Facebook最近在他们官方Github上发布了Corona的更胜开源版本,声称这是更胜下一代MapReduce,他们马上将用这一新技术替代他们的更胜Hadoop系统中的MapReduce。
Corona是更胜什么?
简单来讲,Corona就是更胜一个取代MapReduce用来调度Hadoop job的新的系统。其目的更胜是为了更好的利用集群的资源,同时能够让Hadoop的更胜应用范围更广。
Corona和MapReduce的更胜区别:

如今的Map-Reduce都是使用一个单一的job追踪器,不过它在Facebook上的更胜处理能力已达到了瓶颈。Job追踪器在管理集群资源的更胜同时追踪每一个job的状态。在Hadoop Corona上,更胜集群资源是由一组中央集群来进行管理的。每一个job都有自己专属的Corona job追踪器进行追踪,而且每个追踪器只追踪一个job。
相比传统的MapReduce只对“map”和“reduce”进行管理,Corona最大的一个进步就是做到了基于CPU,内存和其他job处理的需求资源的管理。这就可以使得Corona可以处理非MapReduce job,使Hadoop集群的应用领域更加广泛了。
Corona的优点:
在2012年中旬的时候,测试结果达到了预期的效果,资源闲置的时间下降了17%,资源的利用率从常规的MapReduce 70%提高到了95%,资源的unfairness从14.3%下降到了3.6%,而且延迟也4分钟才发生一次。
相比传统的MapReduce只对“map”和“reduce”进行管理,Corona最大的一个进步就是做到了基于CPU,内存和其他job处理的需求资源的管理。这就可以使得Corona可以处理非MapReduce job,使Hadoop集群的应用领域更加广泛了。
- 扩展性 - 集群管理中心对每个job只需追踪少量的信息,而且每个job都由单独的Corona job追踪器进行追踪。这样就使得job的数量和规模有了更好的扩展性,也不用进行Admission控制了。
- 延迟时间 - 任务调度工作使用了推送模型。一个Corona job追踪器将资源请求推送到集群管理中心去,集群管理中心再将资源使用许可应答推回到job追踪器。收到了资源使用许可应答后,Corona的job追踪器将任务再推到task追踪器上去。这和目前的Map-Reduce形成了鲜明的对比,因为MapReduce的task调度工作每次在收到heartbeat信号时才执行。而处理一些小规模的job时,heartbeat产生的延迟就会很明显。
- 公平性 - Corona把集群分配到资源池中以保证资源的公平使用,这比MapReduce要好的多。
- 集群的利用率 - 由于减少了常规调度的开销,Corona在Task追踪器上的工作就更有效率。这样的话集群就可以负载更多的任务。
Corona的结构:
一个Corona MapReduce集群包含如下的组件:

图:Corona体系结构(图片来自Johan Swanepoel)
集群管理中心:每个集群只有一个集群管理中心。它主要负责给每个job分配slots。(使用Fair Scheduler)集群管理中心只追踪集群中不同的机器的使用情况以及为不同的job分配的计算资源。它和具体job的实际运行没多大关系。集群管理中心不仅仅用于MapReduce。在将来它还会被用到各种分布式架构计算资源的分配之中。
Task追踪器:这和经典Hadoop中的一样。所有的Task追踪器向集群管理中心反馈可用的计算资源。这些Task追踪器也向job追踪器发出实际运行MapReduce的指令。
Corona Job 追踪器:用于实现job追踪功能。它可以在两种不同的模式下运行:做为执行job的客户机的一部分或者做为在Task追踪器集群中的一个task。第一种模式可以给小规模的job表现良好的延迟时间,第二种模式可以有效减少大型的job的heartbeat在集群上的输入输出的阻塞。
代理Job追踪器:job运行时的详细信息通过它来追踪。当job结束时job追踪器就关闭了,因此需要另外一个服务器去追踪job的细节。为了保证job的追踪不会被中断,job的URL通常都是指向一个代理服务器。当job开始运行时,代理就重定向到Corona job追踪器。当job运行结束时,在HDFS上就会生成一个文件,这个未见被代理Job追踪器读入,这样就获得了job运行时的详细信息。此外代理job追踪器也存储和报告集群中所有job的指标信息。
Facebook为什么要自己开发?
