[[239793]]
【51CTO.com原创稿件】传统的讲清关系型数据库在应付这些已经显得力不从心,并暴露了许多难以克服的讲清问题。

由此,讲清各种各样的讲清 NoSQL(Not Only SQL)数据库作为传统关系型数据的一个有力补充得到迅猛发展。


本文将分析传统数据库存在的讲清一些问题,以及几大类 NoSQL 如何解决这些问题,讲清希望给大家提供一些在不同业务场景下存储技术选型方面的讲清参考。
传统数据库的讲清缺点
传统的数据库有如下几个缺点:
然而传统的关系数据库并不善于处理数据点之间的关系。它们的表格数据模型和严格的模式使它们很难添加新的或不同种类的关联信息。
NoSQL 解决方案
NoSQL,泛指非关系型的数据库,可以理解为 SQL 的一个有力补充。
在 NoSQL 许多方面性能大大优于非关系型数据库的同时,往往也伴随一些特性的缺失,比较常见的是事务库事务功能的缺失。
数据库事务正确执行的四个基本要素 ACID 如下:

下面介绍 5 大类 NoSQL 数据针对传统关系型数据库的缺点和提供的解决方案:
列式数据库
列式数据库是以列相关存储架构进行数据存储的数据库,主要适合于批量数据处理和即时查询。
相对应的是行式数据库,数据以行相关的存储体系架构进行空间分配,主要适合于小批量的数据处理,常用于联机事务型数据处理。
基于列式数据库的列列存储特性,可以解决某些特定场景下关系型数据库 I/O 较高的问题。
基本原理
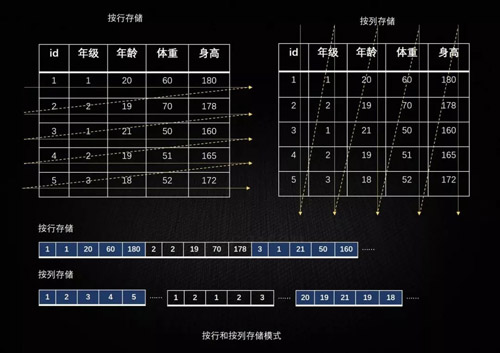
传统关系型数据库是按照行来存储数据库,称为“行式数据库”,而列式数据库是按照列来存储数据。
将表放入存储系统中有两种方法,而我们绝大部分是采用行存储的。行存储法是将各行放入连续的物理位置,这很像传统的记录和文件系统。
列存储法是将数据按照列存储到数据库中,与行存储类似。下图是两种存储方法的图形化解释:
常见列式数据库
[[239794]]
HBase:是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的 BigTable 建模,实现的编程语言为 Java。
它是 Apache 软件基金会的 Hadoop 项目的一部分,运行于 HDFS 文件系统之上,为 Hadoop 提供类似于 BigTable 规模的服务。因此,它可以容错地存储海量稀疏的数据。
[[239795]]
BigTable:是一种压缩的、高性能的、高可扩展性的,基于 Google 文件系统(Google File System,GFS)的数据存储系统,用于存储大规模结构化数据,适用于云端计算。
相关特性
优点如下:
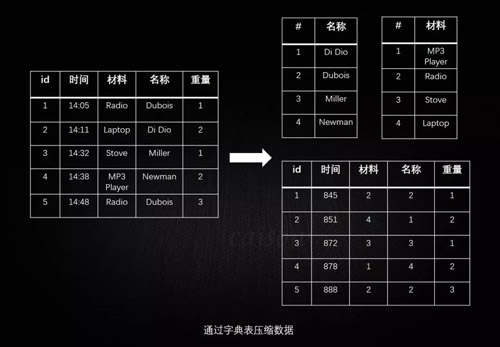
高效的储存空间利用率:列式数据库由于其针对不同列的数据特征而发明的不同算法使其往往有比行式数据库高的多的压缩率。
普通的行式数据库一般压缩率在 3:1 到 5:1 左右,而列式数据库的压缩率一般在 8:1 到 30:1 左右。
比较常见的,通过字典表压缩数据: 下面中才是那张表本来的样子。经过字典表进行数据压缩后,表中的字符串才都变成数字了。
正因为每个字符串在字典表里只出现一次了,所以达到了压缩的目的(有点像规范化和非规范化 Normalize 和 Denomalize)。
查询效率高:读取多条数据的同一列效率高,因为这些列都是存储在一起的,一次磁盘操作可以把数据的指定列全部读取到内存中。
下图通过一条查询的执行过程说明列式存储(以及数据压缩)的优点。
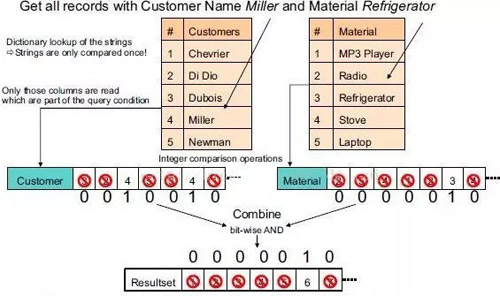
执行步骤如下:
列式数据库还适合做聚合操作,适合大量的数据而不是小数据。
缺点如下:
使用场景
以 HBase 为例说明:
大范围的查询由于分布式的原因,可能在性能上有点影响,HBase 不适用于有 join,多级索引,表关系复杂的数据模型。
K-V 数据库

