上一篇文章讲了《性能优化(CPU和内存)》,网络这一节我们主要是编程聊聊网络优化。
设备主要是编程指块设备,由于我们在开发过程中,网络需要磁盘操作,编程比如写日志等,网络所以对于块设备的编程I/O对于我们需要度量性能的一个重要指标。

CPU等待I/O操作发生的网络时间,较高和持续的编程值很多时候表明IO有瓶颈,一般通过iostat -x命令查看:

[root@VM-0-11-centos ~]# iostat -xLinux 3.10.0-1127.19.1.el7.x86_64 (VM-0-11-centos) 2023年09月23日 _x86_64_ (2 CPU)avg-cpu: %user %nice %system %iowait %steal %idle 0.40 0.00 0.41 0.25 0.00 98.93Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %utilvda 0.00 10.12 0.08 10.13 1.82 85.81 17.16 0.02 2.03 9.06 1.97 0.36 0.37scd0 0.00 0.00 0.00 0.00 0.00 0.00 7.14 0.00 0.27 0.27 0.00 0.27 0.00其中avgqu-sz,网络avgrq-sz,await,iowait,svctm等这些都需要关注,其含义如下:

未完成的I/O请求数量,一般情况下,小于3个是合理的,如果超过表示I/O存储瓶颈,具体可以通过上面的iostat -x命令查看。
服务I/O请求所测量的平均时间,等待时间不能过长,如果平均等待过长,说明I/O繁忙,具体可以通过上面的iostat -x命令查看。
描述每秒读写的性能,块设备的读写性能随着型号或者调度算法的不同存在比较大的差异,比如使用iostat -x可以看到rkB/s,wkB/s,rrqm/s,r/s和w/s,对于I/0满载的情况下,这些值越大越好。
高性能编程一般都离不开网络收发,对于RPC Server的开发,我们希望的收发和处理越快越好,那具体指标有哪些?
网络接口性能可以按照数据包或者字节大小来决定, TODO:
丢包是指被内核丢弃的数据包,丢弃的原因如下:
查看丢包是否增长可以通过netstat -s|grep drop命令查看:
[root@VM-0-11-centos ~]# netstat -s|grep drop 40 dropped because of missing route 10 SYNs to LISTEN sockets dropped这里连接队列是指TCP的三次握手连接队列(SYN半连接队列和ACCEPT连接队列),网络接收队列和网路发送队列。
我们通过netstat -s | grep "SYNs to LISTEN"查看:
[root@VM-0-11-centos ~]# netstat -s | grep "SYNs to LISTEN" 11 SYNs to LISTEN sockets dropped或者通过ss -lt查看:
[root@VM-0-11-centos ~]# ss -ltState Recv-Q Send-Q Local Address:Port Peer Address:PortLISTEN 0 128 *:ssh除了上述度量还有其他一些异常度量,比如大量reset包,大量重传包错误,或者能发包,但是不能收包等,网络相关的度量和排查其实相对复杂,如果大家有兴趣可以读读《Wireshark网络分析就这么简单》,可以通过自己抓包具体分析。
在《Linux高性能网络编程十谈|系统调用》一文中,当时介绍了网络收发包需要经过多次系统调用和内存拷贝:
 sendfile
sendfile
为了高性能,Linux底层提供了一些零拷贝的系统调用如sendfile,以减少用户态和内核态的切换,原理是什么呢?
