本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,图会通义转载请联系出处。识物商用
阿里开源大模型,基于又上新了~
继通义千问-7B(Qwen-7B)之后,千问阿里云又推出了大规模视觉语言模型Qwen-VL,阿里并且一上线就直接开源。大模B打


具体来说,型又Qwen-VL是开源基于通义千问-7B打造的多模态大模型,支持图像、图会通义文本、识物商用检测框等多种输入,基于并且在文本之外,也支持检测框的输出。
举个🌰,我们输入一张阿尼亚的图片,通过问答的形式,Qwen-VL-Chat既能概括图片内容,也能定位到图片中的阿尼亚。

测试任务中,Qwen-VL展现出了“六边形战士”的实力,在四大类多模态任务的标准英文测评中(Zero-shot Caption/VQA/DocVQA/Grounding)上,都取得了SOTA。

开源消息一出,就引发了不少关注。


具体表现如何,咱们一起来看看~
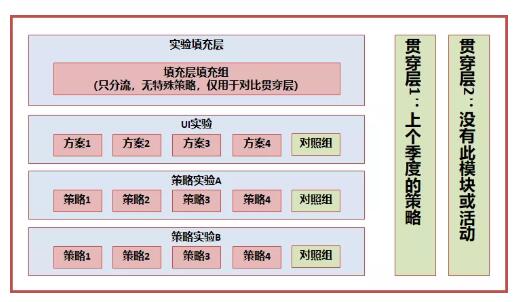
先来整体看一下Qwen-VL系列模型的特点:
按场景来说,Qwen-VL可以用于知识问答、图像问答、文档问答、细粒度视觉定位等场景。
比如,有一位看不懂中文的外国友人去医院看病,对着导览图一个头两个大,不知道怎么去往对应科室,就可以直接把图和问题丢给Qwen-VL,让它根据图片信息担当翻译。

再来测试一下多图输入和比较:
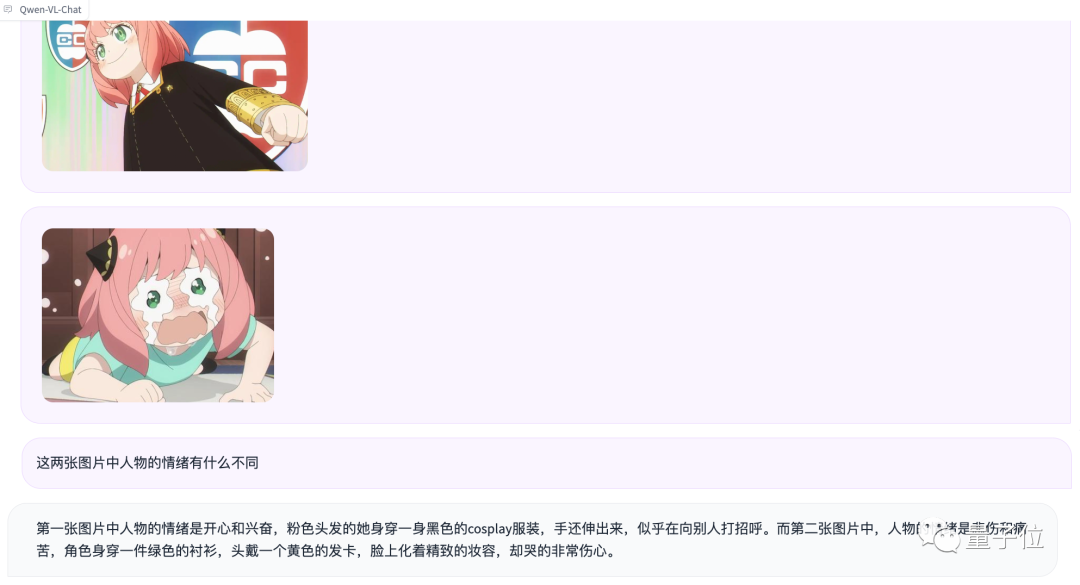
虽然没认出来阿尼亚,不过情绪判断确实挺准确的(手动狗头)。
视觉定位能力方面,即使图片非常复杂人物繁多,Qwen-VL也能精准地根据要求找出绿巨人和蜘蛛侠。

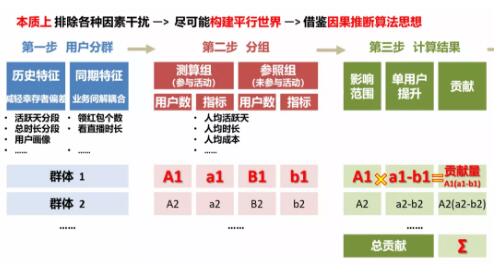
技术细节上,Qwen-VL是以Qwen-7B为基座语言模型,在模型架构上引入了视觉编码器ViT,并通过位置感知的视觉语言适配器连接二者,使得模型支持视觉信号输入。

具体的训练过程分为三步:
研究人员在四大类多模态任务(Zero-shot Caption/VQA/DocVQA/Grounding)的标准英文测评中测试了Qwen-VL。

