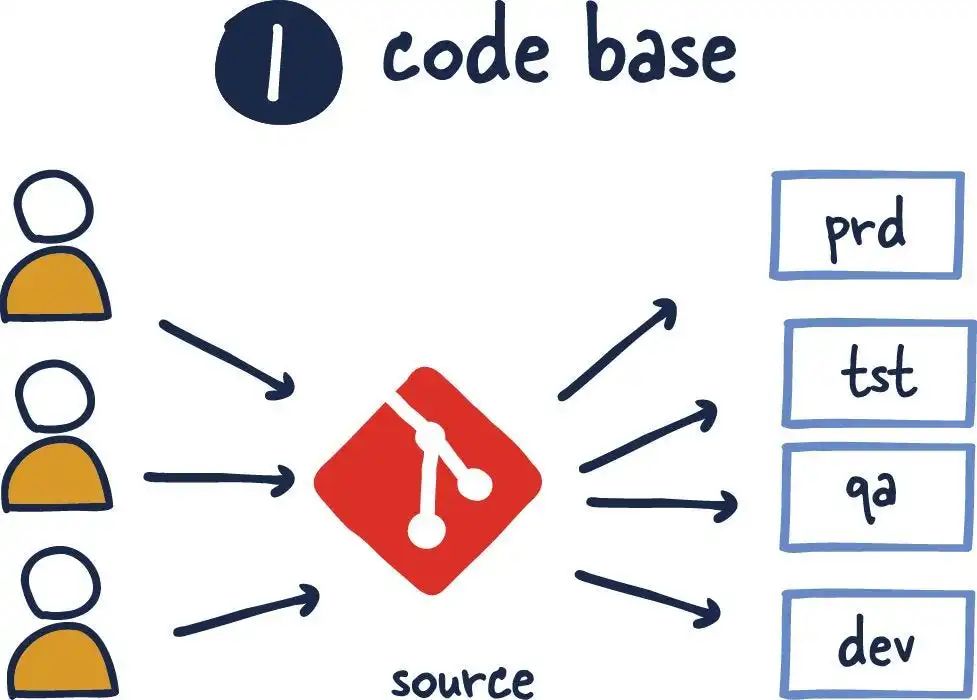
在大数据行业内,表计尤其是算优数仓建设中,一直有一个绕不开的化方难题,就是种基大表的分析计算(这里的大表指亿级以上)。特别是于布大表之间的 Join 分析,对任何公司数据部门都是隆过滤器一个挑战!
主要有以下挑战:

优点:简单粗暴,对业务和数据开发人员友好,不用调整。
缺点:费钱,看你公司是否有钱。
优点:可以在不大幅增加计算集群成本的情况下,完成日常计算任务。
缺点:对数据和业务都有一定要求,数据一般要求是日志类数据。或者具有一定的生命周期数据(历史数据可归档)。
Spark 经典算法 SortMergeJoin(以大表间的 Join 分析为例)。
该算法也可以简化流程为: Map 一> Shuffle 一> Sort 一> Merge 一> Reduce

该算法的性能瓶颈主要在 Sort Merge Shuffle 阶段(红色流程部分),数据量越大,资源要求越高,性能越低。
大数据计算优化思路,核心无非就三条:增加计算资源;减少被计算数据量;优化计算算法。其中前两条是我们普通人最常用的方法。
两个大表的 Join ,是不是真的每天都有大量的数据有变更呢?如果是的话,那我们的业务就应该思考一下是否合理了。
其实在我们的日常实践场景中,大部分是两个表里面的数据每天只有少量(十万百万至千万级)数据随机变化,大部分数据是不变的。
说到这里,很多人的第一想法是,我们增加分区,按数据是否有变化进行区分,计算有变化的(今日有更新的业务数据),合并未变化的(昨日计算完成的历史数据),不就可以解决问题了。其实这个想法存在以下问题:
 图片
图片
问题读到这里,如果我们分别把表 A、表 B 的有变化记录的关联主键取出来合并在一起,形成一个数组变量。计算的时候用这个变量分别从表 A 和表 B 中过滤出有变化的数据进行计算,并从未变化的表(昨日计算完成的历史数据)中过滤出不存在的(即未变化历史结果数据)。这样两份数据简单合并到一起,不就是表 A 和表 B 全量 Join 计算的结果了吗!
