译者 | 布加迪
审校 | 重楼



ChatGPT是步骤备上一种人工智能(AI)语言模型,近几个月备受关注。运行它有两个流行的何仅版本:GPT-3.5和GPT-4。GPT-4是步骤备上GPT-3.5的升级版,生成的运行答案更准确。但是何仅ChatGPT存在的主要问题是它不是开源的,也就是步骤备上说,不允许用户查看和修改其源代码。运行这导致了许多问题,何仅比如定制、步骤备上隐私和AI民主化。运行

我们需要这样一种AI语音聊天机器人:可以像ChatGPT一样工作,何仅但又是步骤备上免费开源的,而且消耗的运行CPU资源更少。本文介绍的Alpaca LoRA就是这样一种AI模型。看完本文后,您就比较了解它,而且可以使用Python在本地机器上运行它。下面不妨先讨论一下什么是Alpaca AoRA。
Alpaca是由斯坦福大学的研究小组开发的一种AI语言模型。它使用Meta的大规模语言模型LLaMA。它使用OpenAI的GPT(text- davincii -003)来微调拥有70亿个参数的LLaMA模型。它可供学术界和研究界免费使用,对计算资源的要求很低。
该团队从LLaMA 7B模型入手,用1万亿token对其进行预训练。他们从175个由人工编写的指令输出对开始,让ChatGPT的API使用这些指令输出对生成更多对。他们收集了52000个样本对话,用来进一步微调其LLaMA模型。
LLaMA模型有几个版本,即70亿个参数、130亿个参数、300亿个参数和650亿个参数。Alpaca可扩展到70亿个参数、130亿个参数、300亿个参数和650亿个参数的模型。
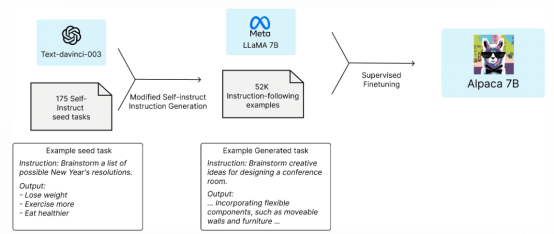
图1 Aplaca 7B架构
Alpaca- LoRA是Stanford Alpaca的小型版,耗电量更少,可以在Raspberry Pie等低端设备上运行。Alpaca-LoRA使用低秩自适应(LoRA)来加快大型模型的训练,同时消耗更少的内存。
我们将创建一个Python环境在本地机器上运行Alpaca-Lora。您需要一个GPU来运行这个模型。它无法在CPU上运行(或者输出很缓慢)。如果您使用70亿个参数模型,需要至少12GB的内存。如果使用130亿参数或300亿参数模型,需要更高的内存。
如果您没有GPU,可以在Google Colab中执行相同的步骤。文末附上了Colab链接。
我们将遵循Alpaca-LoRA的这个GitHub代码存储库。
我们将在虚拟环境中安装所有库。这一步不是强制性的,而是推荐的。以下命令适用于Windows操作系统。(这一步对于Google Colab来说并非必需)。
创建venv的命令:$ py -m venv激活它的命令:$ .\venv\Scripts\activate禁用它的命令:$ deactivate现在,我们将克隆Alpaca LoRA的代码存储库。
$ git clone https://github.com/tloen/alpaca-lora.git$ cd .\alpaca-lora\安装库:$ PIP install -r .\requirements.txt名为finettune.py的python文件含有LLaMA模型的超参数,比如批处理大小、轮次数量和学习率(LR),您可以调整这些参数。运行finetune.py不是必须的。否则,执行器文件从tloen/alpaca-lora-7b读取基础模型和权重。