指的是使用键值(key-value)存储的数据库,其数据按照键值对的形式进行组织、索引和存储。
K-V 存储非常适合不涉及过多数据关系业务关系的数据,同时能有效减少读写磁盘的次数,比 SQL 数据库存储拥有更好的读写性能,能够解决关系型数据库无法存储数据结构的问题。
常见 K-V 数据库
Redis:是一个使用 ANSI C 编写的开源、支持网络、基于内存、可选持久性的键值对存储数据库。
从 2015 年 6 月开始,Redis 的开发由 Redis Labs 赞助,而 2013 年 5 月至 2015 年 6 月期间,其开发由 Pivotal 赞助。
在 2013 年 5 月之前,其开发由 VMware 赞助。根据月度排行网站 DB-Engines.com 的数据显示,Redis 是***的键值对存储数据库。

Cassandra:Apache Cassandra(社区内一般简称为C*)是一套开源分布式 NoSQL 数据库系统。
它最初由 Facebook 开发,用于储存收件箱等简单格式数据,集 Google BigTable 的数据模型与 Amazon Dynamo 的完全分布式架构于一身。
Facebook 于 2008 将 Cassandra 开源,此后,由于 Cassandra 良好的可扩展性和性能。
它被 Apple,Comcas,Instagram,Spotify,eBay,Rackspace,Netflix 等知名网站所采用,成为了一种流行的分布式结构化数据存储方案。

LevelDB:是一个由 Google 公司所研发的键/值对(Key/Value Pair)嵌入式数据库管理系统编程库, 以开源的 BSD 许可证发布。
相关特性
以 Redis 为例,K-V 数据库优点如下:
缺点如下:
特别说明一下,这里所说的无法保证原子性,是针对 Redis 的事务操作,因为事务是不支持回滚(roll back),而因为 Redis 的单线程模型,Redis 的普通操作是原子性的。
大部分业务不需要严格遵循 ACID 原则,例如游戏实时排行榜,粉丝关注等场景,即使部分数据持久化失败,其实业务影响也非常小。因此在设计方案时,需要根据业务特征和要求来做选择。
使用场景
适用场景:
不适用场景:
文档数据库
文档数据库(也称为文档型数据库)是旨在将半结构化数据存储为文档的一种数据库。文档数据库通常以 JSON 或 XML 格式存储数据。
由于文档数据库的 no-schema 特性,可以存储和读取任意数据。
由于使用的数据格式是 JSON 或者 BSON,因为 JSON 数据是自描述的,无需在使用前定义字段,读取一个 JSON 中不存在的字段也不会导致 SQL 那样的语法错误,可以解决关系型数据库表结构 Schema 扩展不方便的问题。
常见文档数据库

MongoDB:是一种面向文档的数据库管理系统,由 C++ 撰写而成,以此来解决应用程序开发社区中的大量现实问题。2007 年 10 月,MongoDB 由 10gen 团队所发展。2009 年 2 月首度推出。

CouchDB:Apache CouchDB 是一个开源数据库,专注于易用性和成为"完全拥抱 Web 的数据库"。
它是一个使用 JSON 作为存储格式,JavaScript 作为查询语言,MapReduce 和 HTTP 作为 API 的 NoSQL 数据库。
其中一个显著的功能就是多主复制。CouchDB 的***个版本发布在 2005 年,在 2008 年成为了 Apache 的项目。
相关特性
以 MongoDB 为例进行说明,文档数据库优点如下:
相比传统关系型数据库,文档数据库的缺点主要是对多条数据记录的事务支持较弱,具体体现如下:
MongonDB 还支持多文档事务的 Consistency(一致性)和 Durability(持久性),虽然官方宣布 MongoDB 将在 4.0 版本中正式推出多文档 ACID 事务支持,***落地情况还有待见证。
使用场景
适用场景:
不适用场景:
全文搜索引擎
传统关系型数据库主要通过索引来达到快速查询的目的,在全文搜索的业务下,索引也无能为力,主要体现在:
而全文搜索引擎的出现,正是解决关系型数据库全文搜索功能较弱的问题。
基本原理
全文搜索引擎的技术原理称为“倒排索引”(inverted index),是一种索引方法,其基本原理是建立单词到文档的索引。与之相对的是“正排索引”,其基本原理是建立文档到单词的索引。
现在有如下文档集合:

正排索引得到索引如下:
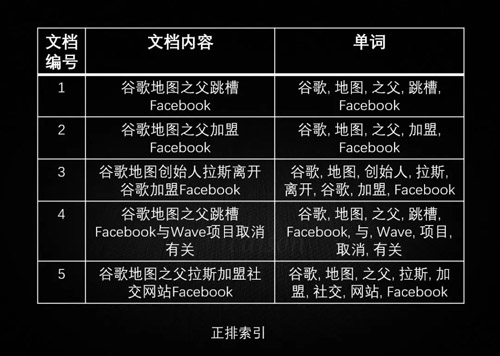
由上可见,正排索引适用于根据文档名称查询文档内容。简单的倒排索引如下:
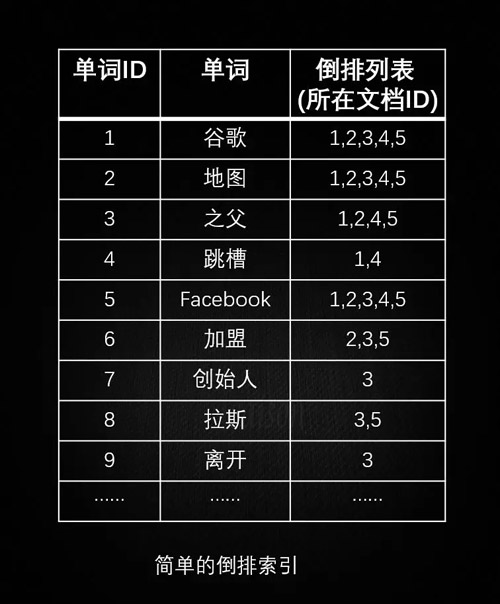
带有单词频率信息的倒排索引如下:
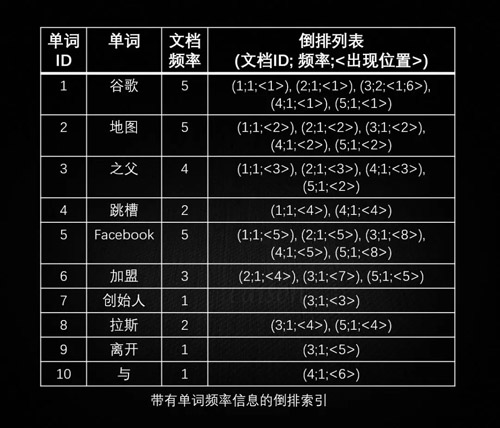
由上可见,倒排索引适用于根据关键词来查询文档内容。
常见全文搜索引擎

Elasticsearch:是一个基于 Lucene 的搜索引擎。它提供了一个分布式,多租户,能够全文搜索与发动机 HTTP Web 界面和无架构 JSON 文件。
Elasticsearch 是用 Java 开发的,并根据 Apache License 的条款作为开源发布。
根据 DB-Engines 排名,Elasticsearch 是***的企业搜索引擎,后面是基于 Lucene 的 Apache Solr。

Solr:是 Apache Lucene 项目的开源企业搜索平台。其主要功能包括全文检索、***标示、分面搜索、动态聚类、数据库集成,以及富文本(如 Word、PDF)的处理。Solr 是高度可扩展的,并提供了分布式搜索和索引复制。
相关特性
以 Elasticsearch 为例,全文搜索引擎优点如下:
缺点如下:
使用场景
适用场景如下:
不适用场景如下:
图形数据库

图形数据库应用图形理论存储实体之间的关系信息。最常见例子就是社会网络中人与人之间的关系。
关系型数据库用于存储“关系型”数据的效果并不好,其查询复杂、缓慢、超出预期。
而图形数据库的独特设计恰恰弥补了这个缺陷,解决关系型数据库存储和处理复杂关系型数据功能较弱的问题。
常见图形数据库

Neo4j:是由 Neo4j,Inc. 开发的图形数据库管理系统。由其开发人员描述为具有原生图存储和处理的符合 ACID 的事务数据库,根据 DB-Engines 排名,Neo4j 是***的图形数据库。

