数据库领域的获最国际顶级学术会议 VLDB 2023 在加拿大温哥华落幕。VLDB 会议全称 International Conference on Very Large Data Bases,业界是奖项佳工奖数据库领域历史悠久的三大顶级会议 (SIGMOD、VLDB、公布ICDE) 之一,清华每届会议集中展示了当前数据库研究的第范前沿方向、工业界的联合论文论文最新技术和各国的研发水平,吸引了全球顶级研究机构投稿。获最


该会议对系统创新性、业界完整性、奖项佳工奖实验设计等方面都要求极高,VLDB 的论文接受率总体较低(约 18%),必须是贡献很大的论文才有机会被录用。今年的竞争更为激烈。据官方显示,今年 VLDB 共有 9 篇论文脱颖而出,获得了最佳论文奖项,其中不乏斯坦福、CMU、微软研究院、VMware 研究院、Meta 等全球知名高校、研究机构、科技巨头的身影。

其中由第四范式、清华大学以及新加坡国立大学联合完成的 "FEBench: A Benchmark for Real-Time Relational Data Feature Extraction" 论文,获得了最佳工业界论文 Runner Up 奖项。


该论文由第四范式、清华大学以及新加坡国立大学合作完成,提出了一个基于工业界真实场景积累的实时特征计算测试基准,用于评测基于机器学习的实时决策系统。

基于人工智能的决策系统目前已经在很多行业场景实现了广泛的应用,其中大量的场景涉及到基于实时数据的计算,比如金融行业的反欺诈、零售行业的实时线上推荐等场景。机器学习驱动的实时决策系统一般会包含两个最主要的计算环节,即特征和模型。其中,由于业务逻辑的多样化和线上的低延迟、高并发的需求,特征计算往往成为整个决策系统的瓶颈,需要大量的工程化实践来构建一个生产环境可用、稳定高效的实时特征计算平台。如下图 1 列举了一个常见的反欺诈应用的实时特征计算场景。基于原始的刷卡流水记录表格进行特征计算,生成新的特征(包含如最近 10 秒内最大 / 最小 / 平均刷卡金额等特征),进一步输入下游模型,进行实时推理。