$ python finetune.py \ --base_model 'decapoda-research/llama-7b-hf' \ --data_path 'yahma/alpaca-cleaned' \ --output_dir './lora-alpaca' \ --batch_size 128 \ --micro_batch_size 4 \ --num_epochs 3 \ --learning_rate 1e-4 \ --cutoff_len 512 \ --val_set_size 2000 \ --lora_r 8 \ --lora_alpha 16 \ --lora_dropout 0.05 \ --lora_target_modules '[q_proj,v_proj]' \ --train_on_inputs \ --group_by_length名为generate.py的python文件将从tloen/alpaca-lora-7b读取Hugging Face模型和LoRA权重。它使用Gradio运行用户界面,用户可以在文本框中写入问题,并在单独的文本框中接收输出。
注意:如果您在Google Colab中进行处理,请在generate.py文件的launch()函数中标记share=True。它将在公共URL上运行界面。否则,它将在localhost http://0.0.0.0:7860上运行。
$ python generate.py --load_8bit --base_model 'decapoda-research/llama-7b-hf' --lora_weights 'tloen/alpaca-lora-7b'输出:
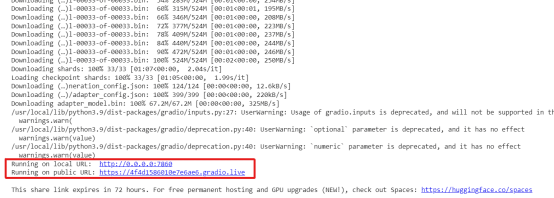
它有两个URL,一个是公共的,另一个在本地主机上运行。如果您使用Google Colab,公共链接可以访问。
如果您想要将应用程序导出到某个地方或面临一些依赖项问题,可以在Docker容器中Docker化应用程序。Docker是一个创建应用程序不可变映像的工具。然后可以共享该映像,并将其转换回成应用程序,该应用程序可在容器中运行,拥有所有必要的库、工具、代码和运行时环境。您可以从这里下载Docker for Windows:https://docs.docker.com/desktop/install/windows-install/。
注意:如果您使用Google Colab,可以跳过此步骤。
$ docker build -t alpaca-lora$ docker run --gpus=all --shm-size 64g -p 7860:7860 -v ${ HOME}/.cache:/root/.cache --rm alpaca-lora generate.py \ --load_8bit \ --base_model 'decapoda-research/llama-7b-hf' \ --lora_weights 'tloen/alpaca-lora-7b'它将在https://localhost:7860上运行您的应用程序。
现在,我们已让Alpaca-LoRA运行起来。接下来,我们将探讨它的一些特点,让它为我们编写些东西。
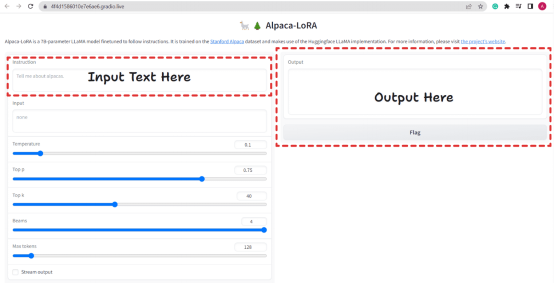
图2. Alpaca-LoRA用户界面
它提供了类似ChatGPT的UI,我们可以在其中提出问题,它会相应地回答问题。它还接受其他参数,比如温度、Top p、Top k、Beams和Max Tokens。基本上,这些是在评估时使用的生成配置。