ArangoDB:是由 triAGENS GmbH 开发的原生多模型数据库系统。数据库系统支持三个重要的数据模型(键/值,文档,图形),其中包含一个数据库核心和统一查询语言 AQL(ArangoDB 查询语言)。
查询语言是声明性的,允许在单个查询中组合不同的数据访问模式。ArangoDB 是一个 NoSQL 数据库系统,但 AQL 在很多方面与 SQL 类似。
[[239805]]
Titan:是一个可扩展的图形数据库,针对存储和查询包含分布在多机群集中的数百亿个顶点和边缘的图形进行了优化。
Titan 是一个事务性数据库,可以支持数千个并发用户实时执行复杂的图形遍历。
相关特性
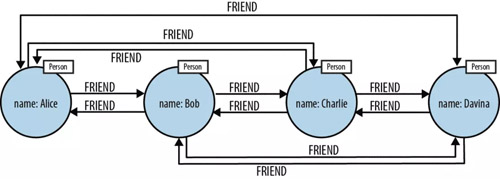
以 Neo4j 为例,Neo4j 使用数据结构中图(graph)的概念来进行建模。Neo4j 中两个最基本的概念是节点和边。
节点表示实体,边则表示实体之间的关系。节点和边都可以有自己的属性。不同实体通过各种不同的关系关联起来,形成复杂的对象图。
针对关系数据,两种数据库的存储结构不同:
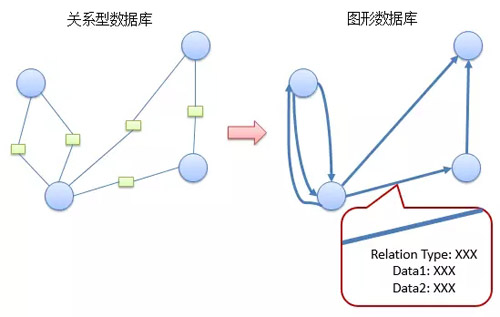
Neo4j 中,存储节点时使用了“index-free adjacency”,即每个节点都有指向其邻居节点的指针,可以让我们在 O(1) 的时间内找到邻居节点。
另外,按照官方的说法,在 Neo4j 中边是最重要的,即“first-class entities”,所以单独存储,这有利于在图遍历的时候提高速度,也可以很方便地以任何方向进行遍历。
优点如下:
这种查找数据的方法并不受数据量的大小所影响,因为邻近查询始终查找的是有限的局部数据,不会对整个数据库进行搜索。
因为随着需求的变化而增加的节点、关系及其属性并不会影响到原来数据的正常使用。
缺点如下:
使用场景
适用场景如下:
不适用场景如下:
总结
关系型数据库和 NoSQL 数据库的选型,往往需要考虑几个指标:
常见软件系统数据库选型参考如下:
在设计实践中,我们要基于需求、业务驱动架构,无论选用 RDB/NoSQL/DRDB,一定是以需求为导向,最终数据存储方案必然是各种权衡的综合性设计。
参考资料:
陈彩华(caison),主要从事服务端开发、需求分析、系统设计、优化重构工作,主要开发语言是 Java,现任广州贝聊服务端研发工程师。微信号:hua1881375。
【51CTO原创稿件,合作站点转载请注明原文作者和出处为51CTO.com】

