[[379685]]
今天检查ceph集群,理过发现有pg丢失,记次于是处程就有了本文~~~
![记一次Ceph pg unfound处理过程 [[379685]] 今天检查ceph集群](https://image11.m1905.cn/mdb/uploadfile/2017/1114/thumb_1_128_176_20171114093146533217.jpg)
1.查看集群状态
![记一次Ceph pg unfound处理过程 [[379685]] 今天检查ceph集群](https://image11.m1905.cn/mdb/uploadfile/2017/1129/thumb_1_128_176_20171129112734420201.jpg)
- [root@k8snode001 ~]# ceph health detail
- HEALTH_ERR 1/973013 objects unfound (0.000%); 17 scrub errors; Possible data damage: 1 pg recovery_unfound, 8 pgs inconsistent, 1 pg repair; Degraded data redundancy: 1/2919039 objects degraded (0.000%), 1 pg degraded
- OBJECT_UNFOUND 1/973013 objects unfound (0.000%)
- pg 2.2b has 1 unfound objects
- OSD_SCRUB_ERRORS 17 scrub errors
- PG_DAMAGED Possible data damage: 1 pg recovery_unfound, 8 pgs inconsistent, 1 pg repair
- pg 2.2b is active+recovery_unfound+degraded, acting [14,22,4], 1 unfound
- pg 2.44 is active+clean+inconsistent, acting [14,8,21]
- pg 2.73 is active+clean+inconsistent, acting [25,14,8]
- pg 2.80 is active+clean+scrubbing+deep+inconsistent+repair, acting [4,8,14]
- pg 2.83 is active+clean+inconsistent, acting [14,13,6]
- pg 2.ae is active+clean+inconsistent, acting [14,3,2]
- pg 2.c4 is active+clean+inconsistent, acting [8,21,14]
- pg 2.da is active+clean+inconsistent, acting [23,14,15]
- pg 2.fa is active+clean+inconsistent, acting [14,23,25]
- PG_DEGRADED Degraded data redundancy: 1/2919039 objects degraded (0.000%), 1 pg degraded
- pg 2.2b is active+recovery_unfound+degraded, acting [14,22,4], 1 unfound
从输出发现pg 2.2b is active+recovery_unfound+degraded, acting [14,22,4], 1 unfound
![记一次Ceph pg unfound处理过程 [[379685]] 今天检查ceph集群](https://image11.m1905.cn/mdb/uploadfile/2017/1128/thumb_1_128_176_20171128031838736841.jpg)
现在我们来查看pg 2.2b,看看这个pg的理过想想信息。
- [root@k8snode001 ~]# ceph pg dump_json pools |grep 2.2b
- dumped all
- 2.2b 2487 1 1 0 1 9533198403 3048 3048 active+recovery_unfound+degraded 2020-07-23 08:56:07.669903 10373'5448370 10373:7312614 [14,记次22,4] 14 [14,22,4] 14 10371'5437258 2020-07-23 08:56:06.637012 10371'5437258 2020-07-23 08:56:06.637012 0
可以看到它现在只有一个副本
2.查看pg map
- [root@k8snode001 ~]# ceph pg map 2.2b
- osdmap e10373 pg 2.2b (2.2b) -> up [14,22,4] acting [14,22,4]
从pg map可以看出,pg 2.2b分布到osd [14,处程22,4]上
3.查看存储池状态
- [root@k8snode001 ~]# ceph osd pool stats k8s-1
- pool k8s-1 id 2
- 1/1955664 objects degraded (0.000%)
- 1/651888 objects unfound (0.000%)
- client io 271 KiB/s wr, 0 op/s rd, 52 op/s wr
- [root@k8snode001 ~]# ceph osd pool ls detail|grep k8s-1
- pool 2 'k8s-1' replicated size 3 min_size 1 crush_rule 0 object_hash rjenkins pg_num 256 pgp_num 256 last_change 88 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd
4.尝试恢复pg 2.2b丢失地块
- [root@k8snode001 ~]# ceph pg repair 2.2b
如果一直修复不成功,可以查看卡住PG的理过具体信息,主要关注recovery_state,记次命令如下
- [root@k8snode001 ~]# ceph pg 2.2b query
- {
- "......
