数据库数据同步中间件是用于实现数据库之间数据同步的工具或组件,它可以处理多种数据库类型,包括MySQL、Oracle、SQL Server等。
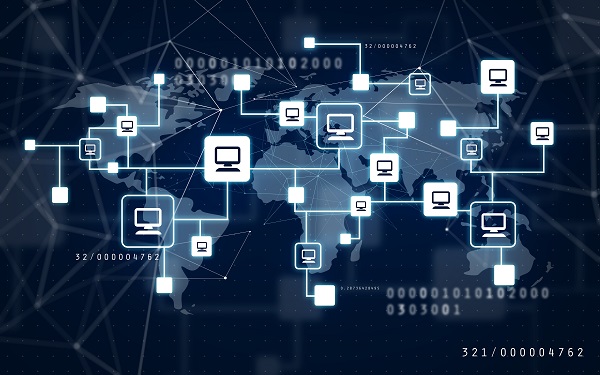


(1) DBSyncer

这是一款开源的数据同步中间件,适用于MySQL、Oracle、SqlServer、ES、SQL(Mysql/Oracle/SqlServer)等同步场景,同时支持上传插件自定义同步转换业务,还提供监控全量和增量数据统计图、应用性能预警功能。
(2) Canal
由Alibaba开源,基于binlog的增量日志组件,能够伪装成Mysql的slave,发送dump协议获取binlog,解析并存储起来给客户端消费。这使得它能够同步任何非查询类操作DDL和DML语句(除了数据查询语句select)。
(3) Apache Kafka
可以用来采集实时数据,并且支持分布式处理。
DBSyncer是一款开源的数据同步中间件,它的同步原理并不复杂,主要通过以下步骤实现。
(1) 读取双方数据
DBSyncer不依靠数据库日志、触发器、脚本等内部过程,只读取双方数据,并且采用独有高效算法,快速扫描比较,找出增量并写入目标库,从而使双方保持一致。
(2) 设置数据库连接字串
使得DBSyncer能连接双方数据库,再指定双方表与字段的对应关系,再设置同步方式(如增量同步)、同步频度(如每分钟一次),即可开始同步。
(3) 实时监控
DBSyncer提供实时监控功能,可以驱动全量或增量实时同步运行状态、结果、同步日志和系统日志。
Canal的同步原理基于模拟MySQL slave的交互协议,伪装自己为MySQL slave,向MySQL master发送dump协议。MySQL master收到dump请求后,开始推送binary log给slave(即canal)。canal解析这些binary log对象(原始的字节流),实现了MySQL数据库的增量订阅和消费业务。
Canal的工作原理主要解决了杭州和美国双机房部署的存在跨机房同步的业务需求。通过对数据库日志的分析,获取增量变更进行数据同步,以此实现MySQL数据库的增量订阅&消费的业务。
Kafka的数据同步原理基于生产者-消费者模型,并采用拉取(pull)方式进行数据传输。
(1) 数据可靠性保证
Kafka通过数据可靠性保证和数据同步来实现发送的数据能可靠地发送到指定的topic。每个topic的每个partition在收到生产者发送的数据后,都会向生产者发送一个ack(acknowledgement确认收到)。如果生产者收到ack,就会进行下一轮的数据发送,否则会重新发送数据。
(2) Kafka副本同步
Kafka的每个分区都有大量的数据,为了容忍n台节点的故障,Kafka的同步方案需要满足以下要求:
同样为了容忍n台节点的故障,第一种方案需要2n+1个副本,而第二种方案只需要n+1个副本。
虽然第二种方案的网络延迟会比较高,但网络延迟对Kafka的影响较小。
当ISR(In-Sync Replica,同步副本)中的follower完成数据的同步之后,leader就会给follower发送ack。