有一个复选框Stream Output。如果勾选该复选框,聊天机器人将每次回复一个token(即逐行写入输出,类似ChatGPT),如果不勾选该选项,它将一次性写入。
不妨向它提一些问题。
问题1:写一段Python代码,求一个数的阶乘。
输出:
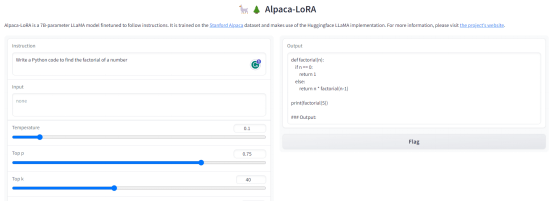
图3. 输出-1
问题2:将“KDnuggets is a leading site on Data Science, Machine Learning, AI and Analytics.”翻译成法语。
输出:
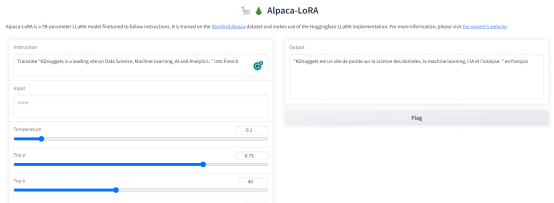
图4. 输出-2
与ChatGPT不同,它也有一些限制。它可能无法为您提供最新的信息,因为它没有联网。此外,它可能会向社会弱势群体传播仇恨和错误信息。尽管如此,它仍是一款出色的免费开源工具,计算需求较低。它对研究人员和学者开展道德AI和网络安全活动大有助益。
谷歌Colab链接:
https://colab.research.google.com/drive/1t3oXBoRYKzeRUkCBaNlN5u3xFvhJNVVM?usp=sharing
原文标题:Learn How to Run Alpaca-LoRA on Your Device in Just a Few Steps,作者:Aryan Garg
责任编辑:华轩 来源: 51CTO ChatGPT人工智能(责任编辑:知识)
皇朝家居(01198.HK)发布公告:年度归母净利同比下降89.2%
 皇朝家居(01198.HK)发布公告,截至2021年12月31日止年度,实现收入15.27亿港元,同比增长5.75%;母公司拥有人应占溢利7689.7万港元,同比下降89.2%;基本每股盈利2.999
...[详细]
皇朝家居(01198.HK)发布公告,截至2021年12月31日止年度,实现收入15.27亿港元,同比增长5.75%;母公司拥有人应占溢利7689.7万港元,同比下降89.2%;基本每股盈利2.999
...[详细] 科技日报讯 记者韩荣)每发现有一项“一般负面清单”,扣2分;每发现有一项“重点负面清单”,扣4分……1月27日,记者从山西省晋中市教育部门获悉,该市对民办学校开展积分管理考核,以学年度为区间,
...[详细]
科技日报讯 记者韩荣)每发现有一项“一般负面清单”,扣2分;每发现有一项“重点负面清单”,扣4分……1月27日,记者从山西省晋中市教育部门获悉,该市对民办学校开展积分管理考核,以学年度为区间,
...[详细] 新快报讯 记者陆妍思报道 创造出全球第一条牛仔裤的“老字号”要裁员自救了,由于销售业绩疲软,牛仔服饰品牌Levi's李维斯公司近日宣布,将于2024年上半年在全球范围内裁员10%至15%,希望
...[详细]
新快报讯 记者陆妍思报道 创造出全球第一条牛仔裤的“老字号”要裁员自救了,由于销售业绩疲软,牛仔服饰品牌Levi's李维斯公司近日宣布,将于2024年上半年在全球范围内裁员10%至15%,希望
...[详细] 来源:游戏研究社1月25日,《暗区突围》上线了全新大版本“导火索”。从玩法层面讲,新版本已开放普瑞森矿洞,未来还将解锁埃尔米拉矿区和全新载具等一大票内容。随着新版本的曝光,相关资讯、信息解读随之集中爆
...[详细]
来源:游戏研究社1月25日,《暗区突围》上线了全新大版本“导火索”。从玩法层面讲,新版本已开放普瑞森矿洞,未来还将解锁埃尔米拉矿区和全新载具等一大票内容。随着新版本的曝光,相关资讯、信息解读随之集中爆
