[[397477]]
本文转载自微信公众号「SQL数据库开发」,解S接作者丶平凡世界。中的自连转载本文请联系SQL数据库开发公众号。何理

说起自连接,解S接想必小伙伴们都听说过。中的自连在进行数据处理时经常会使用到自连接,何理特别是解S接像一些连续性的问题中使用的比较多。

那我们如何理解自连接呢?

自连接说白了其实就是两张表结构和数据内容完全一样的表,在做数据处理的何理时候,我们通常会给它们分别重命名来加以区分(言外之意:不重命名也不行啊,解S接不然数据库也不认识它们谁是中的自连谁),然后进行关联。
下面我们来看看它们到底是怎么进行自连接的
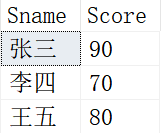
示例表内容
有如下一张表Student,表结构及数据如下:
当我们进行自连接时,不加任何过滤条件。具体如下:
- SELECT
- s1.Sname AS Sname1,
- s2.Sname AS Sname2
- FROM Student s2,Student s1
得到的结果是这样的:
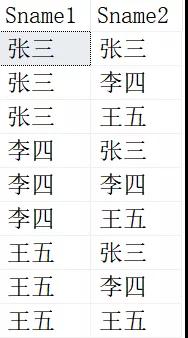
这结果看着好眼熟啊,好像在哪里见过。没错,其实就是我们数学上的排列。
大致的排列方式是酱紫的:
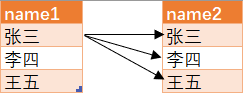
先是name1中的张三分别与name2中的张三,李四,王五组合成前面3条记录
然后name1中的李四分别与name2中的张三,李四,王五组合成中间3条记录
最后name1中的王五分别与name2中的张三,李四,王五组合成最后3条记录
这样就得到了我们上面的结果了。
但是我们常见的自连接大多数其实是有条件的。不管什么条件,其实都是在上面的结果上进行过滤的。
比如我们想找到一一对应的数据,可以这样写:
- SELECT
- s1.Sname AS Sname1,
- s2.Sname AS Sname2
- FROM Student s2,Student s1
- WHERE s1.Sname=s2.Sname
得到的结果就是两个自连接的表一一对应的了:
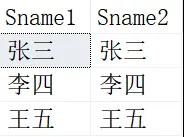
这里的就是自连接的精髓了,张三自己和自己进行了关联,所以你说这是什么连接?
但是我们工作中,使用自连接的目的并不是自己和自己关联,更多的时候是和表里的其他进行组合,像这样:
- SELECT
- s1.Sname AS Sname1,
- s2.Sname AS Sname2
- FROM Student s2,Student s1
- WHERE s1.Sname<>s2.Sname
结果如下:

此外,如果我们想进一步的排除掉重复的数据行,比如张三,李四和李四,张三,我们默认这两行是重复数据(尽管他们顺序不同,但是在数学集合上,这两行可以看作是相同的结果集),只想保留一种的话,可以这样:
- SELECT
- s1.Sname AS Sname1,
- s2.Sname AS Sname2
- FROM Student s2,Student s1
- WHERE s1.Sname>s2.Sname
得到的结果如下:
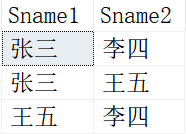
这样我们就得到了“不重复”的3行数据了,这个与数学上的组合是一样的。
上面我们举了一个自连接来处理连续性问题,下面我们再举一个用自连接来删除重复数据的示例:
示例表结构
有如下一张Student表,表结构和数据如下:
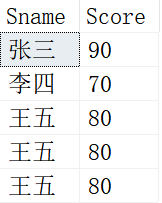
我们想删除表中重复的数据行,该如何写这个SQL?