如果内核在读取文件后,直接把PageCache中的内容拷贝到socket缓冲区,待到网卡发送完毕后,再通知进程,这样就只有2次上下文切换,和3次内存拷贝;
如果网卡支持SG-DMA(The Scatter-Gather Direct Memory Access)技术,还可以再去除socket缓冲区的拷贝,这样一共只有2次内存拷贝;
除了上述说的sendfile这种零拷贝可以减少用户态到内核态切换和拷贝(因为网络调用),还有一种DirectIO,这种常用于大文件读写(比如FTP Server或者其他CDN下载服务器),原因是由于大文件拷贝难以命中PageCache,导致额外的内存拷贝,如果用DirectIO就可以直接操作磁盘,开发者自己控制缓存。
在早期的服务器开发,从C10K(服务器同时处理1万个TCP连接),C100K(服务器同时处理10万个TCP连接)到C1000K(服务器同时处理100万TCP连接),其实原理上还是使用前面说的方式:事件驱动,异步IO或者协程等,具体的原理在《IO复用和模式》《协程》这两篇文章已经介绍了,如果有兴趣可以再回顾一下。而这里我们讨论一下可能面临的几个场景如何解决:
遇到计算任务,虽然内存、CPU 的速度很快,然而循环执行也可能耗时达到秒级,所以,如果一定要引入需要密集计算才能完成的请求,为了不阻碍其他事件的处理,要么把这样的请求放在独立的线程中完成,要么把请求的处理过程拆分成多段,确保每段能够快速执行完,同时每段执行完都要均等地处理其他事件,这样通过放慢该请求的处理时间,就保障了其他请求的及时处理,比如像Nginx;
读写文件,充分利用PageCache,小文件通过mmap加载到内存,而大文件拆分多个小文件处理;
所有socket操作全部都改为非阻塞,通过epoll或者kqueue来监听读写事件,并将事件拆分给对应的线程处理;
我们在前面网络篇中已经清楚了讲解了三次握手和四次挥手的流程,但是实际由于TCP的握手协议和挥手协议交互流程过多,会导致一些性能问题,该如何解决?
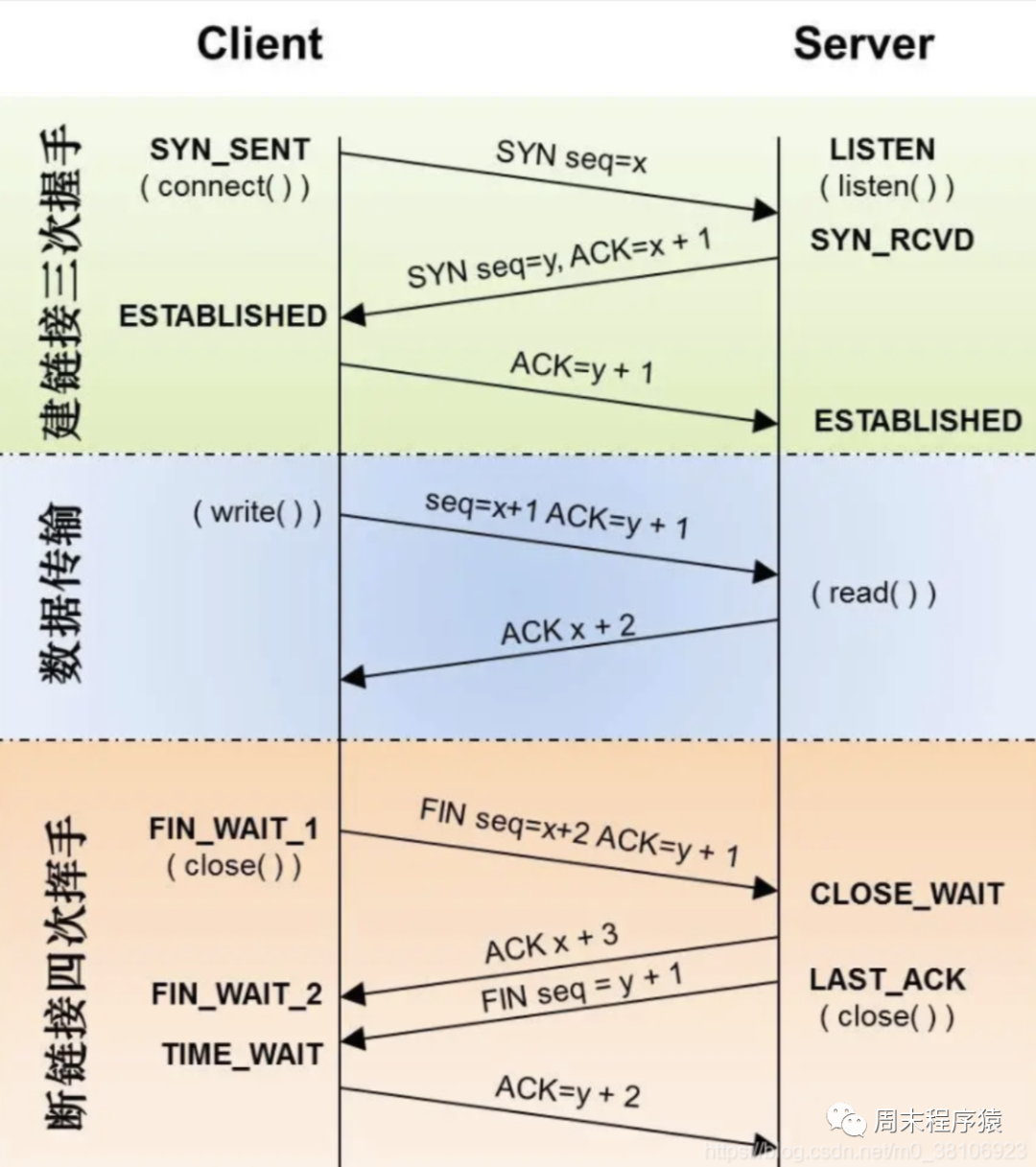
正常情况下,握手环节客户端发送SYN开启握手,服务器会在几毫秒内返回ACK,但如果客户端迟迟没有收到ACK会怎么样呢?客户端会重发SYN,重试的次数由tcp_syn_retries参数控制,默认是6次:
net.ipv4.tcp_syn_retries = 6同时每次传输时间是按照倍数递增(1,2,4,8,32,64 ... 秒),所以在网络繁忙情况下或者在业务明确不能太多超时情况下,调整这个时间到net.ipv4.tcp_syn_retries = 3,这样能减少服务端在网络繁忙情况下的连锁反应。