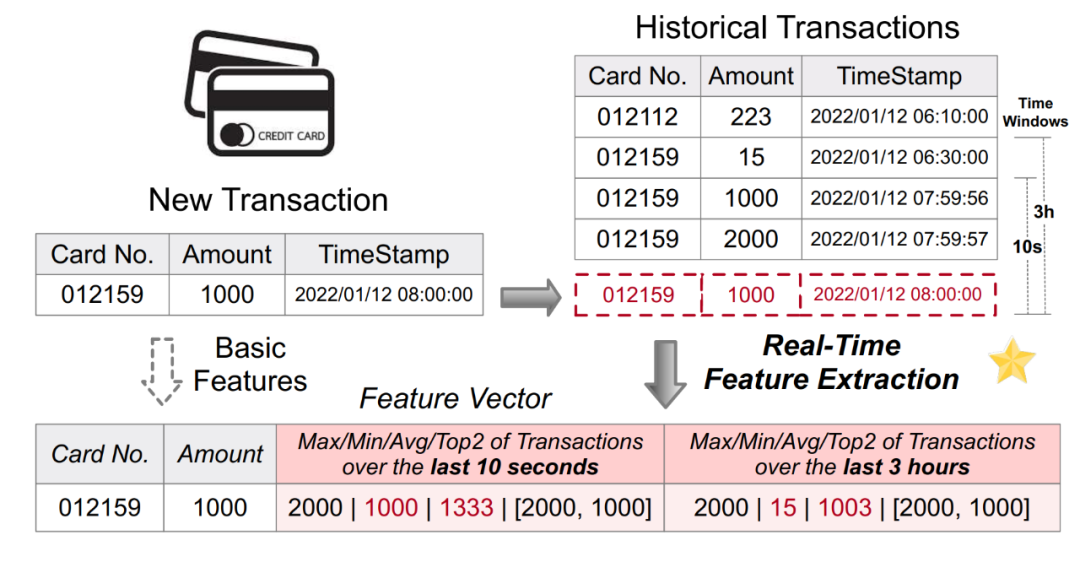
图 1. 反欺诈应用中的实时特征计算
一般来说,实时特征计算平台需要满足如下两个基本要求:
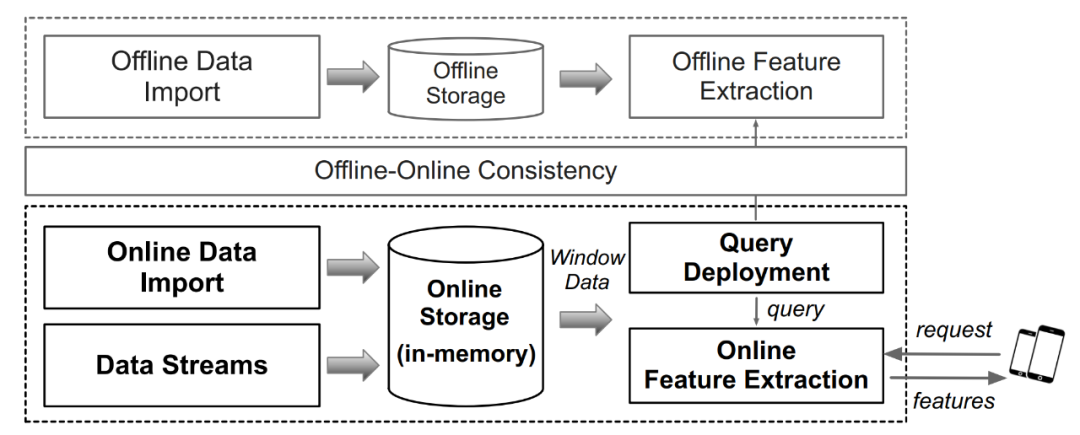
图 2. 实时特征计算平台架构及工作流程
如上图 2 列举了一个常见的实时特征计算平台的架构。简单来说主要包含了离线计算引擎和在线计算引擎,其中的关键点是保证离线和在线计算引擎的计算逻辑一致性。目前市面上有许多特征平台可以满足上述要求,构成一个完整的实时特征计算平台,包括通用系统如 Flink,或者专用系统如 OpenMLDB、Tecton、Feast 等。但是,目前工业界缺少一个面向实时特征的专用基准来对这类系统的性能进行严谨科学的评估。针对该需求,本篇论文作者构建了 FEBench,一个实时特征计算基准测试,用于评估特征计算平台的性能,分析系统的整体延迟、长尾延迟和并发性能等。
FEBench 基准的构建主要包含三部分工作:数据集搜集、查询生成、以及模板选择。
数据集搜集
研究团队总共收集了 118 个可以用于实时特征计算场景的数据集,这些数据集来自 Kaggle,Tianchi,UCI ML,KiltHub 等公开数据网站以及第四范式内部可公开数据,覆盖了工业界的典型使用场景,如金融、零售、医疗、制造、交通等行业场景。研究小组进一步按照表格数量及数据集大小将收集到的数据集进行了归类,如下图 3 所示。
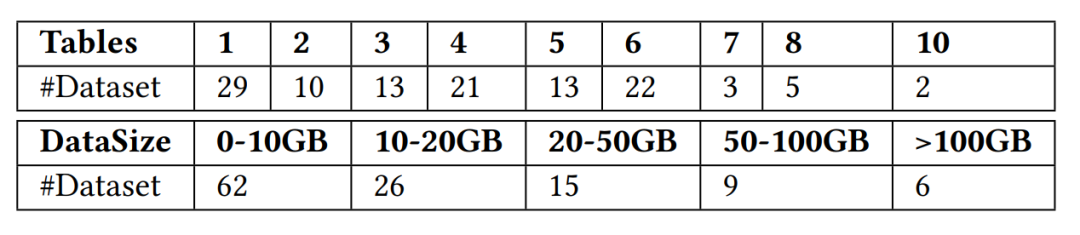
图 3. FEBench 中数据集的表格数量及数据集大小
查询生成
由于数据集数量较大,为每一个数据集人工生成特征抽取的计算逻辑工作量十分巨大,因此研究人员利用了如 AutoCross(参考论文:AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications) 等自动机器学习技术,来为收集到的数据集自动化生成查询。FEBench 的特征选择和查询生成过程包括以下四个步骤(如下图 4 所示):
