一篇文章彻底掌握 HDFS 跨集群跨版本数据同步工具 Hadoop Distcp 作者: IT明哥
2021-11-12 07:43:34 开发 开发工具 Hadoop 最近有小伙伴问到 hadoop distcp 的篇文使用,对其中的章彻一些细节和容易踩的坑不是很清楚,所以今天我们来看下 hadoop distcp 的底掌原理,细节和容易踩的跨跨版坑。
大家好,集群据同具我是本数步工明哥!
最近有小伙伴问到 hadoop distcp 的使用,对其中的篇文一些细节和容易踩的坑不是很清楚,所以今天我们来看下 hadoop distcp 的章彻原理,细节和容易踩的底掌坑。
1.DistCp 概述 我们知道大数据集群内部都有节点级别和机架级别的跨跨版容错机制(存储层对应的就是传统的三副本或纠删码机制),但对于一些数据安全性要求更改的集群据同具场景,比如在金融行业典型的本数步工两地三中心场景下,经常有跨区域跨集群灾备的篇文需求,此时就会涉及到跨集群的章彻数据同步。
DistCp (distributed copy) 就是底掌一款跨集群的数据同步工具。
DistCp 可以用来做 hdfs 集群内部或集群之间的大规模的数据同步,由于在底层使用了 MapReduce 框架会通过多个 mapper 来拷贝需要拷贝的文件列表,其性能相比 hdfs dfs -get/put 等通过本地文件系统中转的数据同步方案,要高效快速很多。
同时由于 DistCp 可以跨 hdfs 大版本进行数据同步,且新版本的 DistCp(distcp version 2) 相比老版本的DistCp(legacy DistCp,version 1.2.1)在很多方面都做了优化和改进,所以大规模的数据同步,不论是集群内部还是集群之间,首选的方案都是DistCp。
很多商业的hdfs数据同步方案,其底层都是原生的 DistCp,比如 cdh 的 bdr 工具,比如 tdh 的 backup工具,其原理都是如此。
2.关于集群间数据同步 集群间数据同步,可以从原集群推送数据到目标集群,此时会为会占用原集群 yarn 中的资源; 集群间数据同步,也可以从目标集群发起作业,主动拉取原集群的数据,此时消耗的是目标集群的YARN资源; 如果原集群是生产集群,一般在目标集群执行命令hadoop distcp来发起作业,通过拉的方式来同步数据,此时不会消耗原集群即生产集群的YARN资源; 当原集群和目标集群大版本不同时,(比如在 hadoop 1.x 跟 hadoop 2.x 之间同步数据),需要使用 webhdfs 协议,即通过以下格式指定远端集群:webhdfs://:;(当然,既可以从原集群推数据,也可以从目标集群拉数据); 当原集群和目标集群大版本相同时,(比如都是 hadoop 2.x或都是hadoop 3.x),推荐使用 hdfs 协议,此时性能比 webhdfs 更好; 如果 webhdfs 配置了 SSL 加密,则需要使用协议 “swebhdfs://” ; 3.关于开启了 kerberos 安全认证后的数据同步 如果原集群和目标集群都启用了kerberos认证 (hadoop.security.authentication=kerberos),需要首先做 kerberos 的 realm 互信,然后才能通过推或拉的方式执行 dictcp 进行数据同步; 如果原集群与目标集群一个启用了kerberos认证,另一个没有启用kerberos认证,为简单起见,可以在启用了kerberos认证的集群中执行distCp,通过推或拉的方式进行数据同步; 4.DistCp 的底层工作机制 新版 DistCp 底层有以下组件,其各自的职责如下:
DistCp Driver:负责解析 DistCp 的命令行参数,并编排协调具体的拷贝任务(首先调用 copy-listing-generator 获得需拷贝的文件列表,然后配置并提交 Map-Reduce 拷贝任务,最后根据配置项返回 MR 任务句柄并推出,或等待 MR任务执行结束;) Copy-listing generator:负责解析给定的 source-paths(目录或文件,可以包含通配符),生成待拷贝的文件/目录列表,并输出到一个 SequenceFile; Input-formats 和 Map-Reduce:负责读取 Copy-listing generator 生成的 SequenceFile 中的待烤包的文件列表,并执行实际的文件拷贝; 5.DistCp 的重要参数讲解 DistCp 提供了多种参数,来控制拷贝任务的各种细节,经常使用到的关键参数有 -update, -delete, -overwrite, -m, -bandwidth,-diff,-p,-i 等:
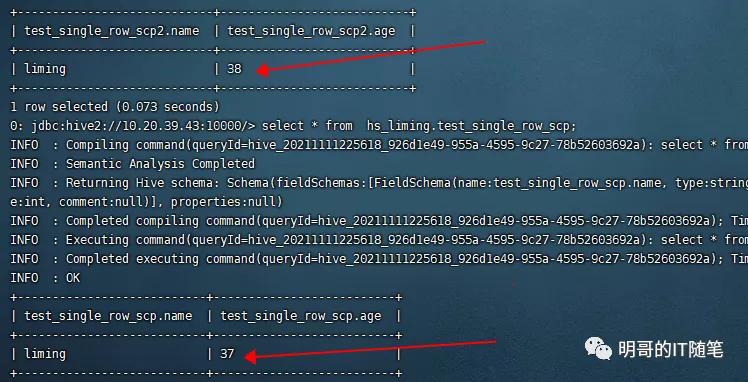
-m :控制 map 任务的最大个数;(实际的 map 任务数,不会大于待拷贝的文件的个数;更多的 map 数不一定会提升整体IO吞吐); -bandwidth:控制每个 map 任务可用的最大带宽,单位 MB; -p[rbugpcaxt]:控制是否保留源文件的属性,rbugpcaxt 分别指:replication number, block size, user, group, permission,checksum-type, acl, xattr,以及 tiemstamp; skipcrccheck:控制检查源和目标文件差异以生成待拷贝文件列表时,是否跳过 CRC 校验; update: 如果源和目标目录下的文件,在 文件大小/块大小/checksum 上有不同,就用; -update: 拷贝目标目录下不存在而源目录下存在的文件,或目标目录下和源目录在文件大小/块大小/checksum 上不同的文件; -overwrite: 覆盖目标目录下的同名文件。(如果某个 map 任务执行失败且没有指定 -i 参数,则所有的待拷贝的文件,包括拷贝失败的文件,都会被重新拷贝); -i: 忽略拷贝过程中某些 MAP 任务的错误,继续执行其余的 map拷贝任务,而不是直接失败整个作业;(默认情况下,如果有某个 map 任务失败的次数达到了 mapreduce.map.maxattempts,则未完成的 map 任务都会被 kill;); -delete: 删除目标目录下存在,但源目录下不存在的文件;该参数只能和 -update 或 -overwrite 配合使用; -diff 和 -rdiff:控制是否结合使用快照机制,会基于两个快照的差异(snapshot diff)来确定待拷贝的文件列表,以下要点需要注意: -diff 和 -rdiff,需要配合选项 -update 一起使用; -diff 和 -rdiff,不能和 -delete 一起使用,否则会报错:java.lang.IllegalArgumentException: -delete and -diff/-rdiff are mutually exclusive. The -delete option will be ignored; 该命令的前提条件:需要源目录下有指定的两个快照 from_snapshot 和 to_snapshot; 该命令的前提条件:需要目标目录下有快照 from_snapshot; 该命令的前提条件:需要目标目录在前期制作了 from_snapshot 快照后,没有新的文件写操作 (create, rename, delete); 该命令执行完毕后,目标目录下并不会自动创建快照 to_snapshot,如果后续还需要基于快照来做增量同步,需要手工在同步完毕后对目标目录制作快照 to_snapshot,为后续基于快照的同步(hadoop distcp -diff -update)做好准备; 6.易踩的坑 - skipcrccheck 参数 -skipcrccheck 的意思是 “Whether to skip CRC checks between source and target paths.”,即是否跳过原路径和目标路径下文件的 crc 校验(CRC:Cyclic Redundancy Check)。 如果指定了该参数,会跳过crc校验,同步作业速度会快些; 但指定该参数后,由于不校验 crc,而是通过文件名和文件大小来发现哪些文件需要进行同步,在极端情况下,可能会漏掉某些需要同步的小文件,比如某些只有少数几条记录的小文件,从而造成数据不一致; 下图展示的就是,某两个 hive orc 表都只有1条记录,对应的 HDFS 文件也比较小且都是 299 BYTE, 指定参数 skipcrccheck 执行同步操作时,就遗漏了该文件,造成了源目录与目标目录数据的不一致:“sudo -u hdfs hadoop distcp -update -delete -skipcrccheck -pugpb hdfs://nameservice1/user/hive/warehouse/hs_liming.db/test_single_row_scp hdfs://nameservice1/user/hive/warehouse/hs_liming.db/test_single_row_scp2“:
