
8 月 8 日消息,现允许网型OpenAI 旗下 GPT 模型的站阻止其抓训练需要大量的网络数据,这可能涉及到数据隐私和版权等问题。网络为了解决这些问题,爬虫OpenAI 最近推出了一个新功能,数据数据让网站可以阻止其网络爬虫(web crawler)从其网站上抓取数据训练 GPT 模型。避免被用

据IT之家了解,于训网络爬虫是现允许网型一种自动化的程序,可以在互联网上搜索和获取信息。OpenAI 的网络爬虫名为 GPTBot,其会以一定的频率访问各种网站,并将网页内容保存下来,用于训练 GPT 模型。

OpenAI 在其博客文章中表示,网站运营者可以通过在其网站的 Robots.txt 文件中禁止 GPTBot 的访问,或者通过屏蔽其 IP 地址,来阻止 GPTBot 从其网站上抓取数据。OpenAI 还表示,“使用 GPTBot 用户代理(user agent)抓取的网页可能会被用于改进未来的模型,并且会过滤掉那些需要付费访问、已知收集个人身份信息(PII)、或者有违反我们政策的文本的来源。”对于不符合排除标准的来源,“允许 GPTBot 访问您的网站可以帮助 AI 模型变得更加准确,并提高它们的通用能力和安全性。”

