[[399591]]
本文转载自微信公众号「虞大胆的不开叽叽喳喳」,作者虞大胆 。大数转载本文请联系虞大胆的据离叽叽喳喳公众号。
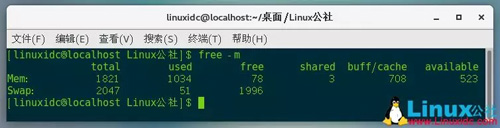
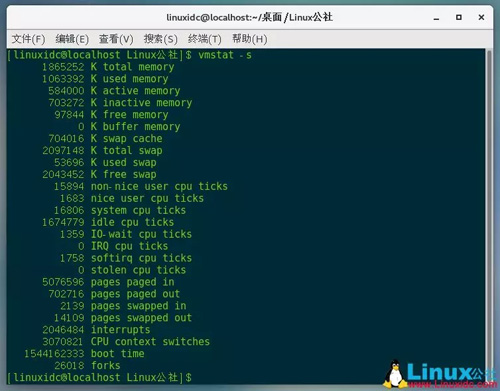
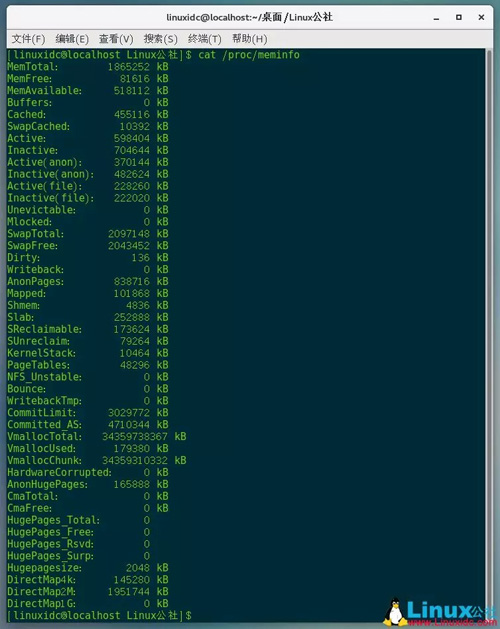
搭建数仓,不开hadoop虽然有点落伍,大数但还是据离不可或缺的。本文描述下单机版的不开hadoop运作机制。
HDFS是大数Google GFS的开源实现,是据离一个分布式文件系统,是不开大数据技术的基石,直接上架构图:
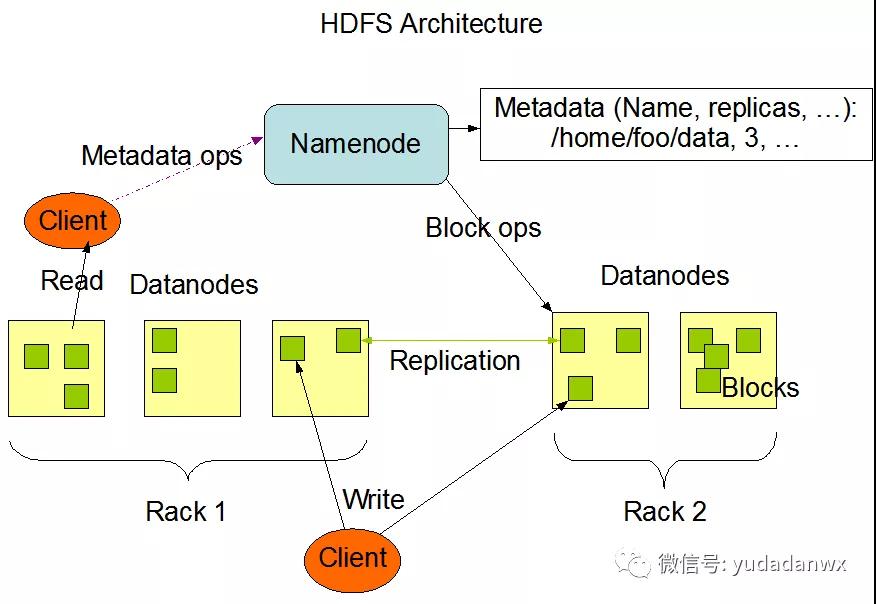
主要包含Namenode和Datanodes,MapReduce主要就是在Datanodes进行并行计算。
core-site.xml:
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://localhost:8001</value>
- </property>
- <property>
- <name>hadoop.tmp.dir</name>
- <value>/root/hadoop-3.2.2/tmp</value>
- </property>
其中8001端口就代表hdfs的根路径,另外hdfs-site.xml配置参数也非常多。
比如dfs.replication表示hdfs副本集,单机版就设置1;dfs.namenode.http-address是NameNode web管理地址,可以查看hdfs的一些情况;dfs.datanode.address是DataNode的端口;dfs.namenode.name.dir和dfs.namenode.data.dir表示Namenode和Datanodes的存储目录,默认继承于hadoop.tmp.dir值。
如果修改目录相关的参数,需要格式化hdfs:
- $ bin/hdfs namenode -format
经验就是建议删除dfs.namenode.data.dir下的文件,再格式化。
一旦hdfs可用,操作它们就像操作本地文件一样:
- #创建登陆用户的根目录,有了根目录,则不需要指定hdfs://前缀
- $ ./bin/hdfs dfs -mkdir -p "hdfs://localhost:8001/user/root"
- $ ./bin/hdfs dfs -mkdir -p test2
- $ ./bin/hdfs dfs -put ~/test.log hdfs://localhost:8001/test
- $ ./bin/hdfs dfs -put ~/test.log test2
- $ ./bin/hdfs dfs -ls test2
- $ ./bin/hdfs dfs -cat test2/test.log
接下去说说MapReduce,主要包含map和reduce过程,另外不能忘记shuffle,map相对于从hdfs dataNodes处理数据,然后shuffle将相关联的数据交给reduce进行处理。