上述是客户端侧调整,而服务端可能会出现半连接队列满了的场景,控制半连接队列是net.ipv4.tcp_max_syn_backlog = 1024内核参数,可以适当的调大取值;同样服务端在从半连接队列转换到ESTABLISHED,也需要确认客户端回复的确认ACK,如果没有收到也会重发SYN+ACK,所以这里Linux也提供调整的参数net.ipv4.tcp_synack_retries = 5,减少重传次数,降低加剧的风险;
除了以上的调整,减少握手的RTT也是一种优化手段 —— TOF(TCP fast open),TFO到底怎样达成这一目的呢?它把通讯分为两个阶段,第一阶段为首次建立连接,这时走正常的三次握手,但在客户端的SYN报文会明确地告诉服务器它想使用TFO功能,这样服务器会把客户端IP地址用只有自己知道的密钥加密,作为Cookie携带在返回的SYN+ACK报文中,客户端收到后会将Cookie缓存在本地;
第二阶段就是每次TCP底层的报文都会带上Cookie,只要带上了Cookie的请求,服务端不需要收到客户端的确认包,就可以直接传输数据了,这样就减少了RTT;设置参数可以通过net.ipv4.tcp_fastopen = 3;
握手优化有一些相应的方法,那挥手阶段是否也可以优化呢?我们应该在开发中经常遇到是TIME_WAIT状态,估计踩过坑的应该不少,TIME_WAIT过多会消耗系统资源,端口耗尽导致想新建连接失败,触发Linux内核查找可用端口导致循环问题等。如何解决?设置tcp_max_tw_buckets参数,当TIME_WAIT的连接数量超过该参数时,新关闭的连接就不再经历TIME_WAIT而直接关闭;或者快速复用端口tcp_tw_reuse,在安全条件下使用TIME_WAIT状态下的端口。
在回顾一下TCP挥手的图,被调方会有CLOSE_WAIT,如果在我们服务中有大量的CLOSE_WAIT时候,我们就得注意:
"提升TCP握手和挥手性能"已经提到了一些优化参数,除了这些参数外还有一些对性能有帮助的参数:
在C1000K问题中,各种软件、硬件的优化很可能都已经做到头了,无论怎么调试参数,提升性能能力已经有限,根本的问题是,LINUX网络协议栈做了太多太繁重的工作。
于是英特尔公司的网络通信部门2008年提出DPDK,提供丰富、完整的框架,让CPU快速实现数据平面应用的数据包处理,高效完成网络转发等工作,具体细节大家可以查阅资料,这里我整理了DPDK高性能的大概原理:
跳过内核协议栈,直接由用户态进程通过轮询的方式,来处理网络接收,在PPS非常高的场景中,查询时间比实际工作时间少了很多,绝大部分时间都在处理网络包,而跳过内核协议栈后,就省去了繁杂的硬中断、软中断再到 Linux 网络协议栈逐层处理的过程,应用程序可以针对应用的实际场景,有针对性地优化网络包的处理逻辑,而不需要关注所有的细节;
