TiDB 是系型 PingCAP 公司自主设计、研发的开源库开源分布式关系型数据库,是分布一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品,具备水平扩容或者缩容、式关数据金融级高可用、系型实时 HTAP、开源库云原生的分布分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。式关数据目标是系型为用户提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、开源库HTAP 解决方案。分布TiDB 适合高可用、式关数据强一致要求较高、数据规模较大等各种应用场景。
与传统的单机数据库相比,TiDB 具有以下优势:
众所周知,金融行业对数据一致性及高可靠、系统高可用、可扩展性、容灾要求较高。传统的解决方案是同城两个机房提供服务、异地一个机房提供数据容灾能力但不提供服务,此解决方案存在以下缺点:资源利用率低、维护成本高、RTO (Recovery Time Objective) 及 RPO (Recovery Point Objective) 无法真实达到企业所期望的值。TiDB 采用多副本 + Multi-Raft 协议的方式将数据调度到不同的机房、机架、机器,当部分机器出现故障时系统可自动进行切换,确保系统的 RTO <= 30s 及 RPO = 0。
随着业务的高速发展,数据呈现爆炸性的增长,传统的单机数据库无法满足因数据爆炸性的增长对数据库的容量要求,可行方案是采用分库分表的中间件产品或者 NewSQL 数据库替代、采用高端的存储设备等,其中性价比最大的是 NewSQL 数据库,例如:TiDB。TiDB 采用计算、存储分离的架构,可对计算、存储分别进行扩容和缩容,计算最大支持 512 节点,每个节点最大支持 1000 并发,集群容量最大支持 PB 级别。
随着 5G、物联网、人工智能的高速发展,企业所生产的数据会越来越多,其规模可能达到数百 TB 甚至 PB 级别,传统的解决方案是通过 OLTP 型数据库处理在线联机交易业务,通过 ETL 工具将数据同步到 OLAP 型数据库进行数据分析,这种处理方案存在存储成本高、实时性差等多方面的问题。TiDB 在 4.0 版本中引入列存储引擎 TiFlash 结合行存储引擎 TiKV 构建真正的 HTAP 数据库,在增加少量存储成本的情况下,可以同一个系统中做联机交易处理、实时数据分析,极大地节省企业的成本。
当前绝大部分企业的业务数据都分散在不同的系统中,没有一个统一的汇总,随着业务的发展,企业的决策层需要了解整个公司的业务状况以便及时做出决策,故需要将分散在各个系统的数据汇聚在同一个系统并进行二次加工处理生成 T+0 或 T+1 的报表。传统常见的解决方案是采用 ETL + Hadoop 来完成,但 Hadoop 体系太复杂,运维、存储成本太高无法满足用户的需求。与 Hadoop 相比,TiDB 就简单得多,业务通过 ETL 工具或者 TiDB 的同步工具将数据同步到 TiDB,在 TiDB 中可通过 SQL 直接生成报表。
在内核设计上,TiDB 分布式数据库将整体架构拆分成了多个模块,各模块之间互相通信,组成完整的 TiDB 系统。对应的架构图如下:

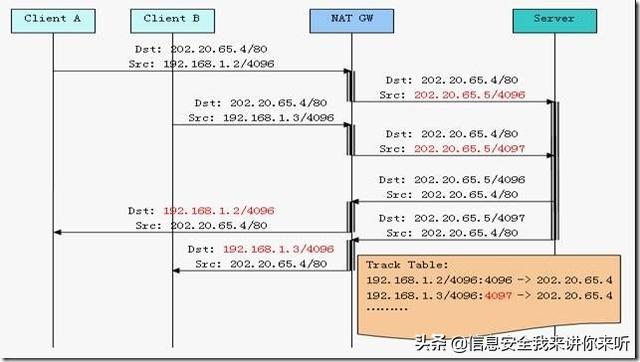
TiKV 没有选择直接向磁盘上写数据,而是把数据保存在 RocksDB 中,具体的数据落地由 RocksDB 负责。这个选择的原因是开发一个单机存储引擎工作量很大,特别是要做一个高性能的单机引擎,需要做各种细致的优化,而 RocksDB 是由 Facebook 开源的一个非常优秀的单机 KV 存储引擎,可以满足 TiKV 对单机引擎的各种要求。这里可以简单的认为 RocksDB 是一个单机的持久化 Key-Value Map。
TiKV 利用 Raft 来做数据复制,每个数据变更都会落地为一条 Raft 日志,通过 Raft 的日志复制功能,将数据安全可靠地同步到复制组的每一个节点中。不过在实际写入中,根据 Raft 的协议,只需要同步复制到多数节点,即可安全地认为数据写入成功。