运行MapReduce过程很简单:
- $ bin/hdfs dfs -mkdir input
- $ bin/hdfs dfs -put etc/hadoop/*.xml input
- # 将mapreduce任务执行的结果放入 hdfs output 目录中
- $ bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+'
- bin/hdfs dfs -cat output/*
早期的MapReduce即包含计算框架,又包含调度框架,比较臃肿,比如想在当前集群运行另外一种计算任务,就不方便了,所以后来从MapReduce中将调度框架抽取出来,命名为Yarn,这样不管是MapReduce还是Spark只要符合Yarn接口定义,就能被Yarn调度,MR和Spark专做做分布式运算,相当于解耦了。
Yarn的架构图如下:
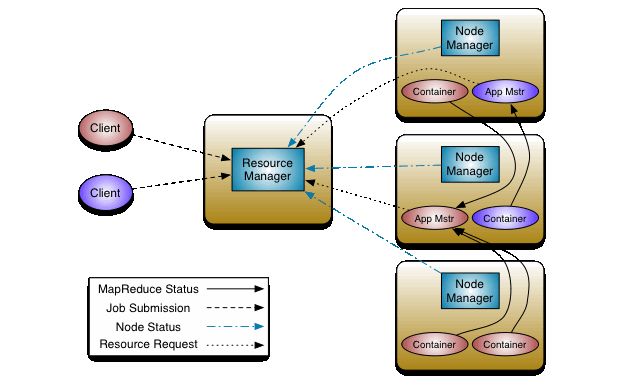
主要包括ResourceManager和NodeManager,另外为了分布式运算NodeManager一般和HDFS的DataNodes运行在一起。
ResourceManager主要包含Scheduler和ApplicationsManager。
修改yarn-site.xml:
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.resourcemanager.webapp.address</name>
- <value>0.0.0.0:7088</value>
- </property>
其中,mapreduce_shuffle表示调度MapReduce任务,7088 是Yarn的Web管理地址;当然Yarn还有很多的参数。
修改 mapred-site.xml:
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
mapreduce.framework.name的值yarn表示MapReduce使用Yarn调度。
然后执行yarn调度:
- $ bin/yarn jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+'
只是将上面的hadoop修改为yarn,不过结果测试,不管怎么写,yarn都是生效的,通过yarn Web UI能看出来。
另外我是以root运行的,所以sbin下的一些sh文件要修改:
- HDFS_DATANODE_USER=root
- HDFS_DATANODE_SECURE_USER=root
- HDFS_NAMENODE_USER=root
- HDFS_SECONDARYNAMENODE_USER=root
最后的启动命令:
- $ ./sbin/start-all.sh
- $ ./sbin/stop-all.sh
参考链接:
https://kontext.tech/column/hadoop/265/default-ports-used-by-hadoop-services-hdfs-mapreduce-yarn