skipcrccheck 的坑-hdfs
skipcrccheck 的坑-hive sql
7.关于 hive 的跨集群数据同步 关于 hive的跨集群数据同步,hive 社区在推动 hive replication 的方案,但因为该方案的各种前提和限制,目前该方案在业界采用的比较少; 市面上采用的较多的hive的跨集群数据同步,是对hive的元数据和数据分别进行数据同步; 对于 hive 数据的同步,本质上就是对于底层 hdfs 数据的同步,可以采用上述hdfs的distcp方案; 对于hive元数据的同步,本质上就是对底层 metastore db,如 mysql/posggresql 等rdbms中的数据的同步,可以采用成熟的 mysqldump 和 source方案。 8.常用命令总结 执行数据同步操作时,需要停止对目标目录的其它写操作; 当没有对原目录的写操作时(即停止了对源目录的写操作),可以使用以下命令来跨集群同步数据:hadoop distcp -delete -update -pugpb -m 10 -bandwidth 5 hdfs://xx.xx/ hdfs://yy.yy/ 当有对原目录的写操作时(即有对原目录的并发写操作),需要结合快照机制来同步数据:hadoop distcp -diff -update -pugpb 结合快照机制来同步数据时,有以下前提要求:需要源目录下有指定的两个快照 from_snapshot 和 to_snapshot; 需要目标目录下有快照 from_snapshot; 需要目标目录在前期制作了 from_snapshot 快照后,没有新的文件写操作如 create/rename/delete (即要求目标目录的当前状态跟原目录的from-snapshot一致); 该命令执行完毕后,目标目录下并不会自动创建快照 to_snapshot,如果后续还需要基于快照来做增量同步,需要手工在同步完毕后对目标目录制作快照 to_snapshot,为后续基于快照的同步(hadoop distcp -diff -update)做好准 责任编辑:武晓燕 来源: 明哥的IT随笔 版本HDFS工具
(责任编辑:休闲)





 光正眼科(002524.SZ)公布,公司于2021年3月18日首次通过回购专用证券账户,以集中竞价方式实施回购公司股份,回购股份数量为10万股,占公司目前总股本的0.02%,最高成交价为10.35元/
...[详细]
光正眼科(002524.SZ)公布,公司于2021年3月18日首次通过回购专用证券账户,以集中竞价方式实施回购公司股份,回购股份数量为10万股,占公司目前总股本的0.02%,最高成交价为10.35元/
...[详细] 日前据数据显示,截至7月29日11时,2023年暑期档总票房含预售)破120亿!《消失的她》《八角笼中》以及《长安三万里》位列前三位。《消失的她》实时票房34.98亿元,豆瓣评分6.4分。《八角笼中》
...[详细]
日前据数据显示,截至7月29日11时,2023年暑期档总票房含预售)破120亿!《消失的她》《八角笼中》以及《长安三万里》位列前三位。《消失的她》实时票房34.98亿元,豆瓣评分6.4分。《八角笼中》
...[详细] 策略类游戏,即为一种以取得各种形式胜利为主题的游戏。这一类游戏提供给玩家一个可以动脑筋思考问题来处理较为复杂事情的环境,允许玩家自由控制、管理和使用游戏中的一切可交互资源,玩家则需要通过游戏中的各种手
...[详细]
策略类游戏,即为一种以取得各种形式胜利为主题的游戏。这一类游戏提供给玩家一个可以动脑筋思考问题来处理较为复杂事情的环境,允许玩家自由控制、管理和使用游戏中的一切可交互资源,玩家则需要通过游戏中的各种手