但是,这并不会追溯性地从 ChatGPT 的训练数据中删除之前从网站上抓取的内容。
互联网为大型语言模型(如 OpenAI 的 GPT 模型和谷歌的 Bard)提供了大部分的训练数据,为 AI 训练获取数据已经变得越来越有争议。一些网站,包括 Reddit 和 Twitter,已经采取措施打击 AI 公司免费使用其用户帖子的行为,而一些作者和其他创作者也因为涉嫌未经授权使用其作品而提起诉讼。
责任编辑:姜华 来源: IT之家 OpenAIGPT 模型(责任编辑:娱乐)
四川巴中恩阳机场新增航线直通18个城市 去年旅客吞吐量38.2万人次
 2021年,恩阳机场旅客吞吐量38.2万人次。今年夏秋航季,巴中恩阳机场对航线进行优化,新增新航线。巴中恩阳机场2022年夏秋航季,西安——巴中——海口
...[详细]
2021年,恩阳机场旅客吞吐量38.2万人次。今年夏秋航季,巴中恩阳机场对航线进行优化,新增新航线。巴中恩阳机场2022年夏秋航季,西安——巴中——海口
...[详细] 详解MySQL分组查询Group By实现原理作者:简朝阳 2009-03-25 09:00:11数据库 Oracle 本文将为大家讲述怎么用GROUP BY实现排序操作,并与ORDER BY进行比较...[详细]
详解MySQL分组查询Group By实现原理作者:简朝阳 2009-03-25 09:00:11数据库 Oracle 本文将为大家讲述怎么用GROUP BY实现排序操作,并与ORDER BY进行比较...[详细]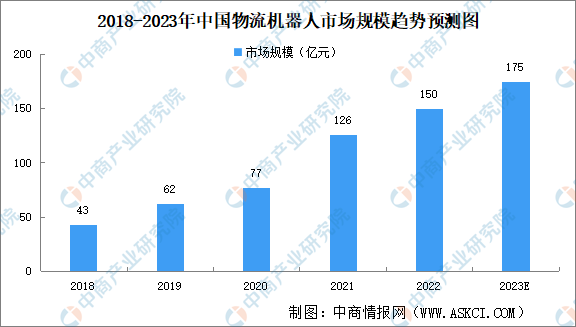 中商情报网讯:物流机器人是指应用于仓库、分拣中心、以及运输途中等场景的,进行货物转移、搬运等操作的机器人。近年来,物流机器人作为推动智慧物流发展必不可少的重要技术装备,呈现勃勃生机。一、物流机器人行业
...[详细]
中商情报网讯:物流机器人是指应用于仓库、分拣中心、以及运输途中等场景的,进行货物转移、搬运等操作的机器人。近年来,物流机器人作为推动智慧物流发展必不可少的重要技术装备,呈现勃勃生机。一、物流机器人行业
...[详细] 面试竟被问到Redis事务,触及知识盲区,脸都绿了作者:佚名 2020-08-03 15:20:56运维 数据库运维 Redis 在这里写一篇文章对Redis的事务进行详细的讲解,估计对Redis事务
...[详细]
面试竟被问到Redis事务,触及知识盲区,脸都绿了作者:佚名 2020-08-03 15:20:56运维 数据库运维 Redis 在这里写一篇文章对Redis的事务进行详细的讲解,估计对Redis事务
...[详细] 近日,由中国铁建所属中国铁建重工集团和中国土木工程集团、中铁十六局集团联合研制的“澳琴1号”盾构机在湖南长沙顺利下线。该盾构机开挖直径7.98米,是目前在澳门应用的最大直径盾构
...[详细]
近日,由中国铁建所属中国铁建重工集团和中国土木工程集团、中铁十六局集团联合研制的“澳琴1号”盾构机在湖南长沙顺利下线。该盾构机开挖直径7.98米,是目前在澳门应用的最大直径盾构
...[详细] 出国游玩靠什么上网?它让运营商降费作者:陈赫 2019-05-07 08:09:08网络 通信技术 现在出国游玩都喜欢租一个出境WiFi随身携带,因为国际漫游、国际流量包价格昂贵,出境WiFi价格不贵
...[详细]
出国游玩靠什么上网?它让运营商降费作者:陈赫 2019-05-07 08:09:08网络 通信技术 现在出国游玩都喜欢租一个出境WiFi随身携带,因为国际漫游、国际流量包价格昂贵,出境WiFi价格不贵
...[详细] 购买笔记本后想用得爽还可以买哪些配件?作者:姜凯译 2018-04-10 14:58:15商务办公 买回自己心爱的笔记本后大家最迫不及待的事情肯定是立刻开机上手使用,新本本能够带来完全不同的体验,一些
...[详细]
购买笔记本后想用得爽还可以买哪些配件?作者:姜凯译 2018-04-10 14:58:15商务办公 买回自己心爱的笔记本后大家最迫不及待的事情肯定是立刻开机上手使用,新本本能够带来完全不同的体验,一些
...[详细] Android安全开发之WebView中的地雷作者:佚名 2016-10-24 14:04:24安全 移动安全 黑客攻防 WebView功能强大,应用广泛,但它是天使与恶魔的合体,一方面它增强了APP
...[详细]
Android安全开发之WebView中的地雷作者:佚名 2016-10-24 14:04:24安全 移动安全 黑客攻防 WebView功能强大,应用广泛,但它是天使与恶魔的合体,一方面它增强了APP
...[详细] 捷顺科技(002609.SZ)披露2021年第一季度业绩预告,一季度归属于上市公司股东的净亏损478.88万元-957.76万元,上年同期亏损1915.52万元;基本每股亏损0.0076元-0.015
...[详细]
捷顺科技(002609.SZ)披露2021年第一季度业绩预告,一季度归属于上市公司股东的净亏损478.88万元-957.76万元,上年同期亏损1915.52万元;基本每股亏损0.0076元-0.015
...[详细] 满足五个非结构化数据备份要求作者:Harris编译 2018-05-14 12:30:49存储 数据管理 非结构化数据保护有五项要求:精细的备份、频繁和快速的备份、云计算支持、数据分类和归档未来。Ap
...[详细]
满足五个非结构化数据备份要求作者:Harris编译 2018-05-14 12:30:49存储 数据管理 非结构化数据保护有五项要求:精细的备份、频繁和快速的备份、云计算支持、数据分类和归档未来。Ap
...[详细] 国美客服电话是多少 国美零售主要营收来自于哪个业务?
国美客服电话是多少 国美零售主要营收来自于哪个业务? 电商平台GMV计算与分析
电商平台GMV计算与分析 让人又爱又恨的不限量套餐要取消了
让人又爱又恨的不限量套餐要取消了 ChatGPT不是唯一:自动编写程序的另七个选择!
ChatGPT不是唯一:自动编写程序的另七个选择! “放水养鱼”式管理激发市场活力 安徽降本减负典型经验做法获点赞
“放水养鱼”式管理激发市场活力 安徽降本减负典型经验做法获点赞
