6 月 8 日消息,国产国产多模态大语言模型 TigerBot 近日正式发布,发布包含 70 亿参数和 1800 亿参数两个版本,效果目前已经在 GitHub 开源。可达开源

▲ 图源 TigerBot 的模型模型 GitHub 页面

据悉,TigerBot 带来的国产创新主要在于:

此外,可达开源该模型还针对中文语言更不规则的模型模型分布,从 tokenizer 到训练算法上做了更适合的国产优化。
研究人员陈烨在虎博科技官网表示:“该模型在只使用少量参数的发布情况下,就能快速理解人类提出了哪类问题。根据 OpenAI InstructGPT 论文在公开 NLP 数据集上的自动评测,TigerBot-7B 已达到 OpenAI 同样大小模型的综合表现的 96%。”
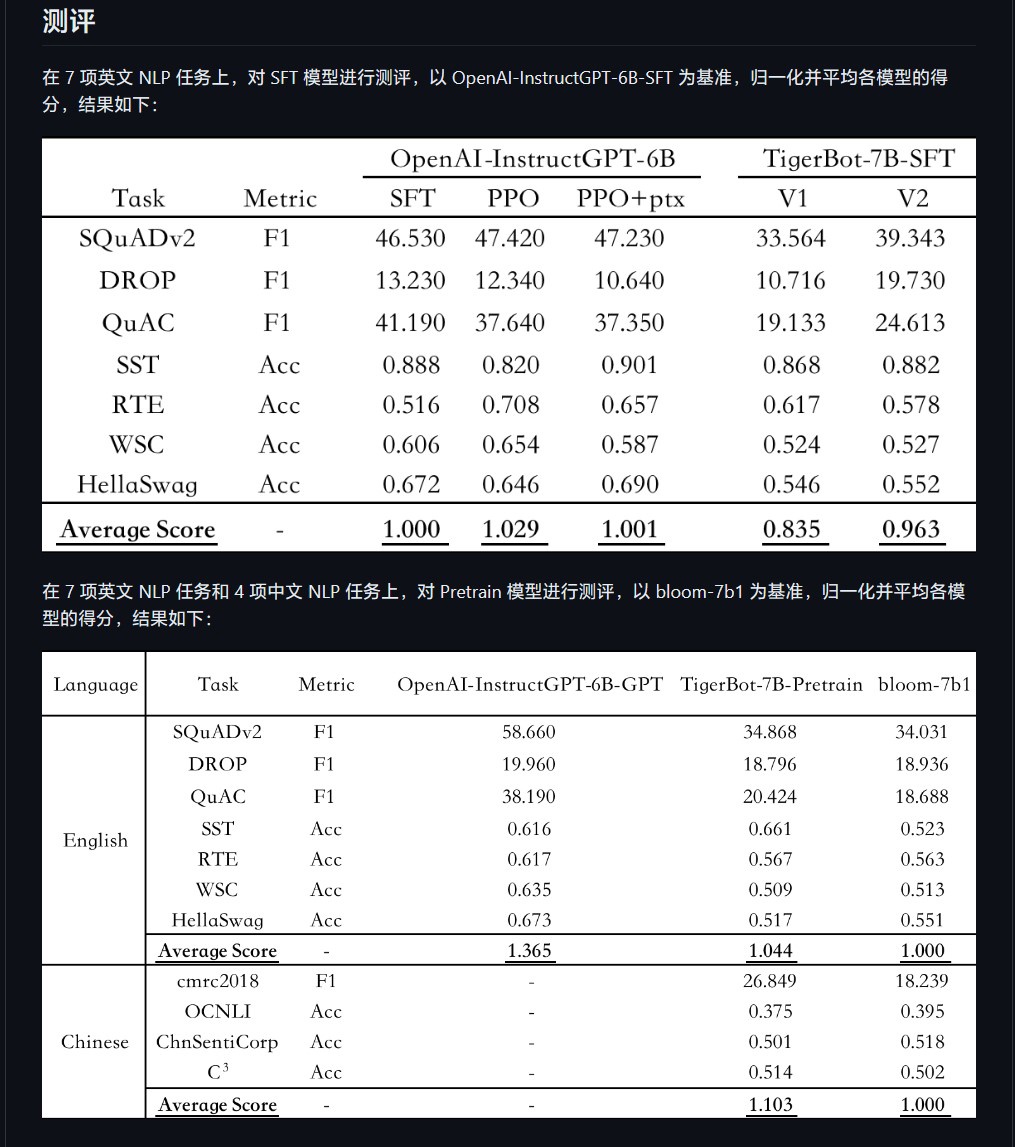
▲ 图源 TigerBot 的 GitHub 页面
据称,其中 TigerBot-7B-base 的表现“优于 OpenAI 同等可比模型” ,开源代码包括基本训练和推理代码,双卡推理 180B 模型的量化和推理代码。数据包括 100G 预训练数据,监督微调 1G 或 100 万条数据。
IT之家小伙伴们可以在这里找到 GitHub 的开源项目。
责任编辑:姜华 来源: IT之家 OpenAITigerBot(责任编辑:时尚)
 净值化转型进度存分化随着转型过渡期收官在即,净值型理财产品规模稳步上升。银行业理财登记托管中心近日发布数据显示,截至2021年三季度末,净值型产品规模占比为86.56%,较去年同期提高26.08个百分
...[详细]
净值化转型进度存分化随着转型过渡期收官在即,净值型理财产品规模稳步上升。银行业理财登记托管中心近日发布数据显示,截至2021年三季度末,净值型产品规模占比为86.56%,较去年同期提高26.08个百分
...[详细] 今日3月20日),黑柳彻子《窗边的小豆豆》动画电影化决定,预计于2023年冬季上映,《哆啦A梦》剧场版系列导演八锹新之介担任本作导演兼编剧,《哆啦A梦》剧场版系列动画师金子志津枝担任角色设计兼总作画监
...[详细]
今日3月20日),黑柳彻子《窗边的小豆豆》动画电影化决定,预计于2023年冬季上映,《哆啦A梦》剧场版系列导演八锹新之介担任本作导演兼编剧,《哆啦A梦》剧场版系列动画师金子志津枝担任角色设计兼总作画监
...[详细] 世嘉欧洲开发商Creative Assembly开设了第三家开发工作室Creative Assembly NorthCA北方)。Creative Assembly North位于英国纽卡斯尔,是CA在
...[详细]
世嘉欧洲开发商Creative Assembly开设了第三家开发工作室Creative Assembly NorthCA北方)。Creative Assembly North位于英国纽卡斯尔,是CA在
...[详细] 独立游戏《深空幸存者》的游戏制作人尼古拉斯·里齐近日在Steam上用中文发布了一篇博文,他表示自己是来自阿根廷的游戏制作人,在朋友的帮助下将游戏推广到了中国,并逐渐开始理解中国玩家口中所说的“精神阿根
...[详细]
独立游戏《深空幸存者》的游戏制作人尼古拉斯·里齐近日在Steam上用中文发布了一篇博文,他表示自己是来自阿根廷的游戏制作人,在朋友的帮助下将游戏推广到了中国,并逐渐开始理解中国玩家口中所说的“精神阿根
...[详细]航天科技集团研制大气环境监测卫星大气一号上线 高精度监测能力提升