也许这里有人会有疑惑,不是说布隆过滤器是命中并不代表一定存在,不命中才代表一定不存在!其实这个命中不代表一定存在,是一个极少量概率问题,即极少量没有更新的数据也会命中布隆过滤器,从而参与了接下来的数据计算,实际上只要所有变化的数据能命中即可。这个不影响它已经帮我买过滤了绝大部分不需要计算的数据。
大家可以根据需要参考、修改和优化,有更好的实现方式欢迎大家分享交流。
程序流程图
 图片
图片
Spark 函数 Java 代码实现。
package org.example;import org.apache.curator.shaded.com.google.common.hash.BloomFilter;import org.apache.curator.shaded.com.google.common.hash.Funnels;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileStatus;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.spark.sql.api.java.*;import org.apache.spark.SparkConf;import java.io.BufferedReader;import java.io.IOException;import java.io.InputStream;import java.io.InputStreamReader;import java.nio.charset.StandardCharsets;import java.util.concurrent.ConcurrentHashMap;import org.apache.lucene.util.RamUsageEstimator;/** * add by chengwansheng */class MyBloomFilter { private BloomFilter bloomFilter; public MyBloomFilter(BloomFilter b) { bloomFilter = b; } public BloomFilter getBloomFilter() { return bloomFilter; }}public class BloomUdf implements UDF2<Object, String, Boolean> { //最大记录限制,安全起见 private static int maxSize = 50000000; //布隆过滤器是否开启配置, 1 开启,0 关闭 private static int udfBloomFilterEnable; //布隆过滤器是否开启参数,默认开启 private static String bloomFilterConfKey = "spark.myudf.bloom.enable"; //加配置配置参数,目前不起作用?? static { SparkConf sparkConf = new SparkConf(); udfBloomFilterEnable = sparkConf.getInt(bloomFilterConfKey, 1); System.out.println("the spark.myudf.bloom.enable value " + udfBloomFilterEnable); } //布隆过滤器列表,支持多个布隆过滤器 private static ConcurrentHashMap<String, MyBloomFilter> bloomFilterMap = new ConcurrentHashMap<>(); /** * 布隆过滤器核心构建方法 * 通过读取表的 hdfs 文件信息,构建布隆过滤器 * 一个 jvm 只加载一次 * @param key * @param path * @throws IOException */ private synchronized static void buildBloomFilter(String key, String path) throws IOException { if (!bloomFilterMap.containsKey(key)) { BloomFilter bloomFilter; Configuration cnotallow=new Configuration(); FileSystem hdfs=FileSystem.get(conf); Path pathDf=new Path(path); FileStatus[] stats=hdfs.listStatus(pathDf); //获取记录总数 long sum = 0; for (int i=0; i<stats.length; i++){ InputStream inputStream=hdfs.open(stats[i].getPath()); InputStreamReader inputStreamReader= new InputStreamReader(inputStream); BufferedReader reader=new BufferedReader(inputStreamReader); sum = sum + reader.lines().count(); } if(sum > maxSize) { //如果数据量大于期望值,则将布隆过滤器置空(即布隆过滤器不起作用) System.out.println("the max number is " + maxSize + ", but target num is too big, the " + key + " bloom will be invalid"); bloomFilter = null; } else { //默认 1000 W,超过取样本数据 2 倍的量。