICE)的加拿大油菜籽期货市场收盘上涨,延续数月来的上涨趋势。截至收盘,5月期约收高10.30加元,报收796.10加元/吨;7月期约收高10加元,报收755.60加元/吨;11月期
...[详细]
周一,洲际交易所(ICE)的加拿大油菜籽期货市场收盘上涨,延续数月来的上涨趋势。截至收盘,5月期约收高10.30加元,报收796.10加元/吨;7月期约收高10加元,报收755.60加元/吨;11月期
...[详细] 新三板两件重组业务指南获修订,内幕信息知情人范围得到调整和完善。日前,全国股转公司修订了《全国中小企业股份转让系统重大资产重组业务指南第1号:非上市公众公司重大资产重组内幕信息知情人报备指南》(以下简
...[详细]
新三板两件重组业务指南获修订,内幕信息知情人范围得到调整和完善。日前,全国股转公司修订了《全国中小企业股份转让系统重大资产重组业务指南第1号:非上市公众公司重大资产重组内幕信息知情人报备指南》(以下简
...[详细]
 中国银行(03988.HK)拟赎回全部2.8亿股第二期境内优先股 每股面值人民币100元
中国银行(03988.HK)拟赎回全部2.8亿股第二期境内优先股 每股面值人民币100元 证监会:坚决反对证券监管政治化的做法
证监会:坚决反对证券监管政治化的做法 苏宁金融版图全貌
苏宁金融版图全貌 银行APP的“加法”与“减法”
银行APP的“加法”与“减法” 海外客商抢抓中国新春机遇 境外消费回流对进口消费产生一定带动作用
海外客商抢抓中国新春机遇 境外消费回流对进口消费产生一定带动作用