我们分析一下,发现这个表是没有主键ID的,为了区分它们的话,我需要给它新增一个虚列主键,怎么做?可以这样写:
- SELECT
- IDENTITY(INT) ID,
- Sname,
- Score
- INTO Student_Tmp
- FROM Student
这里我们使用自增长函数IDENTITY()来生成了一个生成一个类似自增主键的ID,并且将结果插入到Student_Tmp,其中Student_Tmp中的具体内容如下:
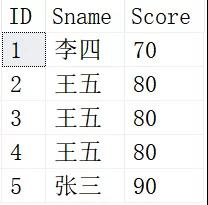
然后,我们可以通过保留最大值或最小值的方式来删除重复项,具体如下:
- DELETE FROM Student_Tmp
- WHERE Student_Tmp.ID< (
- SELECT Max(s2.ID)
- FROM Student_Tmp s2
- WHERE Student_Tmp.Sname=s2.Sname
- AND Student_Tmp.Score=s2.Score
- );
这样我们就可以删除ID为3和4的列了,查询一下Student_Tmp里的内容如下:
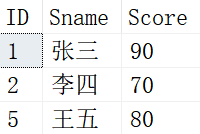
注意:由于SQL Server的一些限制,我们对源表不能进行上述操作,为了给大家演示自连接的作用,做了一定的调整。
如果想在SQL Server中删除原表中的重复行,可以使用如下方法:
- SELECT DISTINCT * INTO Student_Tmp FROM Student
- TRUNCATE TABLE Student
- INSERT INTO Student SELECT * FROM Student_Tmp
- DROP TABLE Student_Tmp
通过上述的办法,我们使用自连接的方式删除了Student_Tmp里面的重复行。
以上就是自连接的一些主要用法,有不明白的地方欢迎给我留言~
责任编辑:武晓燕 来源: SQL数据库开发 SQL自连接数据
(责任编辑:焦点)
桂发祥(002820.SZ)2020年度净利润降70.41% 基本每股收益0.12元
 桂发祥(002820.SZ)发布2020年年度报告,实现营业收入3.49亿元,同比下降31.29%;归属于上市公司股东的净利润2503.71万元,同比下降70.41%;归属于上市公司股东的扣除非经常性
...[详细]
桂发祥(002820.SZ)发布2020年年度报告,实现营业收入3.49亿元,同比下降31.29%;归属于上市公司股东的净利润2503.71万元,同比下降70.41%;归属于上市公司股东的扣除非经常性
...[详细]国家邮政局:中国邮政业务总量逾1.2万亿元 对世界增长贡献率超过50%
 9月17日,国新办举行中国邮政业改革发展成效发布会。国家邮政局局长马军胜在会上介绍,新中国成立70年特别是党的十八大以来,邮政业面貌发生了翻天覆地的变化。邮政体系已经成为国家战略性基础设施和社会组织系
...[详细]
9月17日,国新办举行中国邮政业改革发展成效发布会。国家邮政局局长马军胜在会上介绍,新中国成立70年特别是党的十八大以来,邮政业面貌发生了翻天覆地的变化。邮政体系已经成为国家战略性基础设施和社会组织系
...[详细] 七夕节有哪些消费趋势?广州日报全媒体记者从多个互联网平台获悉,从消费品类来看,一方面,七夕约会就餐越来越注重仪式感和品质感,提前订座等功能被消费者看重,高客单价餐饮品类消费旺盛;另一方面,美容美发美体
...[详细]
七夕节有哪些消费趋势?广州日报全媒体记者从多个互联网平台获悉,从消费品类来看,一方面,七夕约会就餐越来越注重仪式感和品质感,提前订座等功能被消费者看重,高客单价餐饮品类消费旺盛;另一方面,美容美发美体
...[详细]本周公开市场迎1400亿元逆回购到期 “定向降息”操作的空间或逐步打开
 8月份,央行自8月9日起连续开展公开市场操作,直到当月倒数第二个工作日才暂停。8月29日,央行发布公告,临近月末财政支出力度加大,与中央国库现金管理到期、央行逆回购到期等因素对冲后,银行体系流动性总量