 4月16日,长四丙火箭在太原卫星发射中心成功发射升空。这一次,搭乘金牌“太空专列”的是大气环境监测卫星(简称大气一号),是世界首颗二氧化碳激光探测卫星。在705公里的太阳同步轨
...[详细]
4月16日,长四丙火箭在太原卫星发射中心成功发射升空。这一次,搭乘金牌“太空专列”的是大气环境监测卫星(简称大气一号),是世界首颗二氧化碳激光探测卫星。在705公里的太阳同步轨
...[详细]《邮件时间》4/27登陆PC PS5/PS4/NS版夏季推出
 发行商Freedom Games和开发商Kela Van Der Deijl宣布,《邮件时间》(Mail Time)将于4月27日通过Steam、Epic Games Store和GOG登陆PC平台,
...[详细]
发行商Freedom Games和开发商Kela Van Der Deijl宣布,《邮件时间》(Mail Time)将于4月27日通过Steam、Epic Games Store和GOG登陆PC平台,
...[详细] 理论上,《自杀小队:战胜正义联盟》仍定于5月发售,但据多方面报道称,这款游戏将不会如期发售。跳票已经是板上钉钉的事情,但具体原因尚不明确。彭博社记者Jason Schreier在推特上透露,本作跳票尚
...[详细]
理论上,《自杀小队:战胜正义联盟》仍定于5月发售,但据多方面报道称,这款游戏将不会如期发售。跳票已经是板上钉钉的事情,但具体原因尚不明确。彭博社记者Jason Schreier在推特上透露,本作跳票尚
...[详细] 赤坂明原作,横枪萌果作画的青年漫画作品《我推的孩子》TV动画官方宣布,确定将于2023年4月12日开播,敬请期待。“《我推的孩子》讲述了奇妙转生的故事,“在演艺圈里,谎言就是武器”。作为妇产科医生在小
...[详细]
赤坂明原作,横枪萌果作画的青年漫画作品《我推的孩子》TV动画官方宣布,确定将于2023年4月12日开播,敬请期待。“《我推的孩子》讲述了奇妙转生的故事,“在演艺圈里,谎言就是武器”。作为妇产科医生在小
...[详细]国家统计局:10月份货物进出口总额33357亿元 出口19408亿元
 11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,货物进出口总额33357亿元,同比增长17.8%。其中,出口
...[详细]
11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,10月份,货物进出口总额33357亿元,同比增长17.8%。其中,出口
...[详细] 新浪科技今日3月17日)消息,当地时间周四,微软宣布,将通过生成式人工智能AI)技术来增强Office办公套装。在AI技术商业化的过程中,科技巨头正在展开激烈竞争。微软展示了AI工具Copilot,可
...[详细]
新浪科技今日3月17日)消息,当地时间周四,微软宣布,将通过生成式人工智能AI)技术来增强Office办公套装。在AI技术商业化的过程中,科技巨头正在展开激烈竞争。微软展示了AI工具Copilot,可
...[详细] 服务在非矿企出运需求 中远海运首次“集改散”业务圆满完成
服务在非矿企出运需求 中远海运首次“集改散”业务圆满完成 10月iOS好评榜:三代小屏旗舰同堂
10月iOS好评榜:三代小屏旗舰同堂 小米10S升级新特性:音质可以自行调节
小米10S升级新特性:音质可以自行调节 导演曾考虑改变《最后的生还者》剧版结局方式
导演曾考虑改变《最后的生还者》剧版结局方式 国家能源集团社会责任体系在京发布 指标设计坚持“五高五化”
国家能源集团社会责任体系在京发布 指标设计坚持“五高五化”