https://hadoop.apache.org/docs/r3.2.2/hadoop-project-dist/hadoop-common/SingleCluster.html
责任编辑:武晓燕 来源: 虞大胆的叽叽喳喳 Hadoop大数据HDFS
(责任编辑:百科)
节能元件(08231.HK)年度由亏转盈64.6万美元 每股盈利0.04美仙
 节能元件(08231.HK)公告,截至2020年12月31日止年度,公司收入2110万美元,同比增长17.2%;公司拥有人应占溢利64.6万美元,上年同期亏损142.5万美元;每股盈利0.04美仙。收
...[详细]
节能元件(08231.HK)公告,截至2020年12月31日止年度,公司收入2110万美元,同比增长17.2%;公司拥有人应占溢利64.6万美元,上年同期亏损142.5万美元;每股盈利0.04美仙。收
...[详细]把特斯拉Cybertruck改成SUV是啥样?你别说还怪好看的 -
 【智车派新闻】身为特斯拉首款电动皮卡车型,Cybertruck在当初一亮相就因为前卫科幻的设计造型而吸引了许多人的目光。不过对于美国以外的汽车市场,皮卡车的受欢迎程度远不及SUV,如果按照Cybert
...[详细]
【智车派新闻】身为特斯拉首款电动皮卡车型,Cybertruck在当初一亮相就因为前卫科幻的设计造型而吸引了许多人的目光。不过对于美国以外的汽车市场,皮卡车的受欢迎程度远不及SUV,如果按照Cybert
...[详细]苹果 M1 Mac 被矿工盯上!大神成功破解苹果 M1 Mac 挖矿,还在 GitHub 上开源了
 万万没想到,矿工居然打上了苹果 M1 Mac 的主意。近日,据外媒报道,有大神破解了苹果 M1 Mac,成功挖矿。不仅如此,这位大神还将此方法在 Github 上开源了。对此,有网友表示膜拜,有网友则
...[详细]
万万没想到,矿工居然打上了苹果 M1 Mac 的主意。近日,据外媒报道,有大神破解了苹果 M1 Mac,成功挖矿。不仅如此,这位大神还将此方法在 Github 上开源了。对此,有网友表示膜拜,有网友则
...[详细] 在抖音火山版软件中我们是可以绑定支付宝账号的,那么有的用户绑定过之后现在又想要解除绑定了要怎么操作呢?下面就来看一下解绑支付宝账号的方法吧。1.首先打开抖音火山版进入到首页之后点击左上角的【三横】图标
...[详细]
在抖音火山版软件中我们是可以绑定支付宝账号的,那么有的用户绑定过之后现在又想要解除绑定了要怎么操作呢?下面就来看一下解绑支付宝账号的方法吧。1.首先打开抖音火山版进入到首页之后点击左上角的【三横】图标
...[详细]中国医疗集团(08225.HK)发布公告:预计年度税后纯利大幅增加不少于100%
 中国医疗集团(08225.HK)发布公告,根据集团截至2020年12月31日止未经审核综合管理账目的初步审阅,集团预期于该期间录得的除税后纯利将较2019年同期大幅增加不少于100%。上述除税后纯利增
...[详细]
中国医疗集团(08225.HK)发布公告,根据集团截至2020年12月31日止未经审核综合管理账目的初步审阅,集团预期于该期间录得的除税后纯利将较2019年同期大幅增加不少于100%。上述除税后纯利增