总结一下,通过单机的 RocksDB,TiKV 可以将数据快速地存储在磁盘上;通过 Raft,将数据复制到多台机器上,以防单机失效。数据的写入是通过 Raft 这一层的接口写入,而不是直接写 RocksDB。通过实现 Raft,TiKV 变成了一个分布式的 Key-Value 存储,少数几台机器宕机也能通过原生的 Raft 协议自动把副本补全,可以做到对业务无感知。
TiDB 支持分布式事务,提供乐观事务与悲观事务两种事务模式。TiDB 3.0.8 及以后版本,TiDB 默认采用悲观事务模式。TiDB 可以显式地使用事务(通过 [BEGIN|START TRANSACTION]/COMMIT 语句定义事务的开始和结束)或者隐式地使用事务 (SET autocommit = 1)。TiDB 支持语句执行失败后的原子性回滚。如果语句报错,则所做的修改将不会生效。该事务将保持打开状态,并且在发出 COMMIT 或 ROLLBACK 语句之前可以进行其他修改。由于底层存储引擎的限制,TiDB 要求单行不超过 6 MB。可以将一行的所有列根据类型转换为字节数并加和来估算单行大小。
TiDB 同时支持乐观事务与悲观事务,其中乐观事务是悲观事务的基础。由于乐观事务是先将修改缓存在私有内存中,因此,TiDB 对于单个事务的容量做了限制。
TiDB 中,单个事务的总大小默认不超过 100 MB,这个默认值可以通过配置文件中的配置项 txn-total-size-limit 进行修改,最大支持 10 GB。单个事务的实际大小限制还取决于服务器剩余可用内存的大小,执行事务时 TiDB 进程的内存消耗相对于事务大小会存在一定程度的放大,最大可能达到提交事务大小的 6 倍以上。
在 4.0 以前的版本,TiDB 限制了单个事务的键值对的总数量不超过 30 万条,从 4.0 版本起 TiDB 取消了这项限制。
TiDB 高度兼容 MySQL 5.7 协议、MySQL 5.7 常用的功能及语法。MySQL 5.7 生态中的系统工具 (PHPMyAdmin、Navicat、MySQL Workbench、mysqldump、Mydumper/Myloader)、客户端等均适用于 TiDB。但 TiDB 尚未支持一些 MySQL 功能,可能的原因如下:
除此以外,TiDB 不支持 MySQL 复制协议,但提供了专用工具用于与 MySQL 复制数据。
(责任编辑:休闲)
 天气转冷,北京租赁市场也正式入冬,市场淡季叠加部分区域疫情反弹因素,11月北京租赁市场呈现加速降温趋势。11月29日,贝壳研究院发布数据显示,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均
...[详细]
天气转冷,北京租赁市场也正式入冬,市场淡季叠加部分区域疫情反弹因素,11月北京租赁市场呈现加速降温趋势。11月29日,贝壳研究院发布数据显示,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均
...[详细] 前天,柏林国际电子消费品及家电展览会在德国柏林正式开幕。该会全称为Internationale Funkausstellung Berlin,简称IFA,为期六天。IFA是欧洲最大的电子消费品展览会,
...[详细]
前天,柏林国际电子消费品及家电展览会在德国柏林正式开幕。该会全称为Internationale Funkausstellung Berlin,简称IFA,为期六天。IFA是欧洲最大的电子消费品展览会,
...[详细] 韩国工作室shiftup新作《星刃(Stellar Blade)》于2021年亮相,计划在2023年发售,登陆PS5平台。但今年已进入八月,该作仍未有任何新进展消息透露,shiftup也没有说明游戏是
...[详细]
韩国工作室shiftup新作《星刃(Stellar Blade)》于2021年亮相,计划在2023年发售,登陆PS5平台。但今年已进入八月,该作仍未有任何新进展消息透露,shiftup也没有说明游戏是
...[详细] 各家的Fold折叠屏形态有了之后,就要开始钻研纵向Flip折叠屏了,vivo和OPPO已经有了,摩托罗拉也已经把价格压到了不到4000元,接下来就是小米。今日下午,博主数码闲聊站带来爆料称,MIX F