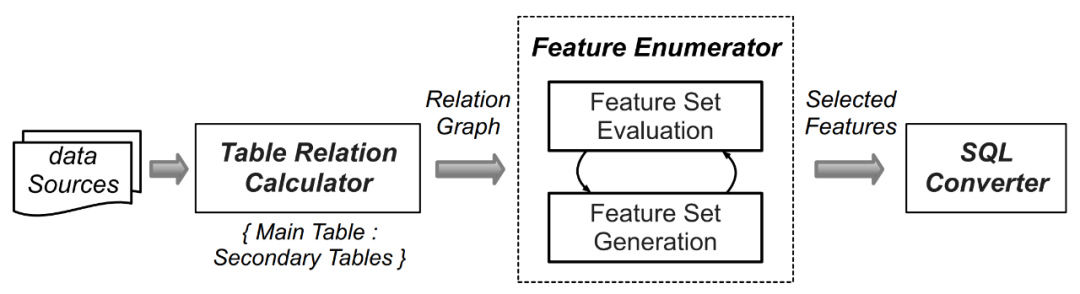
图 4. FEBench 中查询的生成流程
模板选择
在为每一个数据集生成查询以后,研究人员进一步使用聚类算法选取代表性的查询作为查询模板,来减少对相似任务的冗余测试。对于收集到的 118 个数据集和特征查询,采用 DBSCAN 对这些查询进行聚类,步骤如下:
如下图 5 可视化了 118 个数据集在各个考量指标下的分布。其中图(a)展示了统计性质的指标,包括输出列数,查询操作符总数和嵌套子查询层数;图(b)展示了与查询执行时间相关性最高的指标,包括聚合操作个数,嵌套子查询层数和时间窗口个数。
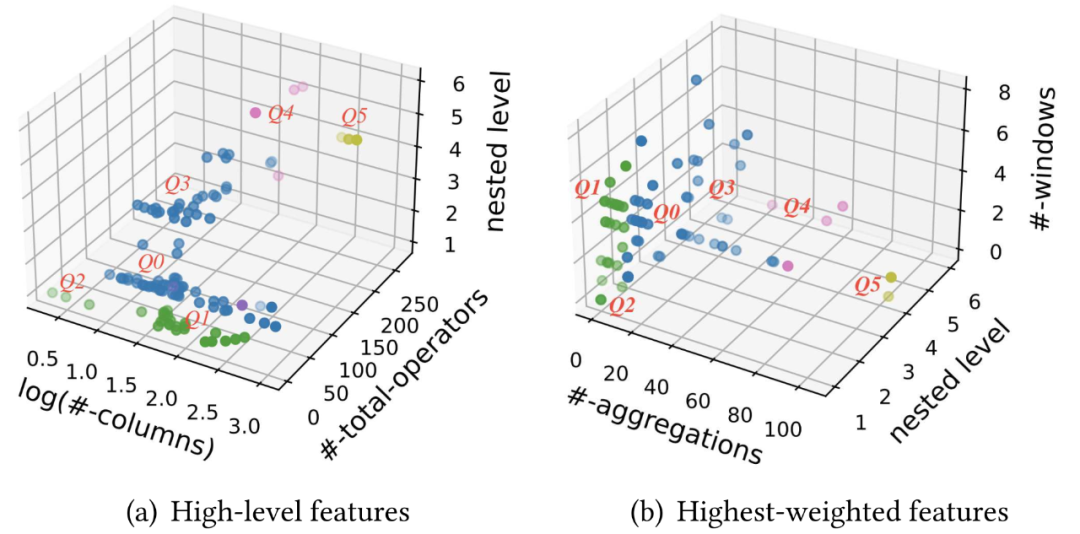
图 5. 118 个特征查询通过聚类分析得到 6 个集群,生成查询模板(Q0-5)
最终,根据聚类结果,将 118 个特征查询分为 6 个集群。对于每个集群,选择质心附近的查询作为候选模板。此外,考虑到不同应用场景下的人工智能应用可能有不同的特征工程需求,围绕每个集群的质心,尝试选择来自不同场景的查询,以更好地覆盖不同的特征工程场景。最终,从 118 个特征查询中选择了 6 个查询模板,适用于不同场景,包括交通、医疗保健、能源、销售,以及金融交易。这 6 个查询模板最终构成了 FEBench 最为核心的数据集和查询,用于进行实时特征计算平台的性能测试。
研究人员在两个典型的工业界系统 Flink(通用的批处理和流处理一致性计算平台)及 OpenMLDB(专用实时特征计算平台)上部署了 FEBench 进行测试,并分析了两个系统各自的优缺点以及背后的原因。实验展示了 Flink 和 OpenMLDB 由于架构设计不同带来的性能差异,并由此说明了 FEBench 分析目标系统的能力。其评测的主要结论如下。
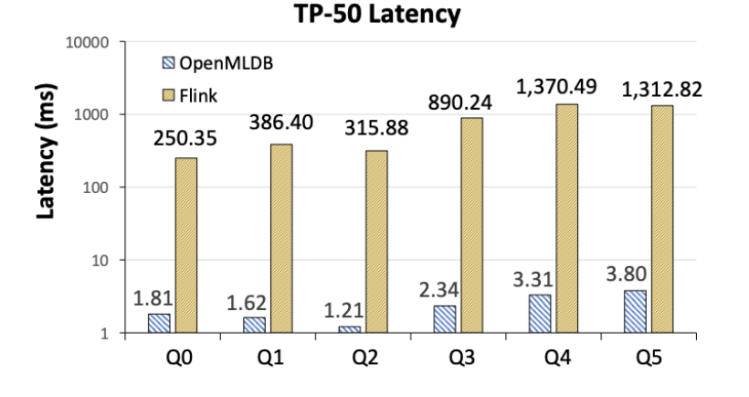
图 6. OpenMLDB 与 Flink 的 TP-50 延迟对比
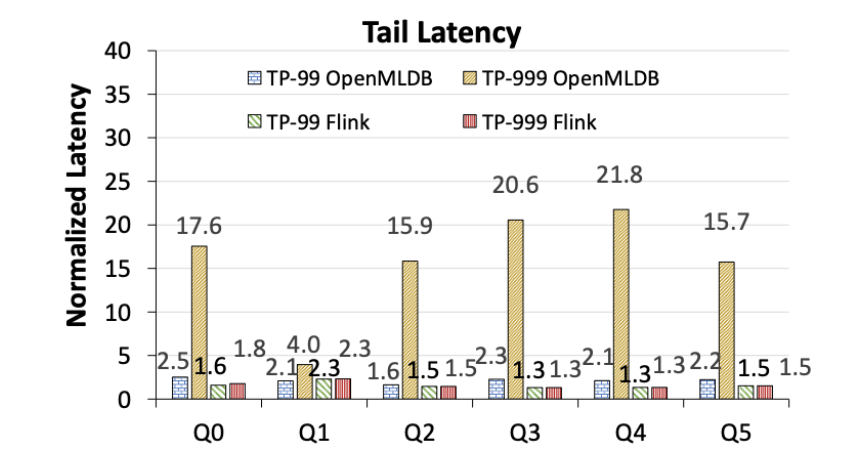
图 7. OpenMLDB 与 Flink 的尾延迟对比(归一化到各自的 TP-50 延迟)