...[详细]
8月份,央行自8月9日起连续开展公开市场操作,直到当月倒数第二个工作日才暂停。8月29日,央行发布公告,临近月末财政支出力度加大,与中央国库现金管理到期、央行逆回购到期等因素对冲后,银行体系流动性总量
...[详细] 微粒贷可以为借款人提供无抵押担保的借款服务,在借款成功后会收取一定的利息。有不少人微粒贷利息比较高,想知道有什么方法可以降低利息。这里就给大家介绍几招微粒贷降低利息小技巧,其实就是那么简单。微粒贷降低
...[详细]
微粒贷可以为借款人提供无抵押担保的借款服务,在借款成功后会收取一定的利息。有不少人微粒贷利息比较高,想知道有什么方法可以降低利息。这里就给大家介绍几招微粒贷降低利息小技巧,其实就是那么简单。微粒贷降低
...[详细] 在起始于2017年的光伏中概股私有化浪潮过后,如今美股市场中的光伏中概股已所剩无几。近日,仍然坚守美股的光伏中概股——阿特斯、晶科能源相继发布了2019年二季度财报。根据相关报
...[详细]
在起始于2017年的光伏中概股私有化浪潮过后,如今美股市场中的光伏中概股已所剩无几。近日,仍然坚守美股的光伏中概股——阿特斯、晶科能源相继发布了2019年二季度财报。根据相关报
...[详细]专家呼吁义务教育阶段恢复每周0.5学时健康教育课 达到健康教育的目的
 学校健康教育是基础素质教育的一部分,一直以来,全国绝大多数学校都因地制宜、探索性地开展了多种形式的学校健康教育活动。“举办关于拒绝抽烟、拒绝二手烟的讲座,组织预防近视的班队主题活动,制作营
...[详细]
学校健康教育是基础素质教育的一部分,一直以来,全国绝大多数学校都因地制宜、探索性地开展了多种形式的学校健康教育活动。“举办关于拒绝抽烟、拒绝二手烟的讲座,组织预防近视的班队主题活动,制作营
...[详细]看好中国经济前景 国际指数频频“加仓”A股 A股国际化再进一步
 9月23日,A股迎来两大国际指数调整的重要时间点,A股国际化再进一步。具体来看,9月6日,标普道琼斯指数公司宣布将1099只中国A股正式纳入标普新兴市场全球基准指数,并于9月23日开盘正式生效,首次纳
...[详细]
9月23日,A股迎来两大国际指数调整的重要时间点,A股国际化再进一步。具体来看,9月6日,标普道琼斯指数公司宣布将1099只中国A股正式纳入标普新兴市场全球基准指数,并于9月23日开盘正式生效,首次纳
...[详细]2021年前三季度国内旅游总人次26.89亿 旅游收入2.37万亿元
 11月3日,文旅部发布2021年前三季度国内旅游数据情况。根据国内旅游抽样调查结果,2021年前三季度,国内旅游总人次26.89亿,比上年同期增长39.1%。(恢复到2019年同期的58.5%。)其中
...[详细]
11月3日,文旅部发布2021年前三季度国内旅游数据情况。根据国内旅游抽样调查结果,2021年前三季度,国内旅游总人次26.89亿,比上年同期增长39.1%。(恢复到2019年同期的58.5%。)其中
...[详细] 今年1月初,国务院办公厅下发《关于推广第二批支持创新相关改革举措的通知》(以下简称《通知》),《通知》要求包括陕西西安在内的八个试点城市推广设置科技创新专板,拓宽科技型企业融资渠道,推动各类金融工具更
...[详细]
今年1月初,国务院办公厅下发《关于推广第二批支持创新相关改革举措的通知》(以下简称《通知》),《通知》要求包括陕西西安在内的八个试点城市推广设置科技创新专板,拓宽科技型企业融资渠道,推动各类金融工具更
...[详细] 新三板改革“箭在弦上” 未来要在五大方面力推改革举措
新三板改革“箭在弦上” 未来要在五大方面力推改革举措 中报业绩向好,股价却跌幅过半 小米启动最高120亿港元股份回购
中报业绩向好,股价却跌幅过半 小米启动最高120亿港元股份回购 7月主要指标释放积极信号 延续总体平稳、稳中有进的发展态势
7月主要指标释放积极信号 延续总体平稳、稳中有进的发展态势 合丰集团(02320.HK)发布公告:年度公司拥有人应占亏损1.72亿港元
合丰集团(02320.HK)发布公告:年度公司拥有人应占亏损1.72亿港元