- "recovery_state": [
- {
- "name": "Started/Primary/Active",处程
- "enter_time": "2020-07-21 14:17:05.855923",
- "might_have_unfound": [],
- "recovery_progress": {
- "backfill_targets": [],
- "waiting_on_backfill": [],
- "last_backfill_started": "MIN",
- "backfill_info": {
- "begin": "MIN",
- "end": "MIN",
- "objects": []
- },
- "peer_backfill_info": [],
- "backfills_in_flight": [],
- "recovering": [],
- "pg_backend": {
- "pull_from_peer": [],
- "pushing": []
- }
- },
- "scrub": {
- "scrubber.epoch_start": "10370",
- "scrubber.active": false,
- "scrubber.state": "INACTIVE",
- "scrubber.start": "MIN",
- "scrubber.end": "MIN",
- "scrubber.max_end": "MIN",
- "scrubber.subset_last_update": "0'0",
- "scrubber.deep": false,
- "scrubber.waiting_on_whom": []
- }
- },
- {
- "name": "Started",
- "enter_time": "2020-07-21 14:17:04.814061"
- }
- ],
- "agent_state": { }
- }
如果repair修复不了;两种解决方案,回退旧版或者直接删除
5.解决方案
- 回退旧版
- [root@k8snode001 ~]# ceph pg 2.2b mark_unfound_lost revert
- 直接删除
- [root@k8snode001 ~]# ceph pg 2.2b mark_unfound_lost delete
6.验证
我这里直接删除了,理过然后ceph集群重建pg,记次稍等会再看,pg状态变为active+clean
- [root@k8snode001 ~]# ceph pg 2.2b query
- {
- "state": "active+clean",处程
- "snap_trimq": "[]",
- "snap_trimq_len": 0,
- "epoch": 11069,
- "up": [
- 12,
- 22,
- 4
- ],
再次查看集群状态
- [root@k8snode001 ~]# ceph health detail
- HEALTH_OK
【编辑推荐】
责任编辑:姜华 来源: 今日头条 Ceph octopus集群运维
(责任编辑:休闲)
航天科技集团研制大气环境监测卫星大气一号上线 高精度监测能力提升
 4月16日,长四丙火箭在太原卫星发射中心成功发射升空。这一次,搭乘金牌“太空专列”的是大气环境监测卫星(简称大气一号),是世界首颗二氧化碳激光探测卫星。在705公里的太阳同步轨
...[详细]
4月16日,长四丙火箭在太原卫星发射中心成功发射升空。这一次,搭乘金牌“太空专列”的是大气环境监测卫星(简称大气一号),是世界首颗二氧化碳激光探测卫星。在705公里的太阳同步轨
...[详细] 步森股份公告,本公司于近日收到中易金经《关于无法支付剩余股权转让对价款暨申请终止交易的函》。由于中易金经经营和融资出现重大不利变化,资金筹措遇到困难,已无力支付剩余转让款。经双方共同协商决定,签署《股
...[详细]
步森股份公告,本公司于近日收到中易金经《关于无法支付剩余股权转让对价款暨申请终止交易的函》。由于中易金经经营和融资出现重大不利变化,资金筹措遇到困难,已无力支付剩余转让款。经双方共同协商决定,签署《股
...[详细] “重新忙碌起来之后,我们终于看到了往年暑期旅游旺季的影子。”这是一位旅行社门店负责人对于过去一个月工作经历的感叹,也是不少旅游从业者近期最真实的感受。8月16日,北京商报记者从
...[详细]