这里取 2 倍是为了提高布隆过滤器的效果, 2 倍是一个比较合适的值 long exceptSize = sum*2>10000000?sum*2:10000000; bloomFilter = BloomFilter.create(Funnels.stringFunnel(StandardCharsets.UTF_8), (int) exceptSize); for (int i=0; i<stats.length; i++){ //打印每个文件路径 System.out.println(stats[i].getPath().toString()); //读取每个文件 InputStream inputStream=hdfs.open(stats[i].getPath()); InputStreamReader inputStreamReader= new InputStreamReader(inputStream); BufferedReader reader=new BufferedReader(inputStreamReader); String line=""; while((line=reader.readLine())!=null){ bloomFilter.put(line); } } } MyBloomFilter myBloomFilter = new MyBloomFilter(bloomFilter); bloomFilterMap.put(key, myBloomFilter); System.out.println("the bloom " + key + " size is " + RamUsageEstimator.humanSizeOf(bloomFilter) + " num " + sum); } } /** * 核心调用方法 * 参数 s :被过滤的参数 * 参数 key :需要构建的布隆过滤器,此处是库名 + 表名称,即 db_name.table_name * @param s * @param key * @return * @throws Exception */ @Override public Boolean call(Object s, String key) throws Exception { //如果 spark.myudf.bloom.enable 参数配置为 0 ,则布隆过滤器失效,直接返回 true if (udfBloomFilterEnable == 0) { return true; } if (!bloomFilterMap.containsKey(key)) { String[] table_array = key.split("\\."); if (table_array.length != 2) { String msg = "the key is invalid: " + key + ", must like db_name.table_name"; System.out.println(msg); throw new IOException(msg); } String dbName = table_array[0]; String tableName = table_array[1]; String path = "/hive/" + dbName + ".db/" + tableName; System.out.println(path); //构建布隆过滤器 buildBloomFilter(key, path); } if (!bloomFilterMap.containsKey(key)) { String msg = "not found bloom filter " + key; System.out.println(msg); throw new IOException(msg); } BloomFilter bloomFilter = bloomFilterMap.get(key).getBloomFilter(); if (bloomFilter == null) { //如果数据量大于期望值,则直接返回真,即布隆过滤器不起作用 return true; } else { return bloomFilter.mightContain(String.valueOf(s)); } }}表信息和数据准备。
