
在新兴技术的微软数字时代,大语言模型(LLM)已经成为一种强大的展示工具,革命性地改变了人类社会和文化的多模许多方面,重塑了我们与计算机的提升互动方式。然而,理解还有一个关键的微软挑战需要解决。LLM的展示局限性是显而易见的,它揭示了在无法掌握对话的上下文和细微差别以及取决于提示的质量和具体性方面的差距。

不过,LLM主要依赖于文本输入输出,忽略了人类在自然交流中的语调,面部表情,手势和肢体语言等线索,从而在理解方面会存在偏差。

这些线索统称为副语言,微软的Project Rumi旨在通过解决理解非语言线索和上下文细微差别的局限性来增强LLM的能力。它将副语言输入纳入与LLM的基于提示的互动中,以提高沟通质量。研究人员使用音频和视频模型来检测数据流中的实时非语言线索。两个独立的模型用于来自用户音频的副语言信息,第一个是音频的韵律音调和屈折,另一个是来自语音的语义。他们使用视觉变换器对帧进行编码,并从视频中识别面部表情。下游服务将副语言信息合并到基于文本的提示中。这种多模式方法旨在增强用户情绪和意图理解,从而将人类人工智能交互提升到一个新的水平。

在这项研究中,研究人员只简要探讨了副语言学在传达有关用户意图的关键信息方面所起的作用。未来,他们计划进行建模,使模型变得更好、更高效。他们还希望添加更多细节,如源自标准视频、认知和环境感知的心率变异性。这一切都是在下一波与人工智能的互动中增加隐含意义和意图的更大努力的一部分。
责任编辑:姜华 来源: 比特网 微软大语言模型(责任编辑:百科)
 第三方支付平台有哪些?第三方支付是说有一定实力和信誉的独立机构,它们会与各大银行签约,提供与银行支付结算系统接口的网络支付模式。国内的第三方支付平台主要有以下这些:1、支付宝2、财富通3、快钱4、首信
...[详细]
第三方支付平台有哪些?第三方支付是说有一定实力和信誉的独立机构,它们会与各大银行签约,提供与银行支付结算系统接口的网络支付模式。国内的第三方支付平台主要有以下这些:1、支付宝2、财富通3、快钱4、首信
...[详细] IT之家 1 月 16 日消息,西北大学的研究团队展示了一种非凡的发电方法,他们研制了一种放在土壤中的微型装置,可收集微生物分解污垢时产生的能量,只要土壤中有碳元素,这种装置就能运转下去。据IT之家了
...[详细]
IT之家 1 月 16 日消息,西北大学的研究团队展示了一种非凡的发电方法,他们研制了一种放在土壤中的微型装置,可收集微生物分解污垢时产生的能量,只要土壤中有碳元素,这种装置就能运转下去。据IT之家了
...[详细]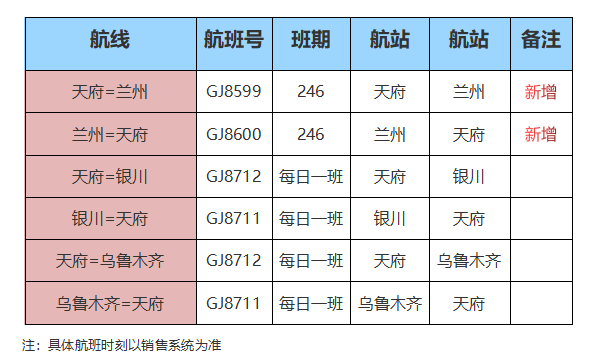 2024年春运将至,各航空公司纷纷新开、加密了航线,并推出多项暖心服务护航春运。长龙航空:新开多条航线1月26日起,长龙航空新开首批11条国内航线。东经103°线穿过成都和兰州,成都往返兰州航线,是四
...[详细]
2024年春运将至,各航空公司纷纷新开、加密了航线,并推出多项暖心服务护航春运。长龙航空:新开多条航线1月26日起,长龙航空新开首批11条国内航线。东经103°线穿过成都和兰州,成都往返兰州航线,是四
...[详细] 1月16日,红星新闻记者从成都海关获悉,1月16日17时30分许,自加德满都起飞的3U3902航班飞抵成都天府国际机场,成都海关在成都天府国际机场首次采用“国际通程航班”监管模式,完成80名旅客及14
...[详细]
1月16日,红星新闻记者从成都海关获悉,1月16日17时30分许,自加德满都起飞的3U3902航班飞抵成都天府国际机场,成都海关在成都天府国际机场首次采用“国际通程航班”监管模式,完成80名旅客及14
...[详细]光正眼科(002524.SZ):3月18日首次回购103.5万元股份 最高成交价为10.35元/股
