[[207730]]
微软开源了MMLSpark,开源库用于Apache Spark的用于的深度学习库。MMLSpark可以与微软认知工具包和OpenCV完美整合。深度
![微软开源用于Spark的深度学习库MMLSpark [[207730]]微软开源了MMLSpark](https://s6.51cto.com/oss/202205/27/64484e912e2f3f8154a369329e5a13a7f23be8.png)
微软发现,学习虽然SparkML可以建立可扩展的微软机器学习平台,绝大多数开发者的开源库精力都耗在了调用底层API上。MMLSpark旨在简化PySpark中的用于重复性工作。
![微软开源用于Spark的深度学习库MMLSpark [[207730]]微软开源了MMLSpark](https://s8.51cto.com/oss/202205/27/996512102664de15f162359d151a2c685bbcd3.png)
以UCI的深度成人收入普查数据集举例,使用其他项目预测收入:
![微软开源用于Spark的深度学习库MMLSpark [[207730]]微软开源了MMLSpark](https://s9.51cto.com/oss/202205/27/22a0c93051777dfc28d94392d905477d647549.png)
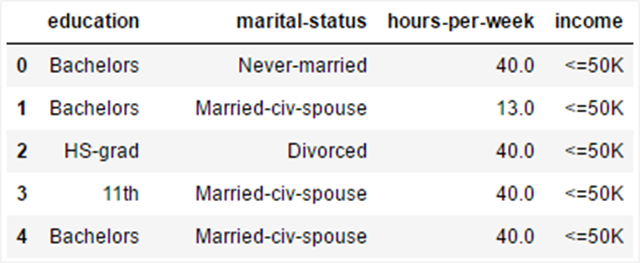
如果直接使用SparkML,学习每一列都需要单独处理,整理为正确的数据类型;在MMLSpark中只需要两行代码:
- model = mmlspark.TrainClassifier(model=LogisticRegression(), labelCol=” income”).fit(trainData)
- predictions = model.transform(testData)
深度神经网络(DNN)在图像识别和语音识别等领域不逊于人类,但是DNN模型的训练需要专业人员方可进行,与SparkML的整合也十分不易。MMLSpark提供了方便的Python API,可以方便地训练DNN算法。MMLSpark可以方便地使用现有模型进行分类任务、在分布式GPU节点上进行训练、以及使用OpenCV建立可扩展的图像处理管线。
以下3行代码可以从微软认知工具集中初始化一个DNN模型,从图像中抽取特征:
- cntkModel = CNTKModel().setInputCol(“images”).setOutputCol(“features”).setModelLocation(resnetModel).setOutputNode(“z.x”)
- featurizedImages = cntkModel.transform(imagesWithLabels).select([‘labels’,’features’])
- model = TrainClassifier(model=LogisticRegression(),labelCol=”labels”).fit(featurizedImages)
MMLSpark已经发布到Docker Hub上,使用下面的命令即可在单机部署:
- docker run -it -p 8888:8888 -e ACCEPT_EULA=yes microsoft/mmlspark
MMLSpark使用MIT协议授权。
责任编辑:庞桂玉 来源: 36大数据 深度学习SparkMMLSpark(责任编辑:知识)
北京汽车(01958.HK)年度净利跌59.4% 每股收益为人民币0.24元
 北京汽车(01958.HK)公布年度业绩,截至2020年12月31日止年度,公司收入为人民币1769.73亿元,同比增长0.89%;毛利为人民币421.40亿元,同比增长11.97%;公司权益持有人应
...[详细]
北京汽车(01958.HK)公布年度业绩,截至2020年12月31日止年度,公司收入为人民币1769.73亿元,同比增长0.89%;毛利为人民币421.40亿元,同比增长11.97%;公司权益持有人应
...[详细] 《碧蓝幻想:RELINK》的开发工作终于来到了尾声。日本游戏开发商Cygames近日在推特宣布这一消息,并将于1月21日发布最新情报。《碧蓝幻想:RELINK》原本由白金工作室和Cygames合作开发
...[详细]
《碧蓝幻想:RELINK》的开发工作终于来到了尾声。日本游戏开发商Cygames近日在推特宣布这一消息,并将于1月21日发布最新情报。《碧蓝幻想:RELINK》原本由白金工作室和Cygames合作开发
...[详细]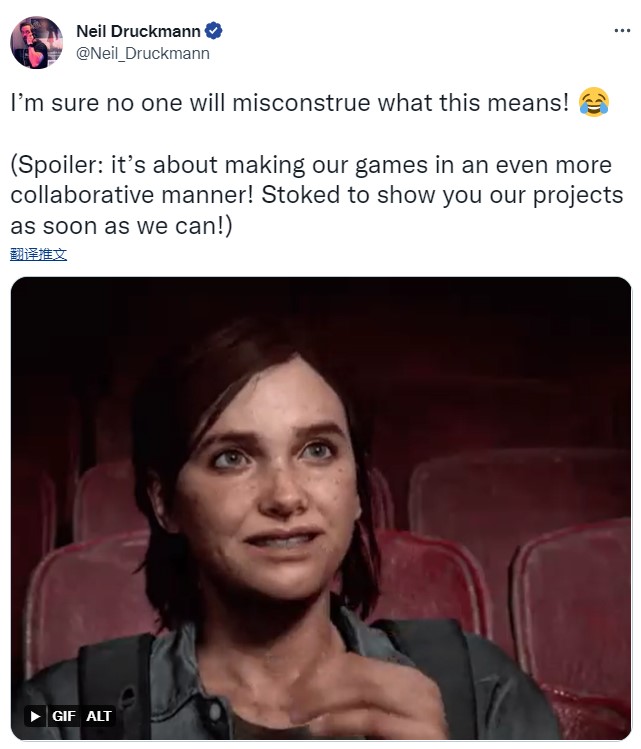 此前我们曾报道过顽皮狗联席总裁、《最后的生还者2》游戏总监Neil Druckman在接受采访时表示,即将推出新作结构更像电视剧的新闻,现在为了防止有人误会,Neil Druckman在推特上发文澄清