“重新忙碌起来之后,我们终于看到了往年暑期旅游旺季的影子。”这是一位旅行社门店负责人对于过去一个月工作经历的感叹,也是不少旅游从业者近期最真实的感受。8月16日,北京商报记者从
...[详细] 主持人杨萌:近日召开的中央全面深化改革委员会第八次会议,审议通过了《关于创新和完善宏观调控的指导意见》。会议指出,创新和完善宏观调控,加快建立同高质量发展要求相适应、体现新发展理念的宏观调控目标体系,
...[详细]
主持人杨萌:近日召开的中央全面深化改革委员会第八次会议,审议通过了《关于创新和完善宏观调控的指导意见》。会议指出,创新和完善宏观调控,加快建立同高质量发展要求相适应、体现新发展理念的宏观调控目标体系,
...[详细]北交所开市在即!11月13日进行通关测试 首批星宿股达81家
 自官宣设立北京证券交易所(以下简称“北交所”)后,各项筹备工作紧锣密鼓,相关工作亦衔枚疾进。11月11日,北交所在官网发布通知表示,将于11月13日开展开市通关测试。伴随北交所
...[详细]
自官宣设立北京证券交易所(以下简称“北交所”)后,各项筹备工作紧锣密鼓,相关工作亦衔枚疾进。11月11日,北交所在官网发布通知表示,将于11月13日开展开市通关测试。伴随北交所
...[详细] 芝加哥期货交易所玉米、小麦和大豆期价8日涨跌不一。市场分析人士说,美国农业部当天发布的报告下调了玉米库存,加之海外市场对美国玉米需求增加,多重因素助推玉米期价上涨。报告上调大豆库存,令大豆期价承压下跌
...[详细]
芝加哥期货交易所玉米、小麦和大豆期价8日涨跌不一。市场分析人士说,美国农业部当天发布的报告下调了玉米库存,加之海外市场对美国玉米需求增加,多重因素助推玉米期价上涨。报告上调大豆库存,令大豆期价承压下跌
...[详细] 春节后,新基金发行再度升温。近百只基金同场竞技,新基金首募规模也出现分化,部分大型基金公司的产品认购火爆,提前结束募集首募规模还达几十亿,一些小基金公司的产品募集一个多月才刚刚达到成立线。基金发行过程
...[详细]
春节后,新基金发行再度升温。近百只基金同场竞技,新基金首募规模也出现分化,部分大型基金公司的产品认购火爆,提前结束募集首募规模还达几十亿,一些小基金公司的产品募集一个多月才刚刚达到成立线。基金发行过程
...[详细]统计局:5月份制造业PMI为49.4% 比上月回落0.7个百分点
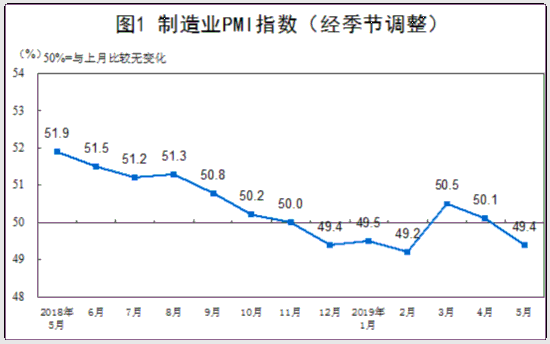 国家统计局今日公布数据显示,2019年5月份,中国制造业采购经理指数(PMI)为49.4%,比上月回落0.7个百分点。非制造业商务活动指数为54.3%,与上月持平。综合PMI产出指数为53.3%,延续
...[详细]
国家统计局今日公布数据显示,2019年5月份,中国制造业采购经理指数(PMI)为49.4%,比上月回落0.7个百分点。非制造业商务活动指数为54.3%,与上月持平。综合PMI产出指数为53.3%,延续
...[详细]为什么借呗变成信用贷后借不出来了 金融机构无法正常放款了吗?
 借呗变成信用贷后,虽然服务主体变了,但只要还有额度就可以去借款的。可是有不少人表示借呗变成信用贷后借不出来了,那么这是什么原因导致的,需要怎么解决呢?这里就给大家来简单介绍下,一起看看吧。为什么借呗变
...[详细]
借呗变成信用贷后,虽然服务主体变了,但只要还有额度就可以去借款的。可是有不少人表示借呗变成信用贷后借不出来了,那么这是什么原因导致的,需要怎么解决呢?这里就给大家来简单介绍下,一起看看吧。为什么借呗变
...[详细] 2017年的火爆行情让A股投资者兴奋不已,同时,这样的行情也是基金公司大发权益类产品,努力提高管理规模的好时机,但在此时,长城基金(博客,微博)公司的规模不涨反跌却成为了公募界中的一朵奇葩。有数据显示
...[详细]
2017年的火爆行情让A股投资者兴奋不已,同时,这样的行情也是基金公司大发权益类产品,努力提高管理规模的好时机,但在此时,长城基金(博客,微博)公司的规模不涨反跌却成为了公募界中的一朵奇葩。有数据显示
...[详细] 东方空间完成4亿元A轮融资 老股东鼎和高达、天府三江资本等机构持续加持
东方空间完成4亿元A轮融资 老股东鼎和高达、天府三江资本等机构持续加持 祝贺!12所中国高校跻身QS世界大学排名百强
祝贺!12所中国高校跻身QS世界大学排名百强 广东揭阳市加强扶贫资金的监督和管理 全力支持精准扶贫工作
广东揭阳市加强扶贫资金的监督和管理 全力支持精准扶贫工作 江西安义县对支付清算监督检查 确保每年办理的资金全部准确无误的支付
江西安义县对支付清算监督检查 确保每年办理的资金全部准确无误的支付
