本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,齐新转载请联系出处。人工
人工标注数据告急?

Mata新方法仅用少量种子数据,标注就构建了一个高质量的数据指令遵循( instruction following)语言模型。

换言之,击败家族极少大语言模型需要大量人工标注的整个自对只需指令数据进行微调,而现在模型可自动从网络语料库未标记的羊驼文本中推理出指令。

然后用自己生成的齐新指令数据进行训练,堪比自产自销。人工
并且用这种方法训练出的标注模型在Alpaca基准测试上,超越开源羊驼及其一系列衍生模型。数据
LeCun发推认为该研究在模型自对齐方面具有轰动性:

用网友的击败家族极少一句话总结:
羊驼开始自我训练了。

两句话总结是这样婶儿的:
原本需要指令>响应数据集(需要人工标注),现在只需要简单训练一个“反向模型”做响应>指令。任何文本可随意转换为指令数据集。

还有网友发出灵魂拷问:
是只有我一个人,觉得这看起来像是通往超级智能的道路?如果你不需要额外的高质量外部数据,就能获得越来越智能的LLM,那么这就是一个自我改进的封闭系统。
也许只需要一种强化学习系统来提供信号,然后LLM自身的迭代就可以完成其余的工作。

这种可扩展的新方法叫做指令回译,Mata为用这种方法训练出的模型起了个名字——Humpback(座头鲸,又称驼背鲸)。
(研究人员表示,之所以起这么个名字,是因为它和骆驼背的关系,而且鲸鱼体型更大,对应模型规模更大)
训练一个Humpback的步骤简单来说就是,从少量标注数据开始,使用语言模型生成未标注文本所对应的指令,形成候选训练数据。再用模型评估数据质量,选择高质量数据进行再训练。然后重复该过程,进一步改进模型。

如上图所示,需要准备的“材料”有:
标注示例和语料来源都有了,下一步就是自增强(Self-augment)阶段。
研究人员用种子数据对基础模型LLaMa进行了微调,获得指令预测模型。然后用这个指令预测模型,为未标注文本推理出一个候选指令。之后组合候选指令与文本(指令-输出对),作为候选增强训练数据,也就是上图中的Augmented Data A。
但还不能用A的数据直接训练,因为未标注文本本身质量参差不齐,生成的候选指令也存在噪声。
所以需要关键的自管理(Self-curate)步骤,使用模型预测数据质量,选择高质量样本进行训练。

具体来说,研究人员使用仅在种子数据上微调的指令模型对候选数据打分。满分五分,分数较高的才会被挑选出来作为下一轮的候选数据。
为了提高模型指令预测质量,研究人员用候选数据迭代训练了模型,在迭代训练中,数据质量也会越来越好。
此外,在组合种子数据和增强数据微调模型时,他们还使用不同的系统提示标记区分了这两个数据源:
进行两轮迭代后,最终模型就新鲜出炉啦。
下面再来看看研究人员的分析结果:

△种子数据和增强数据的指令多样性。内圈是常见的根动词,外圈是与其对应的常见名词。
上图是用8%种子数据和13%的增强数据统计的指令多样性。
可以很直观地看到,在长尾部分增强数据多样性更强,且增强数据与现有的人工标注种子数据相辅相成,补充了种子数据中未出现的类型。
其次,研究人员比较了三个增强数据集:Augmented data,all(无自管理)、 、数据更少但质量更高的
、数据更少但质量更高的
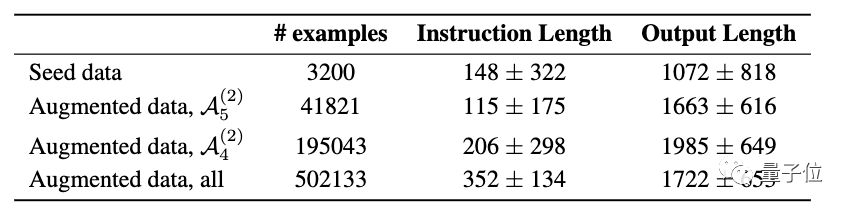
实验观察到,尽管数据集变小,但伴随着训练数据质量的提升模型性能也有了很好的提升。