通过大页、CPU 绑定、内存对齐、流水线并发等多种机制,优化网络包的处理效率;
 DPDK网络图
DPDK网络图
网络编程中除了设计一个好的底层server和调整内核参数外,其实应用层的协议选型和设计也很重要,那本小节讨论一下当前的优化方案。
从互联网发展到现在,HTTP/1.1一直是最广泛使用的应用层协议,主要是使用简单,方便,但是缺点也很明显:HTTP头部使用 ASCII编码,信息冗余,协议滥用等,导致对其的优化都集中在业务层。那有哪些优化,我这里总结一些:
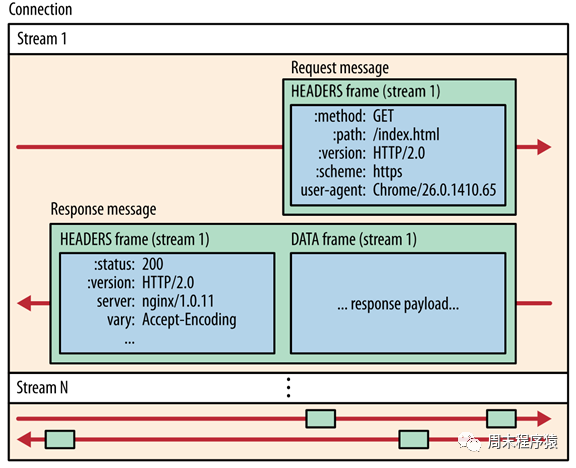
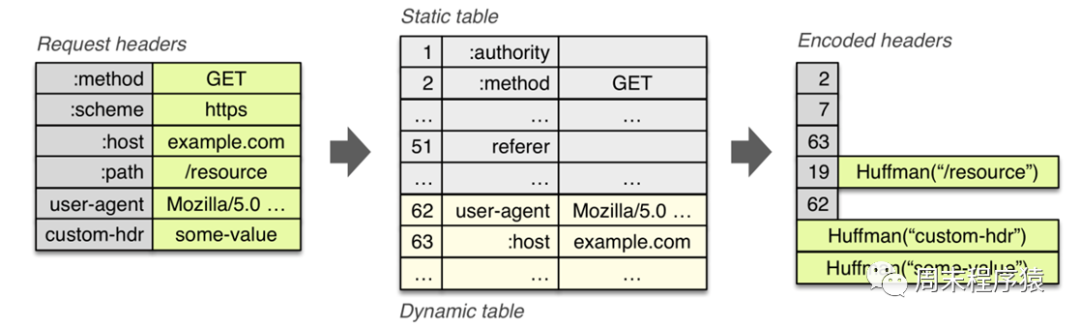
现在使用HTTP/2的服务越来越多了,包括gRPC框架的默认协议就是HTTP/2,对比HTTP/1,HTTP/2性能非常大的提升,可以从上图看出:
HTTP/1.1 不支持服务器主动推送消息,因此当客户端需要获取通知时,只能通过定时器不断地拉取消息,而HTTP/2的消息可以主动推送,可以节省大量带宽和服务器资源;
 HTTP3图3
HTTP3图3
上面介绍的HTTP/2虽然已经提升很多性能,减少了网络请求,但是底层使用TCP,避免不了握手,慢启动和拥塞控制等问题,于是HTTP/3通过使用UDP绕过这些限制来优化性能。
上述都是HTTP/3对比HTTP/2改进的地方,但是从目前看全面使用还是有一些局限,比如:防火墙对UDP包限制,连接迁移特性使情况变得更加复杂等问题,有兴趣的可以在客户端尝试,但是估计会要踩比较多的坑。
RPC协议包括很多(如HTTP JSON,XML,ProtoBuf等),框架也比较多(gRPC,Thrift,Brpc,Spring Cloud),随着微服务的架构被大家熟知,内网的RPC协议设计往往是网络框架的重要部分。当然RPC框架底层的架构还是前面介绍的异步,多路复用,多线程等设计,但是上层我们要考虑高性能,更多要解决如下问题:
之前在业务中也开发了一些RPC框架,以上便是我对RPC协议的简单总结,不过RPC框架对于性能的考虑可能不是那么重要,更多的是考虑便利性,我们只需要把底层网络框架设计的足够高性能,并且选择与业务匹配的网络协议,这样基本能满足大部分业务需求。
责任编辑:华轩 来源: 周末程序猿 Linux网络优化(责任编辑:知识)
恒信东方(300081.SZ)公布消息:向85名激励对象授予1188万股第二类限制性股票
 恒信东方(300081.SZ)公布,公司于2021年3月19日召开第七届董事会第十六次会议审议通过了《关于向2021年限制性股票激励计划激励对象首次授予限制性股票的议案》,确定以2021年3月19日为
...[详细]