结果显示,Qwen-VL取得了同等尺寸开源LVLM的最好效果。
另外,研究人员构建了一套基于GPT-4打分机制的测试集TouchStone。


在这一对比测试中,Qwen-VL-Chat取得了SOTA。
如果你对Qwen-VL感兴趣,现在在魔搭社区和huggingface上都有demo可以直接试玩,链接文末奉上~
Qwen-VL支持研究人员和开发者进行二次开发,也允许商用,不过需要注意的是,商用的话需要先填写问卷申请。
项目链接:https://modelscope.cn/models/qwen/Qwen-VL/summary
https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary
https://huggingface.co/Qwen/Qwen-VL
https://huggingface.co/Qwen/Qwen-VL-Chat
https://github.com/QwenLM/Qwen-VL
论文地址:https://arxiv.org/abs/2308.12966
责任编辑:张燕妮 来源: 量子位 模型开源(责任编辑:热点)
北交所开市在即!11月13日进行通关测试 首批星宿股达81家
 自官宣设立北京证券交易所(以下简称“北交所”)后,各项筹备工作紧锣密鼓,相关工作亦衔枚疾进。11月11日,北交所在官网发布通知表示,将于11月13日开展开市通关测试。伴随北交所
...[详细]
自官宣设立北京证券交易所(以下简称“北交所”)后,各项筹备工作紧锣密鼓,相关工作亦衔枚疾进。11月11日,北交所在官网发布通知表示,将于11月13日开展开市通关测试。伴随北交所
...[详细]每日产品辣评:华仔代言的金品质立天下,这次请来了Beyond
 大多数人对于金立手机的印象还停留在刘德华代言的功能机时代:金品质、立天下。来看今天入选雷锋产品库的额热门产品和精彩评论金立M5 Plus——聊上三天三夜12月21日晚,金立智能手机发布全新M5 Plu
...[详细]
大多数人对于金立手机的印象还停留在刘德华代言的功能机时代:金品质、立天下。来看今天入选雷锋产品库的额热门产品和精彩评论金立M5 Plus——聊上三天三夜12月21日晚,金立智能手机发布全新M5 Plu
...[详细] 《星球大战:异等小队》首席编剧 Jenifer Corbett 在 2023 年星球大战庆典上宣布,99号克隆小队将会在明年最后一次回归。她说道:“故事还没有结束……异等小队将在第三季也是最后一季中回
...[详细]
《星球大战:异等小队》首席编剧 Jenifer Corbett 在 2023 年星球大战庆典上宣布,99号克隆小队将会在明年最后一次回归。她说道:“故事还没有结束……异等小队将在第三季也是最后一季中回
...[详细] 最近,Arken Studios在致力于展示即将发售的开放世界射击游戏《红霞岛》,预告展示了游戏中可玩的角色,并让玩家对游戏大致进行了解。尽管该作很多方面受到的评价是积极的,但开发商最近透漏的新细节可
...[详细]
最近,Arken Studios在致力于展示即将发售的开放世界射击游戏《红霞岛》,预告展示了游戏中可玩的角色,并让玩家对游戏大致进行了解。尽管该作很多方面受到的评价是积极的,但开发商最近透漏的新细节可
...[详细]荣盛发展大股东质押公司7599万股股份 占公司总股本比例的1.75%
 日前,荣盛发展发布公告称,其股东荣盛建设工程有限公司所持有的荣盛发展部分股份被质押,本次质押股份约为7599万股,占其所持股份比例的12.66%,占公司总股本比例的1.75%。对于筹集资金用途,荣盛建
...[详细]