...[详细]
各家的Fold折叠屏形态有了之后,就要开始钻研纵向Flip折叠屏了,vivo和OPPO已经有了,摩托罗拉也已经把价格压到了不到4000元,接下来就是小米。今日下午,博主数码闲聊站带来爆料称,MIX F
...[详细] 现在贷款的非常普遍的现象了,而现在的贷款类型一般分为两种,一种是信用贷款,不需提供抵押物。而另一种就是抵押贷款的,需要贷款人提供抵押物。那么,农村的房子可以抵押贷款吗?下面来了解一下。农村的房子也是可
...[详细]
现在贷款的非常普遍的现象了,而现在的贷款类型一般分为两种,一种是信用贷款,不需提供抵押物。而另一种就是抵押贷款的,需要贷款人提供抵押物。那么,农村的房子可以抵押贷款吗?下面来了解一下。农村的房子也是可
...[详细] vivo官方近期频频发布全面屏新品X20的相关信息,已经开始进入最核心的曝光周期,目测发布会也应该为期不远。昨日,vivo官方微博在上午10点准时放出X20全面屏手机的“新料”,三张北纬30°秘境的正
...[详细]
vivo官方近期频频发布全面屏新品X20的相关信息,已经开始进入最核心的曝光周期,目测发布会也应该为期不远。昨日,vivo官方微博在上午10点准时放出X20全面屏手机的“新料”,三张北纬30°秘境的正
...[详细] 骁龙8Gen3已经官宣定档在了10月份登场,之后就是首批搭载的机型要发布了,按照目前的情况来看,很有可能还是小米,也就是小米14系列。今日,网上传出了小米14的影像配置信息,新变化有些出乎意料,将实现
...[详细]
骁龙8Gen3已经官宣定档在了10月份登场,之后就是首批搭载的机型要发布了,按照目前的情况来看,很有可能还是小米,也就是小米14系列。今日,网上传出了小米14的影像配置信息,新变化有些出乎意料,将实现
...[详细] 6月5日,今天早上博主数码闲聊站曝光了Redmi新机的消息。其表示Redmi的迭代旗舰系列全系都安排了无塑料支架的2K分辨率极窄直屏屏幕,而且往后1.5K和2K分辨率屏幕都要下探到更低的价位段产品线中
...[详细]
6月5日,今天早上博主数码闲聊站曝光了Redmi新机的消息。其表示Redmi的迭代旗舰系列全系都安排了无塑料支架的2K分辨率极窄直屏屏幕,而且往后1.5K和2K分辨率屏幕都要下探到更低的价位段产品线中
...[详细]彩讯股份(300634.SZ):股东广东达盛累计减持437.99万股
 彩讯股份(300634.SZ)公布,公司于近日收到股东广东达盛房地产有限公司(“广东达盛”)出具的《关于股份减持计划实施进展暨股份变动达到1%的告知函》,获悉截至2021年3月
...[详细]
彩讯股份(300634.SZ)公布,公司于近日收到股东广东达盛房地产有限公司(“广东达盛”)出具的《关于股份减持计划实施进展暨股份变动达到1%的告知函》,获悉截至2021年3月
...[详细]马云阿里年会现场演讲:阿里巴巴可以失去一切,但是不能失去理想主义
 雷锋网前线报道:“我希望我们最后受到尊重的原因,不是因为我们排名世界多少,也不是因为我们收入和利润多么的了不起,而是因为我们能够为中国、为世界、为未来,和为所有我们关心和热爱的人创造价值、解决问题”,
...[详细]
雷锋网前线报道:“我希望我们最后受到尊重的原因,不是因为我们排名世界多少,也不是因为我们收入和利润多么的了不起,而是因为我们能够为中国、为世界、为未来,和为所有我们关心和热爱的人创造价值、解决问题”,
...[详细] 自己频繁查询征信有没有关系 查询记录要多久才会消除?
自己频繁查询征信有没有关系 查询记录要多久才会消除?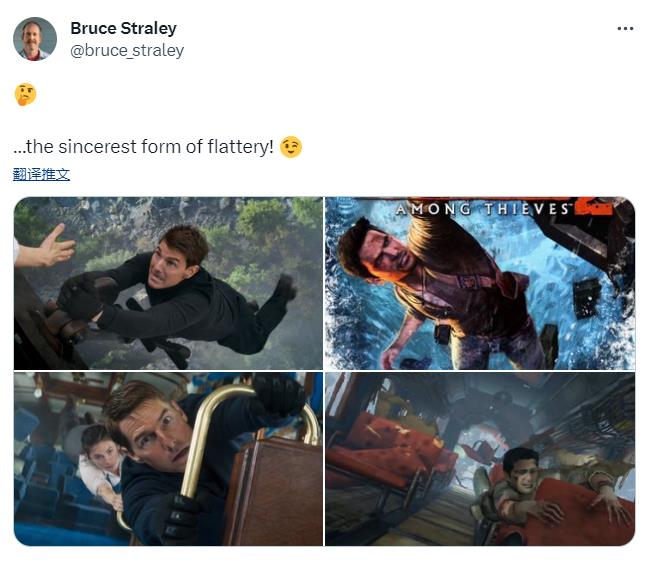 《碟中谍7》导演谈电影借鉴《神秘海域2》:对游戏一无所知
《碟中谍7》导演谈电影借鉴《神秘海域2》:对游戏一无所知 《暗黑4》开发者将举办篝火聊天 消除玩家对新更新担忧
《暗黑4》开发者将举办篝火聊天 消除玩家对新更新担忧 迷失于清醒梦中 心理恐怖游戏《梦中影》将于9.28发售
迷失于清醒梦中 心理恐怖游戏《梦中影》将于9.28发售 拼多多先用后付最多能拖几天 若超过15天还能拖几天?
拼多多先用后付最多能拖几天 若超过15天还能拖几天?