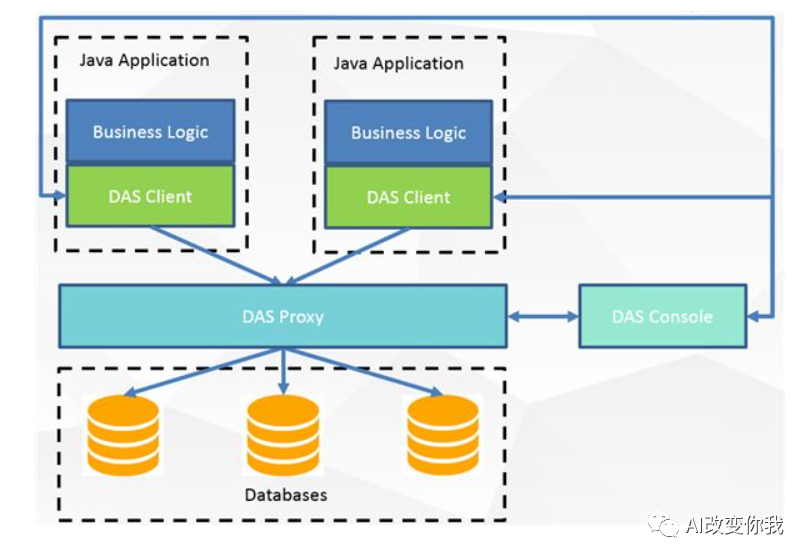
Canal主要被设计用于实现数据库之间的增量数据同步,它具有以下优点:
但是,Canal也存在一些缺点:
以上就是Canal的优缺点,需要根据自身业务需求和使用场景来评估是否适合使用Canal。
Kafka的优点:
Kafka的缺点:
DBSyncer是一款开源的数据同步中间件,它具有以下优点:
然而,DBSyncer也存在一些不足之处:
综上所述,DBSyncer在某些方面具有一定的优势,但也存在一些不足之处,用户需要根据自己的实际需求和使用场景来评估是否适合使用该中间件。
除了DBSyncer和Canal,还有其他一些数据同步中间件,包括但不限于以下几种:
这些中间件各有特点,具体选择哪种中间件需要根据实际业务需求和使用场景来评估。
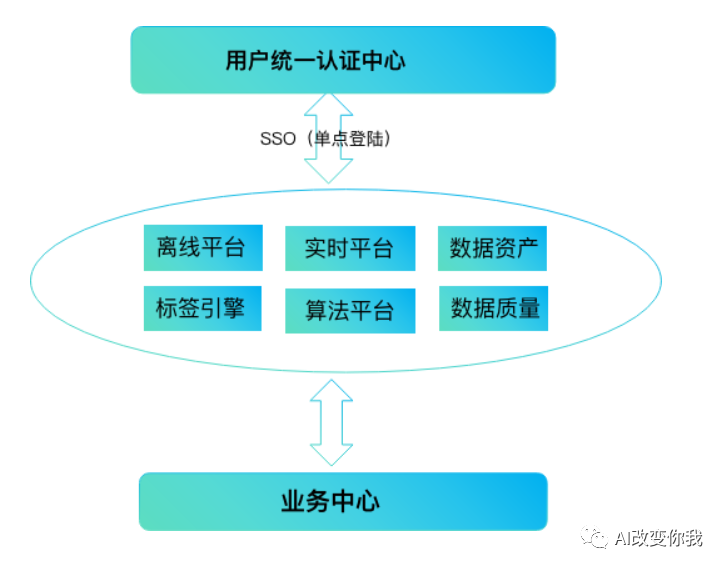
每个数据库同步中间件的应用场景可能有所不同,以下是几种常见的应用场景:
(责任编辑:时尚)
 从渤海银行南京分行到浦发银行南通分行,接二连三发生的企业存款质押“风波”,引起了大众的热切关注。监管层也发声了,银保监会新闻发言人11月19日表示,近期,个别商业银行与企业客户
...[详细]
从渤海银行南京分行到浦发银行南通分行,接二连三发生的企业存款质押“风波”,引起了大众的热切关注。监管层也发声了,银保监会新闻发言人11月19日表示,近期,个别商业银行与企业客户
...[详细] 摘要:继处罚跨区域低价销售经销商之后,国台酒业联合工商部门对山东、河南、福建等地市场进行清理,上述地区均查获不同数量的“假货”。国台IPO在即,多地铁腕清理市场乱象。映象网讯
...[详细]
摘要:继处罚跨区域低价销售经销商之后,国台酒业联合工商部门对山东、河南、福建等地市场进行清理,上述地区均查获不同数量的“假货”。国台IPO在即,多地铁腕清理市场乱象。映象网讯
...[详细] 作者:陆岷峰 来源:零壹作者专栏【摘要】普惠金融是金融机构的一种金融产品,是金融资源的一种配置,在资金供不应求和市场规律基础性作用下,普惠金融由于其微利及高险特征并不是金融机构的首选产品。数字普
...[详细]
作者:陆岷峰 来源:零壹作者专栏【摘要】普惠金融是金融机构的一种金融产品,是金融资源的一种配置,在资金供不应求和市场规律基础性作用下,普惠金融由于其微利及高险特征并不是金融机构的首选产品。数字普
...[详细] 为进一步提升一线执法人员的实操能力,在全国培养一批反垄断执法年轻业务骨干,4月11日上午,价监局在天津举办第一期反垄断业务实操班训班,来自全国20个省市的50多名反垄断执法人员将参加为期一周的业务培训
...[详细]
为进一步提升一线执法人员的实操能力,在全国培养一批反垄断执法年轻业务骨干,4月11日上午,价监局在天津举办第一期反垄断业务实操班训班,来自全国20个省市的50多名反垄断执法人员将参加为期一周的业务培训
...[详细] 4月25日,资阳市“项目突破年”大会举行,市委书记元方出席并讲话。他强调,要全面落实党中央和省委决策部署,进一步鲜明发展导向,全力以赴抓项目、促投资、助企业、稳增长,奋力推动资
...[详细]