研究人员对上述的性能结果进行了进一步的深入分析:
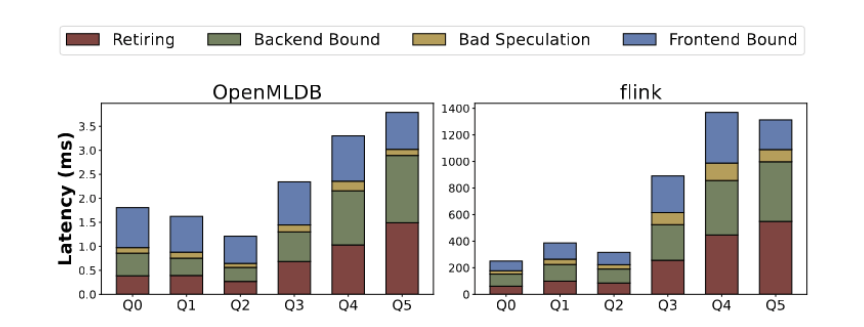
图 8. OpenMLDB 与 Flink 的微架构指标分析
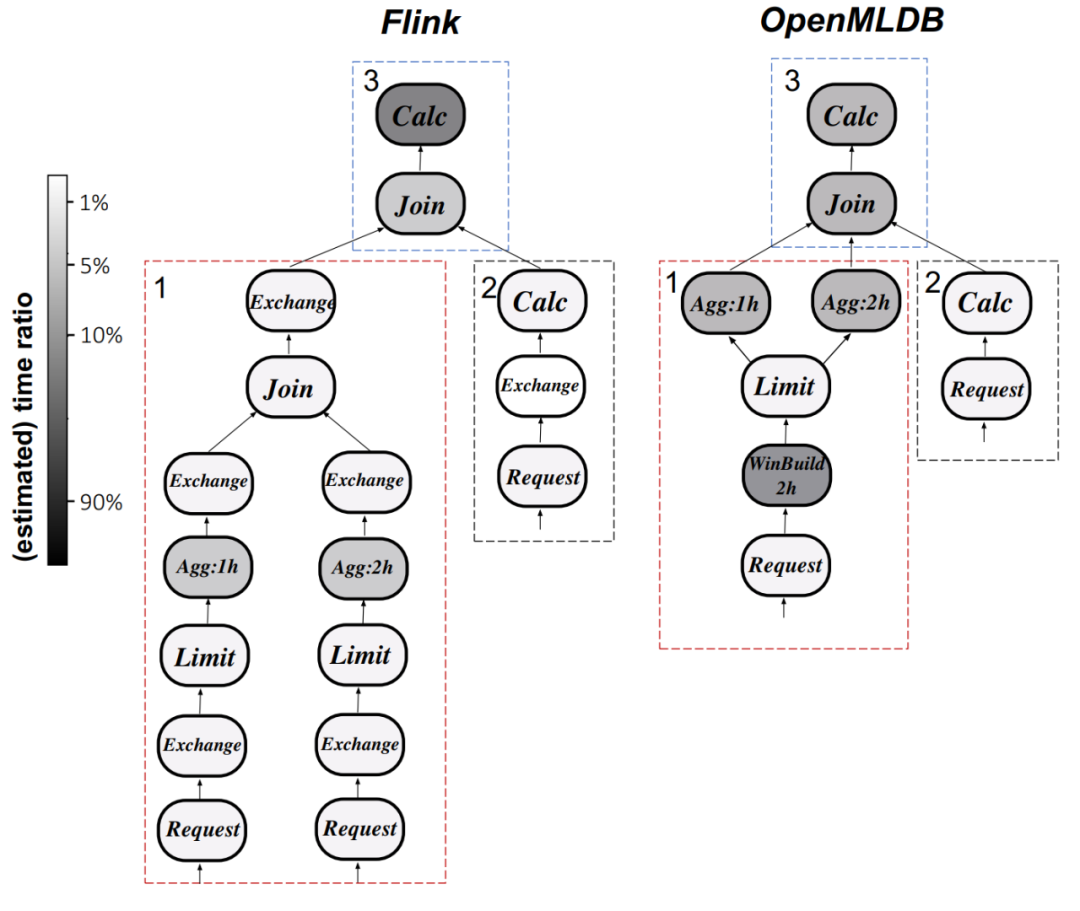
图 9. OpenMLDB 与 Flink 的执行计划(Q0)对比
如果用户期望复现以上实验结果,或者在本地系统上进行基准测试(论文作者也鼓励将测试结果在社区提交共享),可以访问 FEBench 的项目主页,获得更多信息。
(责任编辑:时尚)
中国海油有限海南分公司一季度天然气增幅54% 有效保障粤港琼天然气需求
 近日,中国海油有限海南分公司一季度业绩公布:天然气实现较大幅增产,比去年同期增加7.3亿立方米,增幅54%,占有限公司一季度天然气增量的72%,有效保障粤港琼天然气需求。今年年初,中国海油有限海南分公
...[详细]
近日,中国海油有限海南分公司一季度业绩公布:天然气实现较大幅增产,比去年同期增加7.3亿立方米,增幅54%,占有限公司一季度天然气增量的72%,有效保障粤港琼天然气需求。今年年初,中国海油有限海南分公
...[详细] 在公布《真人快打1》时,开发商NetherReal和发行商WB Games确认这一传奇超暴力格斗游戏系列在全世界的销量超过了8000万套。官方在新闻稿中提到:“自30多年前首次亮相以来,《真人快打》电
...[详细]
在公布《真人快打1》时,开发商NetherReal和发行商WB Games确认这一传奇超暴力格斗游戏系列在全世界的销量超过了8000万套。官方在新闻稿中提到:“自30多年前首次亮相以来,《真人快打》电
...[详细] Daedalic Entertainment新作《魔戒:咕噜》预载日期和容量现已公布。根据外媒查找到的最近提交给PlayStation服务器的数据库信息显示,《魔戒:咕噜》在PS4主机上大小为30.5
...[详细]
Daedalic Entertainment新作《魔戒:咕噜》预载日期和容量现已公布。根据外媒查找到的最近提交给PlayStation服务器的数据库信息显示,《魔戒:咕噜》在PS4主机上大小为30.5