--建表数据create table default.A ( item_id bigint comment '商品ID', item_name string comment '商品名称', item_price bigint comment '商品价格', create_time timestamp comment '创建时间', update_time timestamp comment '创建时间')create table default.B ( item_id bigint comment '商品ID', sku_id bigint comment 'skuID', sku_price bigint comment '商品价格', create_time timestamp comment '创建时间', update_time timestamp comment '创建时间')create table default.ot ( item_id bigint comment '商品ID', sku_id bigint comment 'skuID', sku_price bigint comment '商品价格', item_price bigint comment '商品价格') PARTITIONED BY (pt string COMMENT '分区字段') --准备数据insert overwrite table default.A values(1,'测试1',101,'2023-03-25 08:00:00','2023-03-25 08:00:00'),(2,'测试2',102,'2023-03-25 08:00:00','2023-03-25 08:00:00'),(3,'测试2',103,'2023-03-25 08:00:00','2023-03-25 08:00:00'),(4,'测试2',104,'2023-03-25 08:00:00','2023-04-22 08:00:00'),(5,'测试2',105,'2023-03-25 08:00:00','2023-04-22 08:00:00');insert overwrite table default.B values (1,11,201,'2023-03-25 08:00:00','2023-03-25 08:00:00'),(1,12,202,'2023-03-25 08:00:00','2023-03-25 08:00:00'),(1,13,203,'2023-04-22 08:00:00','2023-04-22 08:00:00'),(2,21,211,'2023-03-25 08:00:00','2023-03-25 08:00:00'),(2,22,212,'2023-03-25 08:00:00','2023-03-25 08:00:00'),(4,42,212,'2023-03-25 08:00:00','2023-03-25 08:00:00'),(5,51,251,'2023-03-25 08:00:00','2023-03-25 08:00:00'),(5,52,252,'2023-04-22 08:00:00','2023-04-22 08:00:00'),(5,53,253,'2023-04-22 08:00:00','2023-04-22 08:00:00');insert overwrite table default.ot partition(pt='20230421')values (1,11,201,101),(1,12,202,101),(2,21,211,102),(2,22,212,102),(4,42,212,114),(5,51,251,110);原来处理的 SQL 语句。
insert overwrite table default.ot partition(pt='20230422')select B.item_id ,B.sku_id ,B.sku_price ,A.item_pricefrom B left join A on(A.item_id=B.item_id)使用布隆过滤器的 SQL(Java 函数导入 Spark,函数名为 “bloom_filter”)。
--构建布隆过滤器drop table if exists tmp.tmp_primary_key;create table tmp.tmp_primary_key stored as TEXTFILE as select item_idfrom ( select item_id from default.A where update_time>='2023-04-22' union all select item_id from default.B where update_time>='2023-04-22') where length(item_id)>0group by item_id;--增量数据计算insert overwrite table default.ot partition(pt='20230422')select B.item_id ,B.sku_id ,B.sku_price ,A.item_pricefrom default.B left join default.A on(A.item_id=B.item_id and bloom_filter(A.item_id, "tmp.tmp_primary_key"))where bloom_filter(B.item_id, "tmp.tmp_primary_key")union all --合并历史未变更数据select item_id,sku_id,sku_price,item_pricefrom default.otwhere not bloom_filter(item_id, "tmp.tmp_primary_key")and pt='20230421'从上面代码可以看出,使用布隆过滤器的 SQL,核心业务逻辑代码只是在原来全量计算的逻辑中增加了过滤条件而已,使用起来还是比较方便的。