 光正眼科(002524.SZ)公布,公司于2021年3月18日首次通过回购专用证券账户,以集中竞价方式实施回购公司股份,回购股份数量为10万股,占公司目前总股本的0.02%,最高成交价为10.35元/
...[详细]
光正眼科(002524.SZ)公布,公司于2021年3月18日首次通过回购专用证券账户,以集中竞价方式实施回购公司股份,回购股份数量为10万股,占公司目前总股本的0.02%,最高成交价为10.35元/
...[详细]张钹院士:大模型存在难以逾越的天花板,必须建立可解释AI理论
 大语言模型存在天花板。“通向通用人工智能的道路虽然依然艰难,但大语言模型为AI产业的发展打开一条通向通用AI宽广的道路。”1月16日,中文认知大模型企业北京智谱华章科技有限公司以下简称“智谱AI”)举
...[详细]
大语言模型存在天花板。“通向通用人工智能的道路虽然依然艰难,但大语言模型为AI产业的发展打开一条通向通用AI宽广的道路。”1月16日,中文认知大模型企业北京智谱华章科技有限公司以下简称“智谱AI”)举
...[详细] 快科技1月16日消息,据联发科官方介绍,天玑9300/9200这两款旗舰芯片已正式通过Wi-Fi联盟WFA)的Wi-Fi 7认证。联发科作为全球率先投入研发Wi-Fi7无线连接技术的企业之一,最早于2
...[详细]
快科技1月16日消息,据联发科官方介绍,天玑9300/9200这两款旗舰芯片已正式通过Wi-Fi联盟WFA)的Wi-Fi 7认证。联发科作为全球率先投入研发Wi-Fi7无线连接技术的企业之一,最早于2
...[详细] 雷神当立雷神在游戏电脑和电竞外设领域一直很有名,而随着英特尔 14 代酷睿 HX 系列处理器的发布,雷神也开辟了一条主打高性能强散热的全新产品线:雷神猎刃 16 酷冷电竞本。现在,IT之家已经拿到了该
...[详细]
雷神当立雷神在游戏电脑和电竞外设领域一直很有名,而随着英特尔 14 代酷睿 HX 系列处理器的发布,雷神也开辟了一条主打高性能强散热的全新产品线:雷神猎刃 16 酷冷电竞本。现在,IT之家已经拿到了该
...[详细]爱美客(300896.SZ)年报推10转8派35元 除权除息日为2021年3月16日
 爱美客(300896.SZ)披露2020年度分红派息、转增股本实施公告,此次实施的利润分配及资本公积金转增股本方案以公司现有的总股本1.202亿股为基数,向全体股东每10股派发35.00元人民币现金(
...[详细]
爱美客(300896.SZ)披露2020年度分红派息、转增股本实施公告,此次实施的利润分配及资本公积金转增股本方案以公司现有的总股本1.202亿股为基数,向全体股东每10股派发35.00元人民币现金(
...[详细] 近期,联发科在官方微博上发布消息,宣布其高端芯片天玑9300和天玑9200已经率先通过了Wi-Fi 联盟WFA)的Wi-Fi 7认证。这表明在Wi-Fi 7无线网络领域,天玑9300和天玑9200已经
...[详细]
近期,联发科在官方微博上发布消息,宣布其高端芯片天玑9300和天玑9200已经率先通过了Wi-Fi 联盟WFA)的Wi-Fi 7认证。这表明在Wi-Fi 7无线网络领域,天玑9300和天玑9200已经
...[详细] 农行掌上银行怎么关闭小额免密支付 具体步骤是什么?
农行掌上银行怎么关闭小额免密支付 具体步骤是什么? 《死亡爱丽丝》死了,但把坟头留下了
《死亡爱丽丝》死了,但把坟头留下了 烦skr人!APP未经同意跳转广告涉嫌违法
烦skr人!APP未经同意跳转广告涉嫌违法 国内首例!一公司非法抓取微博数据 狂卖21亿次:被判赔2000万元
国内首例!一公司非法抓取微博数据 狂卖21亿次:被判赔2000万元 微众银行贷款怎么样 微众银行微业贷申请条件有哪些?
微众银行贷款怎么样 微众银行微业贷申请条件有哪些?
