唯一ID可以标识数据的雪花唯一性,在分布式系统中生成唯一ID的分布方案有很多,常见的式ID生算法方式大概有以下三种:


一、分布数据库和UUID方案的式ID生算法不足之处

采用数据库自增序列:
UUID随机数:
二、关于雪花算法
有这么一种说法,自然界中并不存在两片完全一样的雪花的。每一片雪花都拥有自己漂亮独特的形状、独一无二。雪花算法也表示生成的ID如雪花般独一无二。

1. 雪花算法概述
雪花算法生成的ID是纯数字且具有时间顺序的。其原始版本是scala版,后面出现了许多其他语言的版本如Java、C++等。
2. 组成结构
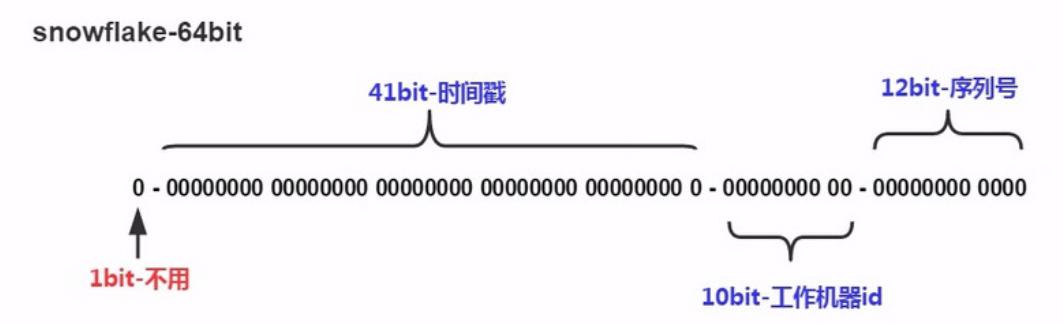
大致由:首位无效符、时间戳差值,机器(进程)编码,序列号四部分组成。
3. 特点(自增、有序、适合分布式场景)
snowflake算法可以根据项目情况以及自身需要进行一定的修改。