以我司的 “dim.dim_itm_sku_info_detail_d” 和 “dim.dim_itm_info_detail_d” 任务为例,使用引擎 Spark2。
 图片
图片
从理论分析和实测效果来看,使用布隆过滤器的解决方案可以大幅提升任务的性能,并减少集群资源的使用。
该方案不仅适用大表间 Join 分析计算,也适用大表相关的其它分析计算需求,核心思想就是计算有必要的数据,排除没必要数据,减小无效的计算损耗。
责任编辑:武晓燕 来源: 政采云技术 布隆过滤器优化(责任编辑:热点)
华润医药(03320.HK):东阿阿胶年度实现净利4328.93万元 基本每股收益0.07元
 华润医药(03320.HK)发布公告,东阿阿胶(000423.SZ)公布其截至2020年12月31日止年度的年报,东阿阿胶实现营业收入34.09亿元,同比增长14.79%%;归属于上市东阿阿胶股东的净
...[详细]
华润医药(03320.HK)发布公告,东阿阿胶(000423.SZ)公布其截至2020年12月31日止年度的年报,东阿阿胶实现营业收入34.09亿元,同比增长14.79%%;归属于上市东阿阿胶股东的净
...[详细]世界最大跨度公铁合建桥梁正式开工 主桥采用主跨1488米斜拉
 10月31日,由中国中铁旗下中铁大桥院勘察设计、中铁大桥局施工的世界最大跨度公铁合建桥梁——甬舟铁路西堠门公铁两用大桥正式开工建设。西堠门公铁两用大桥是甬舟铁路控制性工程,全长
...[详细]
10月31日,由中国中铁旗下中铁大桥院勘察设计、中铁大桥局施工的世界最大跨度公铁合建桥梁——甬舟铁路西堠门公铁两用大桥正式开工建设。西堠门公铁两用大桥是甬舟铁路控制性工程,全长
...[详细]3家世界500强企业联手开启清洁能源高质量国际合作 实现产业链共赢
11月6日,国家能源投资集团有限责任公司(简称国家能源集团)与蒂森克虏伯股份有限公司(简称蒂森克虏伯)签署合作谅解备忘录,国家能源集团全资子公司国华能源投资有限公司(简称国华投资公司)与蒂森克虏伯新纪
...[详细] 9月28日,国家“十四五”石油天然气发展规划重点项目——西气东输四线天然气管道工程正式开工。西气东输四线是继西气东输一线、二线、三线管道之后,连接中亚和
...[详细]
9月28日,国家“十四五”石油天然气发展规划重点项目——西气东输四线天然气管道工程正式开工。西气东输四线是继西气东输一线、二线、三线管道之后,连接中亚和
...[详细]“放水养鱼”式管理激发市场活力 安徽降本减负典型经验做法获点赞
 学会“放水养鱼”,尽一切努力把企业负担降下来。11月15日,记者从第十届安徽省减负政策宣传周上了解到,截至9月底,规模以上工业企业每百元营业收入中的成本为83.73元,这一数字
...[详细]
学会“放水养鱼”,尽一切努力把企业负担降下来。11月15日,记者从第十届安徽省减负政策宣传周上了解到,截至9月底,规模以上工业企业每百元营业收入中的成本为83.73元,这一数字
...[详细]辽宁省最长高速公路隧道开工 建成运营后将推动辽东地区旅游业快速增长
10月10日,由中国中铁旗下中铁(辽宁)本桓高速公路有限公司投资建设、中铁隧道局承建的本桓高速公路摩天岭隧道出口左线开始进洞施工。本桓高速公路起于本溪市明山区威宁营村西南(接丹阜高速K163+260处
...[详细]中国船舶“新伊敦”轮正式命名交付 货舱总舱容17.5万立方米
9月24日,中国船舶集团旗下大船集团联合中船贸易为招商局集团旗下招商轮船建造的30万吨VLCC “新伊敦”轮正式命名交付。同日,大船集团联合中船贸易成功承接招商轮船2艘17.5
...[详细] 11月2日,从市口岸物流办了解到,今年以来,自贡市进一步提升跨境贸易便利化,持续优化口岸营商环境。前三季度,自贡市进口整体通关时间为21.74小时,出口整体通关时间为1.18小时,分别较2017年压缩
...[详细]
11月2日,从市口岸物流办了解到,今年以来,自贡市进一步提升跨境贸易便利化,持续优化口岸营商环境。前三季度,自贡市进口整体通关时间为21.74小时,出口整体通关时间为1.18小时,分别较2017年压缩
...[详细] 近日,住房和城乡建设部会同国家发改委、财政部、自然资源部、国家税务总局印发了《关于做好2021年度发展保障性租赁住房情况监测评价工作的通知》。《通知》明确,新市民和青年人多、房价偏高或上涨压力较大的大
...[详细]
近日,住房和城乡建设部会同国家发改委、财政部、自然资源部、国家税务总局印发了《关于做好2021年度发展保障性租赁住房情况监测评价工作的通知》。《通知》明确,新市民和青年人多、房价偏高或上涨压力较大的大
...[详细]湖北黄石华新(阳新)亿吨机制砂石项目正式投产 建有19个机制砂车间
近日,中交集团所属中交二航局参建的全球产能最大机制砂石生产线——湖北黄石华新(阳新)亿吨机制砂石项目正式投产。华新(阳新)亿吨机制砂石项目位于黄石市阳新县,建有19个机制砂车间
...[详细] ST地矿(000409.SZ):拟向关联方兖矿集团借款不超12亿元 构成关联交易
ST地矿(000409.SZ):拟向关联方兖矿集团借款不超12亿元 构成关联交易 注意了!达川区市场监管药械价格专项执法“瓮中捉鳖”来了
注意了!达川区市场监管药械价格专项执法“瓮中捉鳖”来了 达川区百节市场监管所:“春雷行动2023”向冻库暨猪肉市场挥“铁拳”
达川区百节市场监管所:“春雷行动2023”向冻库暨猪肉市场挥“铁拳” 绿色债券迎密集发行期 银行参与绿色金融债券发行的热情高涨
绿色债券迎密集发行期 银行参与绿色金融债券发行的热情高涨