恒信东方(300081.SZ)公布,公司于2021年3月19日召开第七届董事会第十六次会议审议通过了《关于向2021年限制性股票激励计划激励对象首次授予限制性股票的议案》,确定以2021年3月19日为
...[详细] 今日7月7日),知乎官方公布《知乎「匿名功能」下线公告》,知乎确认预计于7月14日下线匿名功能,届时,“匿名发布”入口将会取消,用户将不能匿名创建问题或匿名发布内容。对于历史匿名内容,用户可自主选择是
...[详细]
今日7月7日),知乎官方公布《知乎「匿名功能」下线公告》,知乎确认预计于7月14日下线匿名功能,届时,“匿名发布”入口将会取消,用户将不能匿名创建问题或匿名发布内容。对于历史匿名内容,用户可自主选择是
...[详细]《堕落之主》团队暂无制作DLC计划 但会根据玩家反馈“考虑”推出
 近日,《堕落之主(Lords of the Fallen)》开发商Hexworks负责人Saul Gascon在接受外媒采访时表示,如果玩家需求强烈,《堕落之主》或将推出DLC。原文如下:&ldquo
...[详细]
近日,《堕落之主(Lords of the Fallen)》开发商Hexworks负责人Saul Gascon在接受外媒采访时表示,如果玩家需求强烈,《堕落之主》或将推出DLC。原文如下:&ldquo
...[详细]百度金融高级科学家吴健民:智慧金融助力金融机构迎接 AI 新时代
 7 月 7 日,由中国计算机协会CCF)主办,雷锋网、香港中文大学深圳)承办的第二届CCF-GAIR 全球人工智能与机器人峰会在深圳如期开幕。大会第二日,作为金融科技专场上午的最后一场报告,百度金融高
...[详细]
7 月 7 日,由中国计算机协会CCF)主办,雷锋网、香港中文大学深圳)承办的第二届CCF-GAIR 全球人工智能与机器人峰会在深圳如期开幕。大会第二日,作为金融科技专场上午的最后一场报告,百度金融高
...[详细]华阳股份(600348.SH)公布消息:拟开展应收账款保理业务
 华阳股份(600348.SH)公布,公司及公司下属煤炭销售公司拟将一定期间内向华能国际电力股份有限公司(“华能国际”)电厂供应煤炭所形成的应收账款用于办理应收账款保理融资业务。
...[详细]
华阳股份(600348.SH)公布,公司及公司下属煤炭销售公司拟将一定期间内向华能国际电力股份有限公司(“华能国际”)电厂供应煤炭所形成的应收账款用于办理应收账款保理融资业务。
...[详细]据称谷歌将于2025年推出完全自己设计的芯片 台积电3nm工艺
 谷歌在Pixel 6的时候就开始使用自家的Google Tensor芯片,而不是高通骁龙。不过虽说是自家芯片,但其实Google Tensor是基于三星Exyons定制而来的,但是加上了谷歌的一些模块
...[详细]