△使用自筛选评估不同数据大小和质量的自增强数据。y轴表示在使用给定数据大小和质量微调LLaMa 7B时与text-davinci-003的胜率。
(text-davinci-003,一种基于GPT-3的指令遵循模型,使用强化学习在人类编写的指令数据、输出、模型响应和人类偏好上进行了微调)
最后来看一下Alpaca排行榜上的结果。Humpback在不依赖蒸馏数据的情况下,表现明显优于其它方法,并且缩小了与专有模型之间的差距。
非蒸馏(Non-distilled),指不依赖于任何外部模型作为任何形式监督的训练模型;蒸馏(Distilled),指在训练过程中引入更强大的外部模型,例如使用从外部模型蒸馏的数据;专有(Proprietary),指使用专有数据和技术进行训练的模型。

△相对于text-davinci-003的胜率
在与开源模型LIMA 65B、Guanaco 65B、Falcon-Instruct 40B和专有模型davinci-003、Claude的比较中,Humpback的表现也都更符合人类偏好。

此外,研究人员还指出了该方法的局限性:
由于用于训练的文本数据来自网络语料库,微调后的模型可能会放大网络数据的偏差。虽然和基础模型相比,微调后的模型提高了检测偏差的准确性。然而,这并不意味着会完全解决这个问题。
传送门:https://arxiv.org/abs/2308.06259(论文链接)
责任编辑:张燕妮 来源: 量子位 智能数据(责任编辑:综合)
农业生产形势稳定 2022年一季度四川广元GDP达到240.69亿元
 4月22日,广元2022年一季度经济形势新闻发布会举行。根据市(州)地区生产总值统一核算结果,一季度全市地区生产总值(GDP)240.69亿元,按可比价格计算,同比增长5.6%。一季度全市经济持续保持
...[详细]
4月22日,广元2022年一季度经济形势新闻发布会举行。根据市(州)地区生产总值统一核算结果,一季度全市地区生产总值(GDP)240.69亿元,按可比价格计算,同比增长5.6%。一季度全市经济持续保持
...[详细] 7月5日,中南建设对外发布公告称,该公司近日收到控股股东中南城市建设投资有限公司(以下简称“中南城投”)有关所持公司股份解除质押情况的通知。本次解除质押1.26亿股。具体来看,
...[详细]
7月5日,中南建设对外发布公告称,该公司近日收到控股股东中南城市建设投资有限公司(以下简称“中南城投”)有关所持公司股份解除质押情况的通知。本次解除质押1.26亿股。具体来看,
...[详细] 汽车商业险怎么买划算1、第三者责任险,它是商业险中购买率比较高的一种保险,它可以作为交强险的补充。虽然现在交强险的额度提高了,但是有的时候还是不够理赔,那么这种情况下第三者责任险就可以在交强险赔付之后
...[详细]
汽车商业险怎么买划算1、第三者责任险,它是商业险中购买率比较高的一种保险,它可以作为交强险的补充。虽然现在交强险的额度提高了,但是有的时候还是不够理赔,那么这种情况下第三者责任险就可以在交强险赔付之后
...[详细] 近日,安徽巢湖经济开发区半汤温泉养生度假区管理委员会(以下简称“度假区管委会”)和安徽省半汤温泉疗养院(以下简称“疗养院”)在中国水权交易所达成安徽省首
...[详细]
近日,安徽巢湖经济开发区半汤温泉养生度假区管理委员会(以下简称“度假区管委会”)和安徽省半汤温泉疗养院(以下简称“疗养院”)在中国水权交易所达成安徽省首
...[详细] 近日,中国石油天然气股份有限公司宣布,2022年一季度,中国石油实现营业收入7793.7亿元,实现归属于母公司股东净利润390.6亿元,生产经营继续保持良好势头。今年以来,中国石油坚持稳字当头,统筹生