日前,荣盛发展发布公告称,其股东荣盛建设工程有限公司所持有的荣盛发展部分股份被质押,本次质押股份约为7599万股,占其所持股份比例的12.66%,占公司总股本比例的1.75%。对于筹集资金用途,荣盛建
...[详细] 小米12系列已在国内发售一段时间,共包含小米12X、小米12、小米12 Pro三款,同时即将面向海外市场发售。3月16日消息,据外媒报道,小米12系列除了上述三款,还将面向海外市场推出一款小米12 L
...[详细]
小米12系列已在国内发售一段时间,共包含小米12X、小米12、小米12 Pro三款,同时即将面向海外市场发售。3月16日消息,据外媒报道,小米12系列除了上述三款,还将面向海外市场推出一款小米12 L
...[详细] 马上就是新年,相信大家都在头疼送什么礼物给自己的妹纸,才能讨得妹纸欢心,又能让妹纸记住?其实手机是个不错的选择,已经成为必需品的手机,可以让妹纸每次使用都能想起你;在价格上又有一定分量,不会显得很lo
...[详细]
马上就是新年,相信大家都在头疼送什么礼物给自己的妹纸,才能讨得妹纸欢心,又能让妹纸记住?其实手机是个不错的选择,已经成为必需品的手机,可以让妹纸每次使用都能想起你;在价格上又有一定分量,不会显得很lo
...[详细] 从HTC One M7时代开始固执地四下巴设计,在新机One X9上终于消失了,有人说HTC终于听到了消费者的声音,然而用户真的可能会为消失的四下巴买单吗?还是重新Get到一个新的槽点?来看今天入选雷
...[详细]
从HTC One M7时代开始固执地四下巴设计,在新机One X9上终于消失了,有人说HTC终于听到了消费者的声音,然而用户真的可能会为消失的四下巴买单吗?还是重新Get到一个新的槽点?来看今天入选雷
...[详细]大别山革命老区正式迎来“高铁时代” 黄黄高铁正线全长126.85公里
 4月22日,由中国铁建所属铁四院设计的黄黄高铁开通运营,大别山革命老区正式迎来“高铁时代”。黄黄高铁是《国家中长期铁路网规划》中“八纵八横”之一的京港通
...[详细]
4月22日,由中国铁建所属铁四院设计的黄黄高铁开通运营,大别山革命老区正式迎来“高铁时代”。黄黄高铁是《国家中长期铁路网规划》中“八纵八横”之一的京港通
...[详细]航海塔防游戏《BUCCANYAR》Steam页面上线 4月20日发售
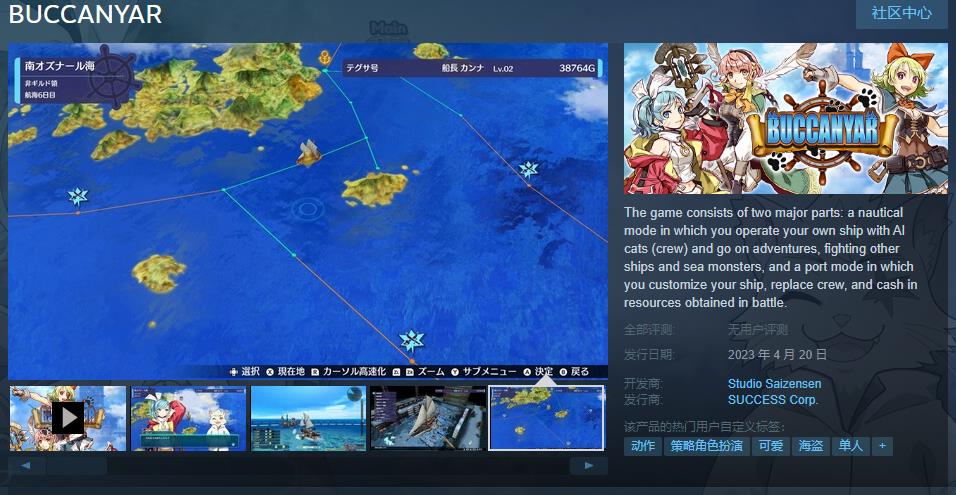 今日4月13日),Success旗下航海塔防型即时战略游戏《BUCCANYAR》Steam页面上线,本作预计于4月20日发售,本作还将登陆Switch与PS4平台,支持简体中文,感兴趣的可以点击此处进
...[详细]
今日4月13日),Success旗下航海塔防型即时战略游戏《BUCCANYAR》Steam页面上线,本作预计于4月20日发售,本作还将登陆Switch与PS4平台,支持简体中文,感兴趣的可以点击此处进
...[详细] 国科微(300672.SZ):股东陈岗解除质押245万股 占其所持股份比例22.32%
国科微(300672.SZ):股东陈岗解除质押245万股 占其所持股份比例22.32% 《异形:火力精英》将于4月26日推出Switch云版本
《异形:火力精英》将于4月26日推出Switch云版本 腾讯发布全新智能驾驶安全硬件“腾讯神眼”
腾讯发布全新智能驾驶安全硬件“腾讯神眼”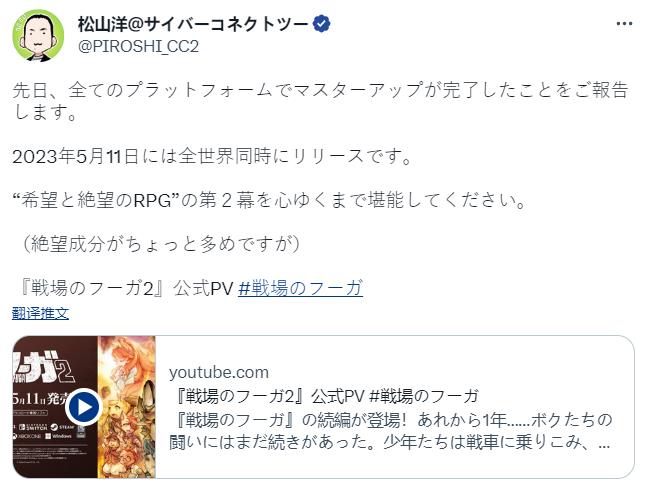 《战场赋格曲2》全平台开发完成 5月11日发售
《战场赋格曲2》全平台开发完成 5月11日发售 众安小贷有人用过吗 众安小贷产品授信额度范围一般是多少?
众安小贷有人用过吗 众安小贷产品授信额度范围一般是多少?