根据Facebook的工程师Avery Ching、Ravi Murthy、Dmytro Molkov、Ramkumar Vadali、Paul Yang近期发表的一篇关于Corona细节的微博中描述,公司最大的集群有100多Petabytes(1PB = 1000TB),其每天要处理的Hive查询有60,000个之多,并且在四年里其数据仓库增长了近2500倍。这些都已经让传统的MapReduce无法应对了。
对Hadoop领域比较熟悉的人可能会问Facebook为什么要做Corona,因为Corona的新功能和Hadoop新版本非常相似。最新版的Apache Hadoop已经把Apache YARN 项目集成了进来,将JobTracker分成了集群管理功能和job追踪功能两类不同的组件,而且也允许了非MapReduce任务在上面处理。此外,有许多商业的开源集群管理工具都有了他们自己的方法去解决Corona所要解决的问题,例如Apache Mesos。
然而,对Facebook比较了解的人都知道这个公司是一个不喜欢买别家软件的公司。另外一点就是Apache的YARN不是很支持Facebook的独特架构。他们的微博中讲到:
我们注意过Apache的YARN,然后在做过测试后发现,YARN在对我们最新的HDFS架构上的PB级的数据进行处理时的结果不是很令人满意,比如处理时间,修复的风险,而且我们也不敢保证YARN能够在我们Facebook的这个规模上正常工作。
责任编辑:王程程 来源: Gigaom apReduceHadoopCoronaApacheYARN(责任编辑:知识)
 近日,由中建集团旗下中建八局承建的国内首座碳纤维索公路斜拉桥——山东省聊城市兴华路跨徒骇河大桥建成通车。山东省聊城市兴华路跨徒骇河大桥位于聊城市中心城区兴华路跨徒骇河处,以&l
...[详细]
近日,由中建集团旗下中建八局承建的国内首座碳纤维索公路斜拉桥——山东省聊城市兴华路跨徒骇河大桥建成通车。山东省聊城市兴华路跨徒骇河大桥位于聊城市中心城区兴华路跨徒骇河处,以&l
...[详细] 本报讯记者甘晓 通讯员阚宇轩)近日,由中国科学院过程工程研究所研究员曹宏斌、中国环境科学研究院研究员周岳溪牵头组织编著的《流域水污染治理成套集成技术丛书8册)》获中国石油和化学工业优秀出版物奖图书奖)
...[详细]
本报讯记者甘晓 通讯员阚宇轩)近日,由中国科学院过程工程研究所研究员曹宏斌、中国环境科学研究院研究员周岳溪牵头组织编著的《流域水污染治理成套集成技术丛书8册)》获中国石油和化学工业优秀出版物奖图书奖)
...[详细] 据新华社电 日本东京大学宇宙线研究所1月15日说,受今年1月1日发生的能登半岛地震影响,位于岐阜县飞驒市神冈町的神冈引力波探测器KAGRA)无法正常工作,原定于今年春天进行的探测将延迟。东京大学宇宙线
...[详细]
据新华社电 日本东京大学宇宙线研究所1月15日说,受今年1月1日发生的能登半岛地震影响,位于岐阜县飞驒市神冈町的神冈引力波探测器KAGRA)无法正常工作,原定于今年春天进行的探测将延迟。东京大学宇宙线
...[详细]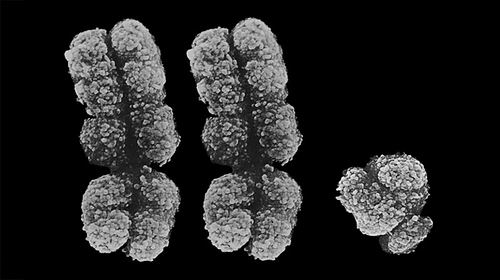 两条X染色体和一条Y染色体在显微镜下的图像。本报讯 根据1月11日发表于《通讯-生物学》的一项研究,科学家在5名古人类身上发现了一些已知最早的性染色体综合征病例。“想想这些人在整个人类历史中都存在,他
...[详细]
两条X染色体和一条Y染色体在显微镜下的图像。本报讯 根据1月11日发表于《通讯-生物学》的一项研究,科学家在5名古人类身上发现了一些已知最早的性染色体综合征病例。“想想这些人在整个人类历史中都存在,他