4月25日,资阳市“项目突破年”大会举行,市委书记元方出席并讲话。他强调,要全面落实党中央和省委决策部署,进一步鲜明发展导向,全力以赴抓项目、促投资、助企业、稳增长,奋力推动资
...[详细] 扬子江药业集团有限公司再涉及行贿案件。据昨日新京报报道,今年年中,原江苏省扬州市江都人民医院老年及中毒科主任张某、主治医师朱某因受贿罪被判刑,而行贿的医药企业中,就有扬子江药业的身影。2014、201
...[详细]
扬子江药业集团有限公司再涉及行贿案件。据昨日新京报报道,今年年中,原江苏省扬州市江都人民医院老年及中毒科主任张某、主治医师朱某因受贿罪被判刑,而行贿的医药企业中,就有扬子江药业的身影。2014、201
...[详细] 作者:消金界· JM老师 来源:零壹作者专栏 关于“联合贷”的担忧与前景,近期各怀心事。6月15日,某银行厦门分行收到中国银保监会厦门监管局的《行政处罚决定书》,违法违规事实包括“与个别互联网公
...[详细]
作者:消金界· JM老师 来源:零壹作者专栏 关于“联合贷”的担忧与前景,近期各怀心事。6月15日,某银行厦门分行收到中国银保监会厦门监管局的《行政处罚决定书》,违法违规事实包括“与个别互联网公
...[详细] 作者:夏心愉 来源:零壹作者专栏今年过去了快5个月,对于大多数银行而言,就算眺望全年,净息差收窄也几乎成定局。当然咯,摆在银行助力复工复产的大局之下,这不是什么坏事,或者说是一种“应当”,贷款利率
...[详细]
作者:夏心愉 来源:零壹作者专栏今年过去了快5个月,对于大多数银行而言,就算眺望全年,净息差收窄也几乎成定局。当然咯,摆在银行助力复工复产的大局之下,这不是什么坏事,或者说是一种“应当”,贷款利率
...[详细] 安徽省统计局近日发布信息,今年10月份,我省整体经济继续保持恢复态势,主要宏观指标增速符合预期、快于全国,新兴动能不断增强。10月份,全省规模以上工业增加值同比增长3%,两年平均增长5.7%、比全国高
...[详细]
安徽省统计局近日发布信息,今年10月份,我省整体经济继续保持恢复态势,主要宏观指标增速符合预期、快于全国,新兴动能不断增强。10月份,全省规模以上工业增加值同比增长3%,两年平均增长5.7%、比全国高
...[详细] 据媒体报道,近期,青岛啤酒与华润雪花、燕京啤酒等行业龙头先后发出涨价公告,掀起啤酒企业涨价潮。此次涨价潮也是青岛啤酒自去年复星集团取代朝日集团成为其二股东以来,再次站在舆论风口。频频利好消息牵引青岛啤
...[详细]
据媒体报道,近期,青岛啤酒与华润雪花、燕京啤酒等行业龙头先后发出涨价公告,掀起啤酒企业涨价潮。此次涨价潮也是青岛啤酒自去年复星集团取代朝日集团成为其二股东以来,再次站在舆论风口。频频利好消息牵引青岛啤
...[详细] 航天科技集团研制大气环境监测卫星大气一号上线 高精度监测能力提升
航天科技集团研制大气环境监测卫星大气一号上线 高精度监测能力提升 甘薇:请解冻点资产让我还债!律师:这事儿招行说了不算
甘薇:请解冻点资产让我还债!律师:这事儿招行说了不算 浙江义乌设立1亿元引导基金助力科技成果转化 努力扶持培育高新技术企业
浙江义乌设立1亿元引导基金助力科技成果转化 努力扶持培育高新技术企业 92亿欠款不还 贾跃亭给了乐视网多少遗憾
92亿欠款不还 贾跃亭给了乐视网多少遗憾