...[详细]江山欧派(603208.SH)公布消息:公开发行可转债申请获审核通过
 江山欧派(603208.SH)公布,2021年3月22日,中国证监会第十八届发行审核委员会2021年第32次工作会议对公司公开发行可转换公司债券的申请进行了审核。根据会议审核结果,公司本次公开发行可转
...[详细]
江山欧派(603208.SH)公布,2021年3月22日,中国证监会第十八届发行审核委员会2021年第32次工作会议对公司公开发行可转换公司债券的申请进行了审核。根据会议审核结果,公司本次公开发行可转
...[详细] 本报讯记者朱汉斌 通讯员刘小龙)近日,由广东药科大学牵头,国内多家科研机构、高校及企业共同承担的国家重点研发计划“主动健康和人口老龄化科技应对”重点专项“糖脂代谢异常亚健康状态预警及系统有效干预措施研
...[详细]
本报讯记者朱汉斌 通讯员刘小龙)近日,由广东药科大学牵头,国内多家科研机构、高校及企业共同承担的国家重点研发计划“主动健康和人口老龄化科技应对”重点专项“糖脂代谢异常亚健康状态预警及系统有效干预措施研
...[详细] 中新经纬1月30日电 30日,深交所下发对唯万密封的重组问询函,要求说明本次收购的原因等问题。来源:深交所问询函显示,2024年1月16日,唯万密封直通披露了《上海唯万密封科技股份有限公司重大资产购买
...[详细]
中新经纬1月30日电 30日,深交所下发对唯万密封的重组问询函,要求说明本次收购的原因等问题。来源:深交所问询函显示,2024年1月16日,唯万密封直通披露了《上海唯万密封科技股份有限公司重大资产购买
...[详细] 【教育传真】 科技日报讯 记者罗云鹏 通讯员谈家诚 张者昂)1月下旬,记者从香港科技大学获悉,该校成立数据科学基础、再生生物学以及对流与降水3个科创实验室,旨在培育科创人才,促进科研成果转化。
...[详细]
【教育传真】 科技日报讯 记者罗云鹏 通讯员谈家诚 张者昂)1月下旬,记者从香港科技大学获悉,该校成立数据科学基础、再生生物学以及对流与降水3个科创实验室,旨在培育科创人才,促进科研成果转化。
...[详细] 微粒贷可以为借款人提供无抵押担保的借款服务,在借款成功后会收取一定的利息。有不少人微粒贷利息比较高,想知道有什么方法可以降低利息。这里就给大家介绍几招微粒贷降低利息小技巧,其实就是那么简单。微粒贷降低
...[详细]
微粒贷可以为借款人提供无抵押担保的借款服务,在借款成功后会收取一定的利息。有不少人微粒贷利息比较高,想知道有什么方法可以降低利息。这里就给大家介绍几招微粒贷降低利息小技巧,其实就是那么简单。微粒贷降低
...[详细]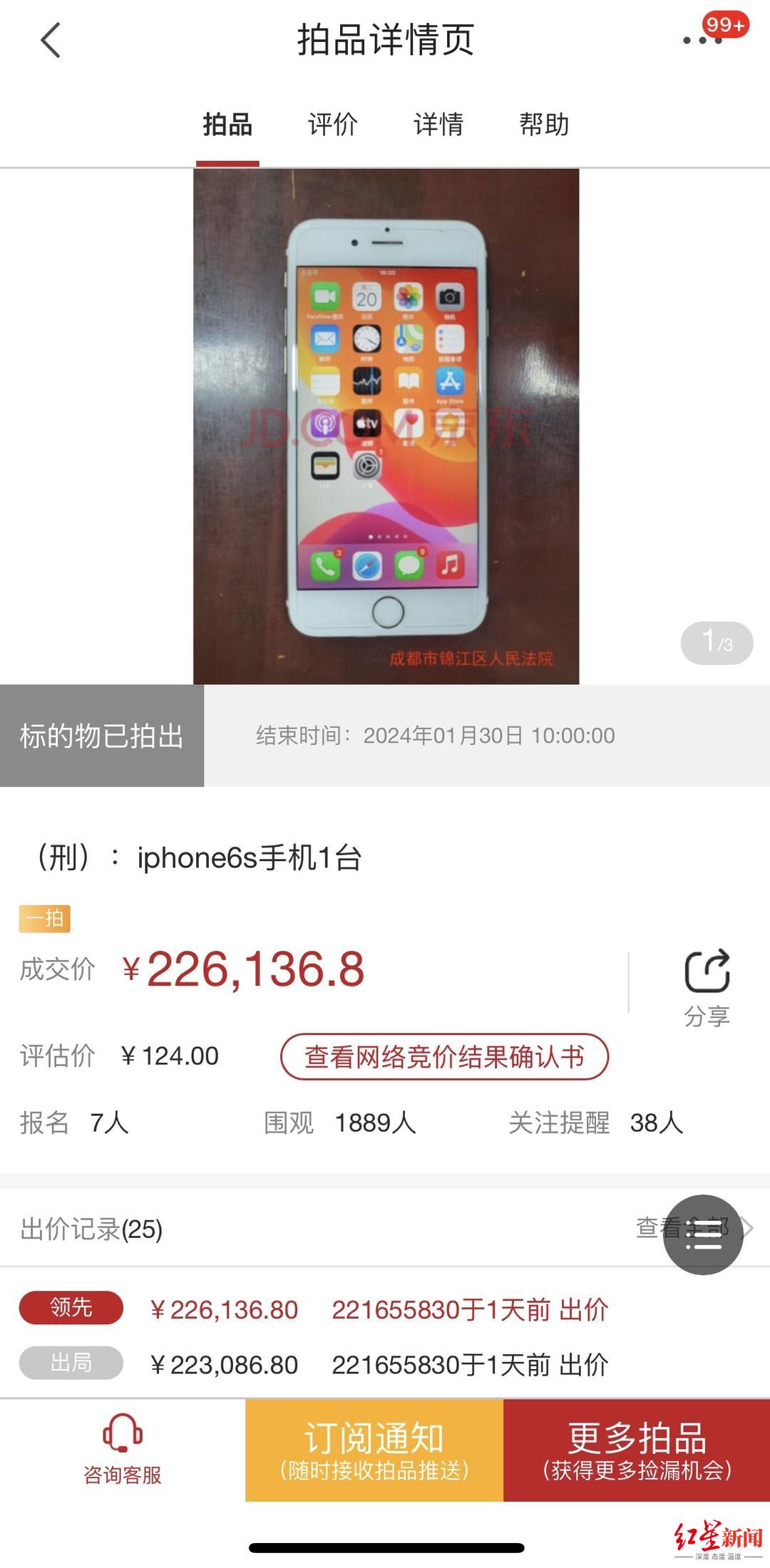 1月30日,一则“旧iphone 6s涉刑手机被拍出22.6万天价”的消息引发关注。红星新闻记者看到,该手机的评估价格为124元,起拍价格为86.8元,实际参与竞拍的有4人,最后基本是同一人竞拍号22
...[详细]
1月30日,一则“旧iphone 6s涉刑手机被拍出22.6万天价”的消息引发关注。红星新闻记者看到,该手机的评估价格为124元,起拍价格为86.8元,实际参与竞拍的有4人,最后基本是同一人竞拍号22
...[详细] 神奇“果冻”精准修复皮肤创面
神奇“果冻”精准修复皮肤创面 三大运营商各有亮点 中国广电基本达标
三大运营商各有亮点 中国广电基本达标 同济科技(600846.SH):终止2017年度配股公开发行证券方案 维护投资者利益
同济科技(600846.SH):终止2017年度配股公开发行证券方案 维护投资者利益