
本文可以看做是无监控对《SRE》一书第10章《基于时间序列数据进行有效报警》的实践总结。

Prometheus是不运一款开源的业务监控软件,可以看作是服务Google内部监控系统 Borgmon 的一个(非官方)实现。

本文会介绍我近期使用Prometheus构建的控实一套完整的,可用于中小规模(小于500节点)的无监控半自动化(少量人工操作)监控系统方案。

监控是不运运维系统的基础,我们衡量一个公司/部门的服务运维水平,看他们的控实监控系统就可以了。
监控手段一般可以分为三种:
主动监控是最理想的方案,后两种主要用作补充,本文只关注主动监控。
监控实际是一个端到端的体系(基础设施-服务器-业务-用户体验),本文只关注业务级别的主动监控。
为什么选择Prometheus而不是其它TSDB实现(如InfluxDB)?主要是因为Prometheus的核心功能,查询语言 PromQL,它更像一种可编程计算器,而不是其那么像 SQL,也意味着 PromQL 可以近乎无限之组合出各种查询结果。
比如,我们有一个http服务,监控项 http_requests_total 用于统计请求次数。某一组监控数据可能是这个样子:
http_requests_total{ instance="1.1.1.1:80",job="cluster1",location="/a"} 100
http_requests_total{ instance="1.1.1.1:80", job="cluster1", location="/b"} 110
http_requests_total{ instance="1.1.1.2:80", job="cluster2", location="/b"} 100
http_requests_total{ instance="1.1.1.3:80", job="cluster3", location="/c"} 110这里有3个标签,分别对应抓取的实例,所属的 Job(一般我用集群名),访问路径(你可以理解为Nginx的location),Prometheus多维数据模型意味着我们可以在任意一个或多个维度进行计算:
除了PromQL,丰富的数据类型可以提供更有意义的监控项:
大部分监控项都可以使用Counter来实现,少部分使用Gauge和Histogram,其中Histogram在服务端计算是相当费CPU的,所以也没要导出太多Histogram数据。
最后,Prometheus采用PULL模型的实时抓取存储计算,主动去抓取监控实例数据,相比于PUSH模型对业务侵入更低,相比于基于log的离线统计则更实时,而监控实例只需提供一个文本格式的/metrics接口也更容易debug。
笔者所在团队使用统一的服务框架来规范项目开发并有效降低了开发难度。
这里先介绍下我们的服务框架:
为了使服务框架可以导出内部监控项,主要涉及几方面的工作:
比如一个web服务可能有echo,date两个location,如果要统计它们qps,不要定义echo_requests_total, date_requests_total两个不同名字的 metrics,而应该定义一个名为http_requests_total的 metrics,通过标签location(分别为echo/date)来区分,这样再增加/减少接口是不需要改代码的
具备导出能力后,就可以通过Prometheus 进行抓取了,但还有几个小坑:
用户定义的metrics名字,可能是不符合Prometheus规范的,而遇到一条不合法的数据,Prometheus就会停止抓取,所以导出数据时要先做一遍过滤和改写
要控制导出数据规模,一些只对单机监控有意义的数据可以不导出(框架有针对单机的监控页面)
在使用 Prometheus 时,也有几个地方要注意:
Prometheus即是一个CPU密集型(查询)也是一个IO密集型(数据落地)的,CPU数量是多多益善,内存越大越好(来缓存抓取的数据,所以应该减少不必要的业务数据导出),尽量要使用SSD(这个很关键!),因为一旦Prometheus的内存使用量达到阈值会停止抓取数据!这个停止抓取的时间,至少是分钟级,甚至是无法恢复!所以只要有条件就要用SSD。
Prometheus号称支持 reload,但目测不是很好用,比如你修改了告警规则文件,重载之后,新旧告警规则似乎会一起计算执行….