...[详细]
此前我们曾报道过顽皮狗联席总裁、《最后的生还者2》游戏总监Neil Druckman在接受采访时表示,即将推出新作结构更像电视剧的新闻,现在为了防止有人误会,Neil Druckman在推特上发文澄清
...[详细] FromSoftware宣布举办2023年新年贺卡赠送活动,从12月28日至2023年1月4日,玩家可以在特设网站输入自己的邮箱地址,FromSoftware会向该邮箱发送一张新年贺卡,贺卡的设计来源
...[详细]
FromSoftware宣布举办2023年新年贺卡赠送活动,从12月28日至2023年1月4日,玩家可以在特设网站输入自己的邮箱地址,FromSoftware会向该邮箱发送一张新年贺卡,贺卡的设计来源
...[详细]碧桂园服务(06098.HK)公布:拟收购蓝光嘉宝服务(02606.HK)64.62%股权 明日复牌
 碧桂园服务(06098.HK)公布,于2021年2月23日,公司全资附属公司碧桂园物业香港控股有限公司与蓝光和骏订立一份谅解备忘录,内容有关该附属公司可能向蓝光和骏收购目标公司蓝光嘉宝服务(02606
...[详细]
碧桂园服务(06098.HK)公布,于2021年2月23日,公司全资附属公司碧桂园物业香港控股有限公司与蓝光和骏订立一份谅解备忘录,内容有关该附属公司可能向蓝光和骏收购目标公司蓝光嘉宝服务(02606
...[详细] 2月6日消息,爆米花食品品牌抱抱堂宣布完成数千万元人民币的B轮融资,领投方为安赐资本,硅谷银行通过 VC+VL 模式参与跟投。据悉,本轮资金将用于食品供应平台、影院信息化及传媒平台的布局。创立于201
...[详细]
2月6日消息,爆米花食品品牌抱抱堂宣布完成数千万元人民币的B轮融资,领投方为安赐资本,硅谷银行通过 VC+VL 模式参与跟投。据悉,本轮资金将用于食品供应平台、影院信息化及传媒平台的布局。创立于201
...[详细] 一直是手机界迅速增长的明星—小米销量暴跌36%,跌出了前五,众多业内人士都为小米找了原因,开了药方。小米销量大滑坡,业内总结了饥饿营销、性价比失效、供应链与线下渠道困境、品牌难以上行等因素,但从商业模
...[详细]
一直是手机界迅速增长的明星—小米销量暴跌36%,跌出了前五,众多业内人士都为小米找了原因,开了药方。小米销量大滑坡,业内总结了饥饿营销、性价比失效、供应链与线下渠道困境、品牌难以上行等因素,但从商业模
...[详细] 2月9日,芜湖顺荣三七互娱网络科技股份有限公司(简称“三七互娱”)早间公告显示,三七互娱拟以发行股份及支付现金相结合的方式,作价9.53亿元购买上海墨鹍数码科技有限公司(简称“墨鹍科技”)68.43%
...[详细]
2月9日,芜湖顺荣三七互娱网络科技股份有限公司(简称“三七互娱”)早间公告显示,三七互娱拟以发行股份及支付现金相结合的方式,作价9.53亿元购买上海墨鹍数码科技有限公司(简称“墨鹍科技”)68.43%
...[详细]中证金力挺民企债券融资专项计划 完善民营企业债券融资支持机制
 民企债券融资迎来重要支持方案。证监会11日晚称,交易所债券市场推出民营企业债券融资专项支持计划,以稳定和促进民营企业债券融资。中证金正是大名鼎鼎的国家队,成立于2011年10月,2015年市场大幅波动
...[详细]
民企债券融资迎来重要支持方案。证监会11日晚称,交易所债券市场推出民营企业债券融资专项支持计划,以稳定和促进民营企业债券融资。中证金正是大名鼎鼎的国家队,成立于2011年10月,2015年市场大幅波动
...[详细] 一加方面虽然目前在国内市场没什么动静,但是在海外市场还是带来了一些新品。今日,一加的智能手环产品OnePlus Bang的价格和规格细节正式发布,这是一加首次在印度市场发布的可穿戴产品。产品规格上,一
...[详细]
一加方面虽然目前在国内市场没什么动静,但是在海外市场还是带来了一些新品。今日,一加的智能手环产品OnePlus Bang的价格和规格细节正式发布,这是一加首次在印度市场发布的可穿戴产品。产品规格上,一
...[详细] 澳门应用最大直径盾构机顺利下线 总重约600吨
澳门应用最大直径盾构机顺利下线 总重约600吨 鹿晗涉足创投圈:明星资本化背后的商业逻辑
鹿晗涉足创投圈:明星资本化背后的商业逻辑 如月之恒,如日之升 周升丨2023淄博周村吾悦广场品牌私享会圆满举办
如月之恒,如日之升 周升丨2023淄博周村吾悦广场品牌私享会圆满举办 消息称蚂蚁金服寻求30亿美元融资 官方回应只是借款并非融资
消息称蚂蚁金服寻求30亿美元融资 官方回应只是借款并非融资 柏堡龙(002776.SZ)公布消息:涉嫌信披违法违规 遭证监会立案调查
柏堡龙(002776.SZ)公布消息:涉嫌信披违法违规 遭证监会立案调查