三、雪花算法的缺点
雪花算法在单机系统上ID是递增的,但是在分布式系统多节点的情况下,所有节点的时钟并不能保证不完全同步,所以有可能会出现不是全局递增的情况。
四、总结
分布式唯一ID的方案有很多,本文主要讨论了雪花算法,组成结构大致分为了无效位、时间位、机器位和序列号位。其特点是自增、有序、纯数字组成查询效率高且不依赖于数据库。适合在分布式的场景中应用,可根据需求调整具体实现细节。
责任编辑:赵宁宁 来源: 今日头条 雪花算法分布式ID
(责任编辑:知识)
三季度基金代销机构公募基金保有规模前100强名单 银行C位不变
 在财富管理日益兴盛的当下,基金代销已成为银行增加中间收入的重要组成部分。11月10日,中国证券投资基金业协会(以下简称“中基协”)披露最新的三季度基金代销机构公募基金保有规模前
...[详细]
在财富管理日益兴盛的当下,基金代销已成为银行增加中间收入的重要组成部分。11月10日,中国证券投资基金业协会(以下简称“中基协”)披露最新的三季度基金代销机构公募基金保有规模前
...[详细]OPPO Watch 3 Pro获得PChome2022卓越创新手表奖项
 PChome一年一度的年度卓越产品评选已经落下帷幕,2022年度共有数十款产品从300多款参选产品中脱颖而出,获得年度奖项。在本次评选活动中,OPPO Watch 3 Pro产品获得PChome202
...[详细]
PChome一年一度的年度卓越产品评选已经落下帷幕,2022年度共有数十款产品从300多款参选产品中脱颖而出,获得年度奖项。在本次评选活动中,OPPO Watch 3 Pro产品获得PChome202
...[详细] Vario-Apo-Sonnar长焦镜头将会配备在vivo X100 Pro和vivo X100 Pro+之中,能够让更多用户体验到长焦镜头带来的便利。vivo在此前曾经表示,将建立全新标准的“Var
...[详细]
Vario-Apo-Sonnar长焦镜头将会配备在vivo X100 Pro和vivo X100 Pro+之中,能够让更多用户体验到长焦镜头带来的便利。vivo在此前曾经表示,将建立全新标准的“Var
...[详细] Redmi K60至尊版和一加Ace 2 Pro到底谁更值得购买?买贵的还是买对的?本期视频,我们就来不恰饭实测一下两款手机的表现。Redmi K60至尊版和一加Ace 2 Pro到底谁更值得购买?
...[详细]
Redmi K60至尊版和一加Ace 2 Pro到底谁更值得购买?买贵的还是买对的?本期视频,我们就来不恰饭实测一下两款手机的表现。Redmi K60至尊版和一加Ace 2 Pro到底谁更值得购买?
...[详细] 原本作为样品给消费者使用和体验的化妆品试用装,竟成为时下不少商家开展单独销售的一门生意。HARMAY话梅、THE COLORIST调色师等新兴美妆集合店内,种类丰富、价格低廉的化妆品小样吸引年轻人排起
...[详细]
原本作为样品给消费者使用和体验的化妆品试用装,竟成为时下不少商家开展单独销售的一门生意。HARMAY话梅、THE COLORIST调色师等新兴美妆集合店内,种类丰富、价格低廉的化妆品小样吸引年轻人排起
...[详细] 让我们一起看看戴尔OptiPlex是如何做好商用台式机的。戴尔科技集团近日在北京召开了2023戴尔科技峰会,本次峰会戴尔科技围绕新型云计算、现代化数据架构及AI、边缘创新数字体验、混合办公革命、端点级
...[详细]
让我们一起看看戴尔OptiPlex是如何做好商用台式机的。戴尔科技集团近日在北京召开了2023戴尔科技峰会,本次峰会戴尔科技围绕新型云计算、现代化数据架构及AI、边缘创新数字体验、混合办公革命、端点级
...[详细]三星Galaxy Tab S9 FE系列确认采用Exynos1380处理器
 根据公布的数据来看,两款产品搭载的均为代号为Samsung s5e8835的Exynos 1380处理器,这枚处理器的CPU端采用了4 x A782400MHz)+4 x A552000MHz)架构,
...[详细]
根据公布的数据来看,两款产品搭载的均为代号为Samsung s5e8835的Exynos 1380处理器,这枚处理器的CPU端采用了4 x A782400MHz)+4 x A552000MHz)架构,
...[详细] Belkin宣布发布移动电源、无线充电面板、音频产品等等多款产品。9月1号消息,Belkin宣布发布移动电源、无线充电面板、音频产品等等多款产品。首先是BoostCharge Pro无线充电垫15W,
...[详细]
Belkin宣布发布移动电源、无线充电面板、音频产品等等多款产品。9月1号消息,Belkin宣布发布移动电源、无线充电面板、音频产品等等多款产品。首先是BoostCharge Pro无线充电垫15W,
...[详细]中国中冶(601618)融资余额12.39亿元 融券余额1509.92万元(03
 中国中冶(601618)2021年3月23日融资融券信息显示,中国中冶融资余额1,239,806,726元,融券余额15,099,252元,融资买入额61,367,945元,融资偿还额72,876,6
...[详细]
中国中冶(601618)2021年3月23日融资融券信息显示,中国中冶融资余额1,239,806,726元,融券余额15,099,252元,融资买入额61,367,945元,融资偿还额72,876,6
...[详细] 全新的华硕无畏Pro15 2023不但维持了精致的外观设计和高辨识度的设计语言,在各项配置上更是做到堪比游戏本,同时依旧保持了轻盈便携的设计与优秀的扩展性,这样一台拥有全能配置和“无畏精神”的全能本,
...[详细]
全新的华硕无畏Pro15 2023不但维持了精致的外观设计和高辨识度的设计语言,在各项配置上更是做到堪比游戏本,同时依旧保持了轻盈便携的设计与优秀的扩展性,这样一台拥有全能配置和“无畏精神”的全能本,
...[详细] 凯撒文化(002425.SZ)公布消息:一季度净利润预增80%
凯撒文化(002425.SZ)公布消息:一季度净利润预增80% Western tank deliveries 'direct involvement' in Ukraine conflict: Kremlin
Western tank deliveries 'direct involvement' in Ukraine conflict: Kremlin 联想Legion眼镜亮相IFA展会,可搭配掌机一同使用
联想Legion眼镜亮相IFA展会,可搭配掌机一同使用 联通在线召开星空科技论坛,开启XR产业全新生态
联通在线召开星空科技论坛,开启XR产业全新生态 芝加哥农产品期价4日涨跌不一 大豆5月合约涨幅为0.21%
芝加哥农产品期价4日涨跌不一 大豆5月合约涨幅为0.21%