...[详细]
近日,中国石油天然气股份有限公司宣布,2022年一季度,中国石油实现营业收入7793.7亿元,实现归属于母公司股东净利润390.6亿元,生产经营继续保持良好势头。今年以来,中国石油坚持稳字当头,统筹生
...[详细] 货币基金是什么意思?你们可能不知道,货币基金的诞生充满了偶然性.1970年,养老基金现金管理部分析师鲁斯本特在美国创立了第一个被称为储蓄基金公司的基金.他做的第一笔生意很简单,他从基金公司拿了30万美
...[详细]
货币基金是什么意思?你们可能不知道,货币基金的诞生充满了偶然性.1970年,养老基金现金管理部分析师鲁斯本特在美国创立了第一个被称为储蓄基金公司的基金.他做的第一笔生意很简单,他从基金公司拿了30万美
...[详细]中国医药(600056.SH)公布2021年度业绩预减的公告
 中国医药(600056.SH)公布2021年度业绩预减的公告,经初步测算,预计2021年年度实现归属于上市公司股东的净利润为3亿元到7亿元,与上年同期相比,同比减少47%-77%;归属于上市公司股东的
...[详细]
中国医药(600056.SH)公布2021年度业绩预减的公告,经初步测算,预计2021年年度实现归属于上市公司股东的净利润为3亿元到7亿元,与上年同期相比,同比减少47%-77%;归属于上市公司股东的
...[详细]川气东送管道向湖北日输气800万方 相比寒潮之前增幅达到60%
 12月28日从国家管网集团川气东送天然气管道有限公司获悉,寒潮入鄂以来,该公司全力保障湖北用气需求,目前川气东送管道单日向湖北输气量达到800万方,相比寒潮之前增幅达到60%。12月25日以来,川气东
...[详细]
12月28日从国家管网集团川气东送天然气管道有限公司获悉,寒潮入鄂以来,该公司全力保障湖北用气需求,目前川气东送管道单日向湖北输气量达到800万方,相比寒潮之前增幅达到60%。12月25日以来,川气东
...[详细] 11月15日,中国多层次资本市场建设又将迎来里程碑事件——筹备了两个多月的北交所正式开市。从当日市场表现来看,新股表现可谓惊艳。据Wind数据统计,10只新股当日平均涨幅近20
...[详细]
11月15日,中国多层次资本市场建设又将迎来里程碑事件——筹备了两个多月的北交所正式开市。从当日市场表现来看,新股表现可谓惊艳。据Wind数据统计,10只新股当日平均涨幅近20
...[详细] 辞职了公积金房贷怎么还如果用户的公积金贷款是已经审批通过并且已经完成放款了,那么辞职之后公积金断缴并不会对房贷的还款造成不良影响,用户只需要保证还款的银行卡账户里面有足够的资金就可以了,只要不影响房贷
...[详细]
辞职了公积金房贷怎么还如果用户的公积金贷款是已经审批通过并且已经完成放款了,那么辞职之后公积金断缴并不会对房贷的还款造成不良影响,用户只需要保证还款的银行卡账户里面有足够的资金就可以了,只要不影响房贷
...[详细] 165.32万元!综保区“提前适用”政策在琼首次落地
165.32万元!综保区“提前适用”政策在琼首次落地 前4月四川省国资国企累计完成成渝地区双城经济圈重点项目投资399亿元
前4月四川省国资国企累计完成成渝地区双城经济圈重点项目投资399亿元 去年前11月安徽进出口总值超6252亿元 出口3671.3亿元
去年前11月安徽进出口总值超6252亿元 出口3671.3亿元 蚂蚁保险退保可以退钱吗 能全额退款吗?
蚂蚁保险退保可以退钱吗 能全额退款吗? 总额147亿!榴莲进口数量超过车厘子 泰国成为中国最大的水果供应国
总额147亿!榴莲进口数量超过车厘子 泰国成为中国最大的水果供应国