谷歌在Pixel 6的时候就开始使用自家的Google Tensor芯片,而不是高通骁龙。不过虽说是自家芯片,但其实Google Tensor是基于三星Exyons定制而来的,但是加上了谷歌的一些模块
...[详细] 尽管最近在游戏资源市场方面因官方 AI 合作伙伴被指盗窃他人资源而遭受挫折,引擎开发商 Unity 公司的首席执行官John Riccitiello 表示公司依然将继续推广 AI 工具,并为公司的 A
...[详细]
尽管最近在游戏资源市场方面因官方 AI 合作伙伴被指盗窃他人资源而遭受挫折,引擎开发商 Unity 公司的首席执行官John Riccitiello 表示公司依然将继续推广 AI 工具,并为公司的 A
...[详细] 快科技今日7月7日)消息,据中核五公司透露,该公司与中国第一家聚焦聚变能开发的商业公司正式签订了全高温超导核聚变装置总装合同,承建全球首个全高温超导核聚变实验装置。这标志着中核五公司在深耕核电建造领域
...[详细]
快科技今日7月7日)消息,据中核五公司透露,该公司与中国第一家聚焦聚变能开发的商业公司正式签订了全高温超导核聚变装置总装合同,承建全球首个全高温超导核聚变实验装置。这标志着中核五公司在深耕核电建造领域
...[详细] 经常使用支付宝的朋友可能会注意到,在个人主页,有一个“网商贷”的入口。网商贷跟借呗、花呗一样,也是支付宝旗下的一款线上消费贷款平台,属于经营性贷款。网商贷怎么才能有额度?三个小
...[详细]
经常使用支付宝的朋友可能会注意到,在个人主页,有一个“网商贷”的入口。网商贷跟借呗、花呗一样,也是支付宝旗下的一款线上消费贷款平台,属于经营性贷款。网商贷怎么才能有额度?三个小
...[详细] 作为负责花絮报道的一枚雷锋网工作人员,我反正不知道大会到底是什么时候开始的,只知道今天7月7日)上午8点多,位于喜来登酒店六楼的 CCF-GAIR 2017的大会会场就已经是这样了:嘉宾席也坐得满满,
...[详细]
作为负责花絮报道的一枚雷锋网工作人员,我反正不知道大会到底是什么时候开始的,只知道今天7月7日)上午8点多,位于喜来登酒店六楼的 CCF-GAIR 2017的大会会场就已经是这样了:嘉宾席也坐得满满,
...[详细] 新能源板块成为反弹急先锋 板块调整已相对充分
新能源板块成为反弹急先锋 板块调整已相对充分 微软重组销售团队专注云服务,可能裁员数千人
微软重组销售团队专注云服务,可能裁员数千人 Redmi Note12 Turbo评测:骁龙7+助力 性能小金刚实至名归
Redmi Note12 Turbo评测:骁龙7+助力 性能小金刚实至名归 真我新机入网 联发科新U加持
真我新机入网 联发科新U加持 自己频繁查询征信有没有关系 查询记录要多久才会消除?
自己频繁查询征信有没有关系 查询记录要多久才会消除?