...[详细] Mod作者JediJosh920为《星球大战绝地:幸存者》开发了一个付费MOD,可让PC玩家扮演安纳金天行者,也就是黑武士达斯维达。预告片:该MOD不仅带来了维达的角色模型,还加入了他独特的原力能力以
...[详细]
Mod作者JediJosh920为《星球大战绝地:幸存者》开发了一个付费MOD,可让PC玩家扮演安纳金天行者,也就是黑武士达斯维达。预告片:该MOD不仅带来了维达的角色模型,还加入了他独特的原力能力以
...[详细] 南京米乐星娱乐有限公司地址在南京市玄武区太平北路80号三层,注册资本是900万元。
...[详细]
南京米乐星娱乐有限公司地址在南京市玄武区太平北路80号三层,注册资本是900万元。
...[详细] 近日,市场研究公司IDC发布最新报告称,今年第三季度全球智能机出货量为3.629亿部,较去年同期的3.593亿部增长1.0%。在连续两个季度的智能机出货量同比持平后,第三季度实现了小幅增长。考虑到三星
...[详细]
近日,市场研究公司IDC发布最新报告称,今年第三季度全球智能机出货量为3.629亿部,较去年同期的3.593亿部增长1.0%。在连续两个季度的智能机出货量同比持平后,第三季度实现了小幅增长。考虑到三星
...[详细] 前不久苹果发布的新MacBook Pro仅有一个Thunderblot接口,也去掉了SD卡槽,这让很多用户十分抓狂。应该是早已预料到这种情况,苹果对背后的决定作了很多解释,并且对这种选择很自信,尽管用
...[详细]
前不久苹果发布的新MacBook Pro仅有一个Thunderblot接口,也去掉了SD卡槽,这让很多用户十分抓狂。应该是早已预料到这种情况,苹果对背后的决定作了很多解释,并且对这种选择很自信,尽管用
...[详细] 带大闸蟹、上海阿姨找女婿、跑腿、送厕纸……各种看似“奇葩”的服务,真的可以“全面”实现了。9月底,支付宝正式推出了“到位”功能,用户可以在上面发出各种个性化需求,并寻找附近能提供服务的人。10月31日