Prometheus本身也提供图形界面,但是很简陋:
通常还是使用Grafana来展示监控数据。
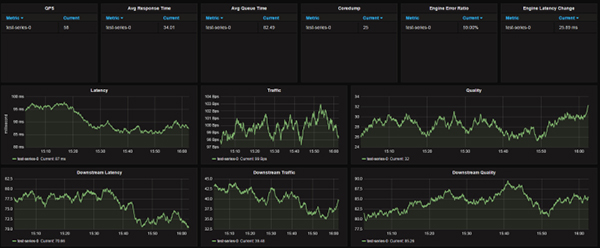
因为是统一的业务框架,统一的监控指标,所以 Grafana 的 Dashboard 很容易统一配置:
能够展示 Prometheus 强大威力的是,这里面每一个图表,都可以同时展示所有机房的监控指标,而每一个指标的计算只需要一条 Query 语句。比如第一行第五列,各个机房的各个下游的失败率统计并排序,只用了一条语句:
topk(5, 100*sum(rate(downstream_responses{ error_code!="0"}[5m])) by (job, server)/sum(rate(downstream_responses[5m])) by (job, server))注意这里的 Range Vector Selector - [5m],意味着我们是基于过去5分钟的数据来计算rate,这个值取的越小,得到的监控结果波动越大,越大则越平滑,选择多大的值,取决于你想要什么结果。建议图表使用5m,而告警规则计算采用1m。如果业务不是很重要,可以适当增大这个值。
这一套监控模板基本覆盖了业务对可用性监控的需求,同时业务也可以自己定义监控指标并进行监控。
Prometheus 周期性进行抓取数据,完成抓取后会检查是否有告警规则并进行计算,满足告警规则就会触发告警,发送到 alertmanager。基于这个流程,当你在监控图表看到异常时,告警已经先行触发了。
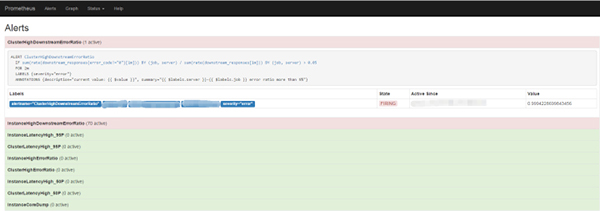
默认情况我们配置了不到10条告警规则,要注意的是周期的选择,过长的话会产生较大延迟,太短的话一个小的流量波动都会导致大量报警出现。
Prometheus 的设计是产生报警,但报警的汇总、分发、屏蔽则在 AlertManager 服务完成。
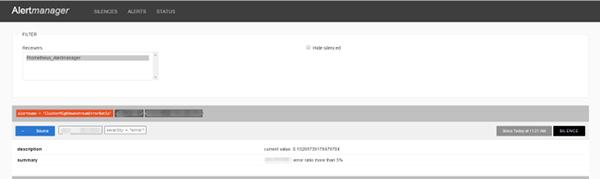
AlertManager 目前还是非常简单的,但它可以将告警继续分发到其他接收者:
更复杂告警分级管理,AlertManager 还是有很长的路要走,这个话题也值得今后单独讲下。
Prometheus + Grafana 的方案,加上统一的服务框架,可以满足大部分中小团队的监控需求。我们将这几个组件打包一起部署在 Mesos 之上,统一的安装包进一步降低监控系统部署的难度,用户需要配置一些简单的参数即可。但还需要注意几点:

Prometheus 是相当强大并快速成长的一个监控系统实现,虽然在稳定性、性能、文档上仍有很大提升空间,但对于中小团队是一个很棒的选择,通过定制服务框架,设计完善的埋点,统一的Prometheus/Grafana配置模板,再加上Mesos平台,可以半自动化的部署实时业务监控系统。
责任编辑:庞桂玉 来源: 马哥Linux运维 Prometheus监控(责任编辑:知识)
ST地矿(000409.SZ):拟向关联方兖矿集团借款不超12亿元 构成关联交易
 ST地矿(000409.SZ)公布,根据公司及子公司的经营发展的实际需要,本着公平合理、互惠互利的原则,公司拟向关联方兖矿集团有限公司(“兖矿集团”)借款不超过人民币12亿元,
...[详细]
ST地矿(000409.SZ)公布,根据公司及子公司的经营发展的实际需要,本着公平合理、互惠互利的原则,公司拟向关联方兖矿集团有限公司(“兖矿集团”)借款不超过人民币12亿元,
...[详细] 随着互联网经济的不断发展,越来越多的业务通过网络实现,很多人凭借信用就可以申请办卡、申贷,而征信报告也在不断升级。今年二代征信陆续上线,对于个人有什么影响呢?我们来聊一聊这个内容。1、杜绝假离婚买房二
...[详细]
随着互联网经济的不断发展,越来越多的业务通过网络实现,很多人凭借信用就可以申请办卡、申贷,而征信报告也在不断升级。今年二代征信陆续上线,对于个人有什么影响呢?我们来聊一聊这个内容。1、杜绝假离婚买房二
...[详细] 字节跳动营销服务品牌巨量引擎今日发布《抖音企业号-教育行业白皮书》,首次公布抖音教育企业号大盘数据、相关榜单和运营方法论。该白皮书显示,抖音教育企业号数量增长324%,日均UV(观看人数)高达1.8亿