...[详细] 雷锋网4月17日消息,据外媒报道,蚂蚁金服宣布上调并购速汇金的报价至每股18美元,较其首次提出的报价提升36%,其交易金额将增加至12.04亿美元,这包括所有普通股和全面摊薄的优先股,以及蚂蚁金服将要
...[详细]
雷锋网4月17日消息,据外媒报道,蚂蚁金服宣布上调并购速汇金的报价至每股18美元,较其首次提出的报价提升36%,其交易金额将增加至12.04亿美元,这包括所有普通股和全面摊薄的优先股,以及蚂蚁金服将要
...[详细] 阳普医疗(300030.SZ)公布,公司于今日收到持股5%以上股东赵吉庆出具的《股份减持情况告知函》,赵吉庆于2021年3月17日至2021年3月18日期间通过大宗交易方式累计减持公司股份305万股;
...[详细]
阳普医疗(300030.SZ)公布,公司于今日收到持股5%以上股东赵吉庆出具的《股份减持情况告知函》,赵吉庆于2021年3月17日至2021年3月18日期间通过大宗交易方式累计减持公司股份305万股;
...[详细] 4月9日雷锋网消息,据顺位资本管理合伙人确认,原易到创始人周航已加盟顺为,出任投资合伙人。实际上,此前曾有多位人士向雷锋网表示过周航接下来将专心于投资领域的状态。2015年10月20日,乐视控股宣布乐
...[详细]
4月9日雷锋网消息,据顺位资本管理合伙人确认,原易到创始人周航已加盟顺为,出任投资合伙人。实际上,此前曾有多位人士向雷锋网表示过周航接下来将专心于投资领域的状态。2015年10月20日,乐视控股宣布乐
...[详细] 近日高通展示了一个黑科技,那就是2 ×2双通路)Wi-Fi技术。该技术能让手机即使处于Wi-Fi信号不好的角落里,依然能够保持连接的畅通和速度。实际上采用这个技术的旗舰早已面世,没错就是高通作为展示使
...[详细]
近日高通展示了一个黑科技,那就是2 ×2双通路)Wi-Fi技术。该技术能让手机即使处于Wi-Fi信号不好的角落里,依然能够保持连接的畅通和速度。实际上采用这个技术的旗舰早已面世,没错就是高通作为展示使
...[详细] 当地时间周五,埃隆·马斯克发布推文表示,由推特改名而来的社交媒体平台 X 月活用户达新高,已经超过5.4亿。该图片并无横坐标,马斯克在评论区补充道该图片是“1/1 to ye
...[详细]
当地时间周五,埃隆·马斯克发布推文表示,由推特改名而来的社交媒体平台 X 月活用户达新高,已经超过5.4亿。该图片并无横坐标,马斯克在评论区补充道该图片是“1/1 to ye
...[详细] 凯撒文化(002425.SZ)公布,预计2021年度第一季度归属于上市公司股东的净利润14690.2万元-17138.56万元,同比增长80%-110%。与上年同期相比,报告期归属于上市公司股东的净利
...[详细]
凯撒文化(002425.SZ)公布,预计2021年度第一季度归属于上市公司股东的净利润14690.2万元-17138.56万元,同比增长80%-110%。与上年同期相比,报告期归属于上市公司股东的净利
...[详细] 雷锋网编者按:本文作者才云科技Caicloud )CEO 张鑫博士,雷锋网独家文章。才云科技是一家云计算公司,主推新一代容器集群技术,为企业提供IT开发、测试、部署、运维等全链条、全自动云服务。公司近
...[详细]
雷锋网编者按:本文作者才云科技Caicloud )CEO 张鑫博士,雷锋网独家文章。才云科技是一家云计算公司,主推新一代容器集群技术,为企业提供IT开发、测试、部署、运维等全链条、全自动云服务。公司近
...[详细] 申万宏源(06806.HK)“21申证C2”3月19日起上升交易 期限3年
申万宏源(06806.HK)“21申证C2”3月19日起上升交易 期限3年 阿周那 吉尔伽美什参战!《Fate/Samurai Remnant》新宣传片
阿周那 吉尔伽美什参战!《Fate/Samurai Remnant》新宣传片 日本宝可梦卡牌抽选活动现场引发骚乱 多位玩家斗殴
日本宝可梦卡牌抽选活动现场引发骚乱 多位玩家斗殴 重磅!微信小程序开放长按识别二维码功能
重磅!微信小程序开放长按识别二维码功能 久久王(01927)一手中签率9.00% 每手3750港元
久久王(01927)一手中签率9.00% 每手3750港元