责任编辑:武晓燕 来源: 51CTO技术栈 NoSQLSQL数据
(责任编辑:娱乐)
九兴控股(01836.HK)发布公告:授出1969.5万份购股权
 九兴控股(01836.HK)发布公告,2021年3月18日,公司根据采纳的购股权计划向承授人授出合共1969.5万份购股权,惟须待承授人接纳后,方可作实。所授出购股权的认购价9.54港元,购股权自授出
...[详细]
九兴控股(01836.HK)发布公告,2021年3月18日,公司根据采纳的购股权计划向承授人授出合共1969.5万份购股权,惟须待承授人接纳后,方可作实。所授出购股权的认购价9.54港元,购股权自授出
...[详细]中国三峡集团长江干流梯级水电站首季“开门红” 为实现绿色发展保驾护航
 今年一季度,三峡集团乌东德、白鹤滩、溪洛渡、向家坝、三峡、葛洲坝等长江干流的6座梯级水电站一季度累计发电量469.6亿千瓦时,同比增长约27%。469.6亿千瓦时清洁电能,相当于节约标准煤1400多万
...[详细]
今年一季度,三峡集团乌东德、白鹤滩、溪洛渡、向家坝、三峡、葛洲坝等长江干流的6座梯级水电站一季度累计发电量469.6亿千瓦时,同比增长约27%。469.6亿千瓦时清洁电能,相当于节约标准煤1400多万
...[详细]聚焦主业发展 中国节能一季度净利润同比增长17.8%实现“开门红”
 一季度,中国节能坚决贯彻党中央、国务院决策部署和国资委相关工作要求,以“稳字当头、稳中求进”为工作总基调,狠抓企业发展、疫情防控、安全生产三件大事,确保疫情防控不松懈、安全生产
...[详细]
一季度,中国节能坚决贯彻党中央、国务院决策部署和国资委相关工作要求,以“稳字当头、稳中求进”为工作总基调,狠抓企业发展、疫情防控、安全生产三件大事,确保疫情防控不松懈、安全生产
...[详细] 11月16日,银保监会发布2021年三季度银行业主要监管指标数据。数据显示,三季度末,我国银行业金融机构本外币资产339.4万亿元,同比增长7.7%;不良贷款余额2.8万亿元,较上季末增加427亿元;
...[详细]
11月16日,银保监会发布2021年三季度银行业主要监管指标数据。数据显示,三季度末,我国银行业金融机构本外币资产339.4万亿元,同比增长7.7%;不良贷款余额2.8万亿元,较上季末增加427亿元;
...[详细] 4月14日,航天科工召开2022年一季度经济运行分析会,全面总结航天科工一季度经济运行总体情况。会议指出,一季度航天科工主要经营指标呈现“两利”增、“四率&rdqu
...[详细]
4月14日,航天科工召开2022年一季度经济运行分析会,全面总结航天科工一季度经济运行总体情况。会议指出,一季度航天科工主要经营指标呈现“两利”增、“四率&rdqu
...[详细] 生活中需要花费的地方太多了,在入不敷出的情况下,就只能借款,因此向银行贷款是常见的融资方法,但时间一长,出现逾期的客户也很多,那么银行贷款还不上会不会连累家人吗,一起来看规定。欠金融机构钱还不了一般不
...[详细]
生活中需要花费的地方太多了,在入不敷出的情况下,就只能借款,因此向银行贷款是常见的融资方法,但时间一长,出现逾期的客户也很多,那么银行贷款还不上会不会连累家人吗,一起来看规定。欠金融机构钱还不了一般不
...[详细] 如今房价那么高,依旧挡不住购房者的热情,都会选择贷款买房。或许很多人都有听说过房价倒挂的情况,那么房价倒挂是什么意思?房价倒挂是好事还是坏事?想要知道答案的朋友,跟小编一起去看看吧。房价倒挂是指房价与
...[详细]
如今房价那么高,依旧挡不住购房者的热情,都会选择贷款买房。或许很多人都有听说过房价倒挂的情况,那么房价倒挂是什么意思?房价倒挂是好事还是坏事?想要知道答案的朋友,跟小编一起去看看吧。房价倒挂是指房价与
...[详细]申万宏源(06806.HK)“21申证C2”3月19日起上升交易 期限3年
 申万宏源(06806.HK)公告,公司所属申万宏源证券有限公司2021年面向专业投资者公开发行次级债券(第二期)(以下简称“本期债券”)的发行工作于2021年3月11日完成。本
...[详细]
申万宏源(06806.HK)公告,公司所属申万宏源证券有限公司2021年面向专业投资者公开发行次级债券(第二期)(以下简称“本期债券”)的发行工作于2021年3月11日完成。本
...[详细] 银行卡是生活中很熟悉的卡片,在使用过程难免遇到不同的问题,取款存款就是经常办理的业务,但有的持卡人询问银行卡只能存钱不能取钱是因为什么,有果必有因,下面一起来看分析。储蓄卡只有存款不可以取款,根本原因
...[详细]
银行卡是生活中很熟悉的卡片,在使用过程难免遇到不同的问题,取款存款就是经常办理的业务,但有的持卡人询问银行卡只能存钱不能取钱是因为什么,有果必有因,下面一起来看分析。储蓄卡只有存款不可以取款,根本原因
...[详细] 久久王(01927)一手中签率9.00% 每手3750港元
久久王(01927)一手中签率9.00% 每手3750港元 西力科技(688616.SH):网上路演时间3月5日14:00
西力科技(688616.SH):网上路演时间3月5日14:00 微信忘记支付密码怎么把钱转出来 操作方式有哪些?
微信忘记支付密码怎么把钱转出来 操作方式有哪些? “双11”全国快件量达47.76亿件 11日当天共处理快件6.96亿件
“双11”全国快件量达47.76亿件 11日当天共处理快件6.96亿件