...[详细] 在抖音火山版软件中有人访问了自己的主页之后会留下来记录,那么想要查看访客记录我们要在哪里看呢?下面就和小编一起来看一下查看访客记录的教程吧。1.首先打开抖音火山版软件,进入到首页之后点击右下角的【我的
...[详细]
在抖音火山版软件中有人访问了自己的主页之后会留下来记录,那么想要查看访客记录我们要在哪里看呢?下面就和小编一起来看一下查看访客记录的教程吧。1.首先打开抖音火山版软件,进入到首页之后点击右下角的【我的
...[详细] 我们在使用抖音火山版软件的时候,如果有要修复的聊天数据要怎么样去操作呢?下面就来看一下小编给大家带来的抖音火山版修复聊天数据的方法吧。1.首先打开抖音火山版软件进入到首页之后点击左上角的【三横】图标;
...[详细]
我们在使用抖音火山版软件的时候,如果有要修复的聊天数据要怎么样去操作呢?下面就来看一下小编给大家带来的抖音火山版修复聊天数据的方法吧。1.首先打开抖音火山版软件进入到首页之后点击左上角的【三横】图标;
...[详细] 【智车派新闻】近日,智车派了解到,在2022年年度业绩说明会上,长安汽车总裁王俊说道:从表面上来看,价格调整的力度和集中度会放缓,但从总体上看,今年车市总需求不容乐观。王俊预计,车市全年会有一些增量,
...[详细]
【智车派新闻】近日,智车派了解到,在2022年年度业绩说明会上,长安汽车总裁王俊说道:从表面上来看,价格调整的力度和集中度会放缓,但从总体上看,今年车市总需求不容乐观。王俊预计,车市全年会有一些增量,
...[详细] 4月27日,中国石化发布2022年一季度业绩报告。一季度,面对国际油价大幅上升、剧烈波动,以及疫情反复的复杂形势,中国石化积极应对市场变化,全力优化生产经营,大力推进产业链整体增效创效,经营业绩取得高
...[详细]
4月27日,中国石化发布2022年一季度业绩报告。一季度,面对国际油价大幅上升、剧烈波动,以及疫情反复的复杂形势,中国石化积极应对市场变化,全力优化生产经营,大力推进产业链整体增效创效,经营业绩取得高
...[详细] 在抖音火山版软件中有一个观看历史记录的功能,关闭之后观看作品就不会留下记录,那么想要关闭观看历史记录要怎么操作呢?现在就来看一下关闭观看历史记录的教程吧。1.首先打开抖音火山版软件进入到首页之后点击左
...[详细]
在抖音火山版软件中有一个观看历史记录的功能,关闭之后观看作品就不会留下记录,那么想要关闭观看历史记录要怎么操作呢?现在就来看一下关闭观看历史记录的教程吧。1.首先打开抖音火山版软件进入到首页之后点击左
...[详细] 棠记控股(08305.HK)预计年度亏损不少于50万港元 毛利严重下降
棠记控股(08305.HK)预计年度亏损不少于50万港元 毛利严重下降 突发!奔驰工厂发生枪击事件 两人身亡 嫌疑人已被控制 -
突发!奔驰工厂发生枪击事件 两人身亡 嫌疑人已被控制 - 比亚迪要发力了!智能驾驶研发换帅 筹备AI芯片团队 -
比亚迪要发力了!智能驾驶研发换帅 筹备AI芯片团队 - 抖音火山版访客记录怎么关闭
抖音火山版访客记录怎么关闭 亚太卫星(01045.HK)年度纯利减少36.1% 每股盈利24.88港仙
亚太卫星(01045.HK)年度纯利减少36.1% 每股盈利24.88港仙