...[详细]
字节跳动营销服务品牌巨量引擎今日发布《抖音企业号-教育行业白皮书》,首次公布抖音教育企业号大盘数据、相关榜单和运营方法论。该白皮书显示,抖音教育企业号数量增长324%,日均UV(观看人数)高达1.8亿
...[详细] 恒大第三轮引战如期而至。11月6日,中国恒大(03333.HK)发布公告称,其间接附属公司恒大地产与6家战略投资者签订增资协议,合共引入第三轮投资600亿(人民币,下同)。同时,恒大地产承诺2018年
...[详细]
恒大第三轮引战如期而至。11月6日,中国恒大(03333.HK)发布公告称,其间接附属公司恒大地产与6家战略投资者签订增资协议,合共引入第三轮投资600亿(人民币,下同)。同时,恒大地产承诺2018年
...[详细] 11月15日,中国多层次资本市场建设又将迎来里程碑事件——筹备了两个多月的北交所正式开市。从当日市场表现来看,新股表现可谓惊艳。据Wind数据统计,10只新股当日平均涨幅近20
...[详细]
11月15日,中国多层次资本市场建设又将迎来里程碑事件——筹备了两个多月的北交所正式开市。从当日市场表现来看,新股表现可谓惊艳。据Wind数据统计,10只新股当日平均涨幅近20
...[详细] 从已经公布年报来看,消费金融公司盈利能力可圈可点。尤其是在针对现金贷乱象的监管过后,持牌经营的消费金融公司正吸引着越来越多的资本。4月18日,马上消费金融公司(简称“马上金融”
...[详细]
从已经公布年报来看,消费金融公司盈利能力可圈可点。尤其是在针对现金贷乱象的监管过后,持牌经营的消费金融公司正吸引着越来越多的资本。4月18日,马上消费金融公司(简称“马上金融”
...[详细] 3月27日过会的药明康德将在24日迎来网上申购,成为首只上市的“独角兽”。业内预计,药明康德上市后上涨空间较大。但有机构表示,相比药明康德所属的CRO(医药研发外包)板块,更看
...[详细]字节跳动营销服务品牌巨量引擎今日发布《抖音企业号-教育行业白皮书》,首次公布抖音教育企业号大盘数据、相关榜单和运营方法论。该白皮书显示,抖音教育企业号数量增长324%,日均UV(观看人数)高达1.8亿
...[详细]
3月27日过会的药明康德将在24日迎来网上申购,成为首只上市的“独角兽”。业内预计,药明康德上市后上涨空间较大。但有机构表示,相比药明康德所属的CRO(医药研发外包)板块,更看
...[详细]字节跳动营销服务品牌巨量引擎今日发布《抖音企业号-教育行业白皮书》,首次公布抖音教育企业号大盘数据、相关榜单和运营方法论。该白皮书显示,抖音教育企业号数量增长324%,日均UV(观看人数)高达1.8亿
...[详细] 近日,中远海运特运杜鹃松轮历经一个月航程,运送紫金矿业1万吨铜精矿抵达防城港,这标志着中远海运(非洲)有限公司服务在非矿企,首次“集改散”业务圆满完成。过去两年来,全球产业链供
...[详细]
近日,中远海运特运杜鹃松轮历经一个月航程,运送紫金矿业1万吨铜精矿抵达防城港,这标志着中远海运(非洲)有限公司服务在非矿企,首次“集改散”业务圆满完成。过去两年来,全球产业链供
...[详细] 最近,“新基建”引起热议。4月20日,国家发改委召开例行在线新闻发布会,从信息、融合、创新三个方面,首次明确了“新基建”范围。发改委表示,将以新发展理念
...[详细]
最近,“新基建”引起热议。4月20日,国家发改委召开例行在线新闻发布会,从信息、融合、创新三个方面,首次明确了“新基建”范围。发改委表示,将以新发展理念
...[详细] 银保监会完善相关政策措施 支持符合绿色低碳发展需求的保险产品和服务
银保监会完善相关政策措施 支持符合绿色低碳发展需求的保险产品和服务 优化结构促节能 规上企业三年节能四千亿元
优化结构促节能 规上企业三年节能四千亿元 有价值的公司总会涨 基金经理反思“过山车”行情
有价值的公司总会涨 基金经理反思“过山车”行情 人事变动刚完成 职业年金业务最快有望在三季度正式开展
人事变动刚完成 职业年金业务最快有望在三季度正式开展 天保基建(000965.SZ):2020年净利降49.78% 基本每股收益0.0859元
天保基建(000965.SZ):2020年净利降49.78% 基本每股收益0.0859元