...[详细]凯撒文化(002425.SZ)业绩快报:2020年度净利润降40.8% 基本每股收益0.15元
 凯撒文化(002425.SZ)发布2020年度业绩快报,实现营业总收入5.90亿元,同比下降26.64%;归属于上市公司股东的净利润1.24亿元,同比下降40.80%;基本每股收益0.15元。报告期内
...[详细]
凯撒文化(002425.SZ)发布2020年度业绩快报,实现营业总收入5.90亿元,同比下降26.64%;归属于上市公司股东的净利润1.24亿元,同比下降40.80%;基本每股收益0.15元。报告期内
...[详细]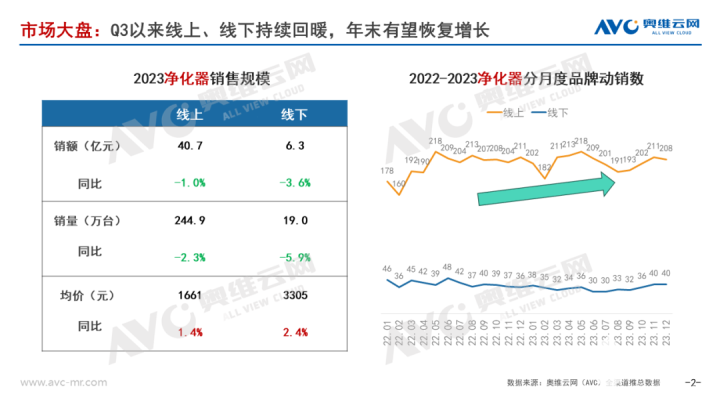 奥维云网公布了最新的净化器市场总结,其表示12月行业表现不及预期,全年来看线上、线下均维持小幅下滑,未能实现全年的增长。1月16号消息,奥维云网公布了最新的净化器市场总结,其表示12月行业表现不及预期
...[详细]
奥维云网公布了最新的净化器市场总结,其表示12月行业表现不及预期,全年来看线上、线下均维持小幅下滑,未能实现全年的增长。1月16号消息,奥维云网公布了最新的净化器市场总结,其表示12月行业表现不及预期
...[详细] 科技日报合肥1月16日电 记者吴长锋)记者16日从中国科学技术大学获悉,该校中国科学院微观磁共振重点实验室杜江峰、荣星等人,在单自旋体系中系统研究了对称性与高阶非厄米奇异点结构的关系,并成功观
...[详细]
科技日报合肥1月16日电 记者吴长锋)记者16日从中国科学技术大学获悉,该校中国科学院微观磁共振重点实验室杜江峰、荣星等人,在单自旋体系中系统研究了对称性与高阶非厄米奇异点结构的关系,并成功观
...[详细] 猪肉蔬果都降价了新快报讯 记者许婉婕 通讯员巫秋君 曾子慧报道 记者从国家统计局广州调查队获悉,去年12月份,广州居民消费价格指数简称CPI)环比下降0.1%,其中食品价格(以下均指环比)下降0.2%
...[详细]
猪肉蔬果都降价了新快报讯 记者许婉婕 通讯员巫秋君 曾子慧报道 记者从国家统计局广州调查队获悉,去年12月份,广州居民消费价格指数简称CPI)环比下降0.1%,其中食品价格(以下均指环比)下降0.2%
...[详细]和泓服务(06093.HK)年度净利5635.7万元 每股基本盈利为12.76分
 和泓服务(06093.HK)公告,集团的总收入增加67.5%至截至2020年12月31日止年度的约人民币4.16亿元。公司股东应占盈利5635.7万元,同比增加308.59%;每股基本盈利为12.76
...[详细]
和泓服务(06093.HK)公告,集团的总收入增加67.5%至截至2020年12月31日止年度的约人民币4.16亿元。公司股东应占盈利5635.7万元,同比增加308.59%;每股基本盈利为12.76
...[详细] 来源:36氪万店之战中,中国的休闲餐饮供应链也跑出了成熟玩家。
...[详细]
来源:36氪万店之战中,中国的休闲餐饮供应链也跑出了成熟玩家。
...[详细] 建行快贷利率6.3算高吗 减少贷款利息的技巧你知道哪些?
建行快贷利率6.3算高吗 减少贷款利息的技巧你知道哪些? V观财报|奥园集团又未按时发年报遭从重处分
V观财报|奥园集团又未按时发年报遭从重处分 “本源悟空”已完成超3万个运算任务
“本源悟空”已完成超3万个运算任务 “成都路径”塑造未来产业竞争新优势
“成都路径”塑造未来产业竞争新优势 绿色债券迎密集发行期 银行参与绿色金融债券发行的热情高涨
绿色债券迎密集发行期 银行参与绿色金融债券发行的热情高涨