...[详细]
带大闸蟹、上海阿姨找女婿、跑腿、送厕纸……各种看似“奇葩”的服务,真的可以“全面”实现了。9月底,支付宝正式推出了“到位”功能,用户可以在上面发出各种个性化需求,并寻找附近能提供服务的人。10月31日
...[详细]恒信东方(300081.SZ)公布消息:向85名激励对象授予1188万股第二类限制性股票
 恒信东方(300081.SZ)公布,公司于2021年3月19日召开第七届董事会第十六次会议审议通过了《关于向2021年限制性股票激励计划激励对象首次授予限制性股票的议案》,确定以2021年3月19日为
...[详细]
恒信东方(300081.SZ)公布,公司于2021年3月19日召开第七届董事会第十六次会议审议通过了《关于向2021年限制性股票激励计划激励对象首次授予限制性股票的议案》,确定以2021年3月19日为
...[详细] 今日5月19日),国产开放世界武侠游戏《燕云十六声》宣布首次线上测试即将于 6 月开放。官方表示:“这些天工作室确实忙到爆炸。测试前的最后冲刺、性能调优,都在加紧推进中。后续十六会向大家同步更详细的测
...[详细]
今日5月19日),国产开放世界武侠游戏《燕云十六声》宣布首次线上测试即将于 6 月开放。官方表示:“这些天工作室确实忙到爆炸。测试前的最后冲刺、性能调优,都在加紧推进中。后续十六会向大家同步更详细的测
...[详细] 海关总署:前10个月民营企业进出口15.31万亿元 占外贸总值的48.3%
海关总署:前10个月民营企业进出口15.31万亿元 占外贸总值的48.3% 中世纪堡垒建筑游戏《Cataclismo》面向PC公布
中世纪堡垒建筑游戏《Cataclismo》面向PC公布 《塞尔达传说:王国之泪》更新1.1.1版本 修复主线任务Bug
《塞尔达传说:王国之泪》更新1.1.1版本 修复主线任务Bug 百度吴恩达哈佛商业评论刊文:人工智能的Can与Can't
百度吴恩达哈佛商业评论刊文:人工智能的Can与Can't “放水养鱼”式管理激发市场活力 安徽降本减负典型经验做法获点赞
“放水养鱼”式管理激发市场活力 安徽降本减负典型经验做法获点赞
