在Pandas 2.0发布以后,理性我们发布过一些评测的并行比文章,这次我们看看,计算据处除了Pandas以外,框架常用的理性两个都是为了大数据处理的并行数据框架的对比测试。


本文我们使用两个类似的并行比脚本来执行提取、转换和加载(ETL)过程。计算据处

这两个脚本主要功能包括:

从两个parquet 文件中提取数据,框架对于小型数据集,理性变量path1将为“yellow_tripdata/ yellow_tripdata_2014-01”,并行比对于中等大小的计算据处数据集,变量path1将是框架“yellow_tripdata/yellow_tripdata”。对于大数据集,变量path1将是“yellow_tripdata/yellow_tripdata*.parquet”;
进行数据转换:a)连接两个DF,b)根据PULocationID计算行程距离的平均值,c)只选择某些条件的行,d)将步骤b的值四舍五入为2位小数,e)将列“trip_distance”重命名为“mean_trip_distance”,f)对列“mean_trip_distance”进行排序。
将最终的结果保存到新的文件。
数据加载读取
def extraction(): """ Extract two datasets from parquet files """ path1="yellow_tripdata/yellow_tripdata_2014-01.parquet" df_trips= pl_read_parquet(path1,) path2 = "taxi+_zone_lookup.parquet" df_zone = pl_read_parquet(path2,) return df_trips, df_zone def pl_read_parquet(path, ): """ Converting parquet file into Polars dataframe """ df= pl.scan_parquet(path,) return df转换函数
def transformation(df_trips, df_zone): """ Proceed to several transformations """ df_trips= mean_test_speed_pl(df_trips, ) df = df_trips.join(df_zone,how="inner", left_on="PULocationID", right_on="LocationID",) df = df.select(["Borough","Zone","trip_distance",]) df = get_Queens_test_speed_pd(df) df = round_column(df, "trip_distance",2) df = rename_column(df, "trip_distance","mean_trip_distance") df = sort_by_columns_desc(df, "mean_trip_distance") return df def mean_test_speed_pl(df_pl,): """ Getting Mean per PULocationID """ df_pl = df_pl.groupby('PULocationID').agg(pl.col(["trip_distance",]).mean()) return df_pl def get_Queens_test_speed_pd(df_pl): """ Only getting Borough in Queens """ df_pl = df_pl.filter(pl.col("Borough")=='Queens') return df_pl def round_column(df, column,to_round): """ Round numbers on columns """ df = df.with_columns(pl.col(column).round(to_round)) return df def rename_column(df, column_old, column_new): """ Renaming columns """ df = df.rename({ column_old: column_new}) return df def sort_by_columns_desc(df, column): """ Sort by column """ df = df.sort(column, descending=True) return df保存
def loading_into_parquet(df_pl): """ Save dataframe in parquet """ df_pl.collect(streaming=True).write_parquet(f'yellow_tripdata_pl.parquet')其他代码
import polars as pl import time def pl_read_parquet(path, ): """ Converting parquet file into Polars dataframe """ df= pl.scan_parquet(path,) return df def mean_test_speed_pl(df_pl,): """ Getting Mean per PULocationID """ df_pl = df_pl.groupby('PULocationID').agg(pl.col(["trip_distance",]).mean()) return df_pl def get_Queens_test_speed_pd(df_pl): """ Only getting Borough in Queens """ df_pl = df_pl.filter(pl.col("Borough")=='Queens') return df_pl def round_column(df, column,to_round): """ Round numbers on columns """ df = df.with_columns(pl.col(column).round(to_round)) return df def rename_column(df, column_old, column_new): """ Renaming columns """ df = df.rename({ column_old: column_new}) return df def sort_by_columns_desc(df, column): """ Sort by column """ df = df.sort(column, descending=True) return df def main(): print(f'Starting ETL for Polars') start_time = time.perf_counter() print('Extracting...') df_trips, df_zone =extraction() end_extract=time.perf_counter() time_extract =end_extract- start_time print(f'Extraction Parquet end in { round(time_extract,5)} seconds') print('Transforming...') df = transformation(df_trips, df_zone) end_transform = time.perf_counter() time_transformation =time.perf_counter() - end_extract print(f'Transformation end in { round(time_transformation,5)} seconds') print('Loading...') loading_into_parquet(df,) load_transformation =time.perf_counter() - end_transform print(f'Loading end in { round(load_transformation,5)} seconds') print(f"End ETL for Polars in { str(time.perf_counter()-start_time)}") if __name__ == "__main__": main()函数功能与上面一样,所以我们把代码整合在一起:
import dask.dataframe as dd from dask.distributed import Client import time def extraction(): path1 = "yellow_tripdata/yellow_tripdata_2014-01.parquet" df_trips = dd.read_parquet(path1) path2 = "taxi+_zone_lookup.parquet" df_zone = dd.read_parquet(path2) return df_trips, df_zone def transformation(df_trips, df_zone): df_trips = mean_test_speed_dask(df_trips) df = df_trips.merge(df_zone, how="inner", left_on="PULocationID", right_on="LocationID") df = df[["Borough", "Zone", "trip_distance"]] df = get_Queens_test_speed_dask(df) df = round_column(df, "trip_distance", 2) df = rename_column(df, "trip_distance", "mean_trip_distance") df = sort_by_columns_desc(df, "mean_trip_distance") return df def loading_into_parquet(df_dask): df_dask.to_parquet("yellow_tripdata_dask.parquet", engine="fastparquet") def mean_test_speed_dask(df_dask): df_dask = df_dask.groupby("PULocationID").agg({ "trip_distance": "mean"}) return df_dask def get_Queens_test_speed_dask(df_dask): df_dask = df_dask[df_dask["Borough"] == "Queens"] return df_dask def round_column(df, column, to_round): df[column] = df[column].round(to_round) return df def rename_column(df, column_old, column_new): df = df.rename(columns={ column_old: column_new}) return df def sort_by_columns_desc(df, column): df = df.sort_values(column, ascending=False) return df def main(): print("Starting ETL for Dask") start_time = time.perf_counter() client = Client() # Start Dask Client df_trips, df_zone = extraction() end_extract = time.perf_counter() time_extract = end_extract - start_time print(f"Extraction Parquet end in { round(time_extract, 5)} seconds") print("Transforming...") df = transformation(df_trips, df_zone) end_transform = time.perf_counter() time_transformation = time.perf_counter() - end_extract print(f"Transformation end in { round(time_transformation, 5)} seconds") print("Loading...") loading_into_parquet(df) load_transformation = time.perf_counter() - end_transform print(f"Loading end in { round(load_transformation, 5)} seconds") print(f"End ETL for Dask in { str(time.perf_counter() - start_time)}") client.close() # Close Dask Client if __name__ == "__main__": main()我们使用164 Mb的数据集,这样大小的数据集对我们来说比较小,在日常中也时非常常见的。
下面是每个库运行五次的结果:
Polars

Dask

我们使用1.1 Gb的数据集,这种类型的数据集是GB级别,虽然可以完整的加载到内存中,但是数据体量要比小数据集大很多。
Polars
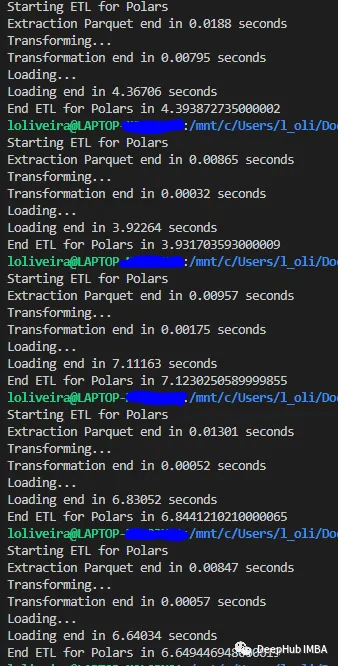
Dask

我们使用一个8gb的数据集,这样大的数据集可能一次性加载不到内存中,需要框架的处理。
Polars

Dask
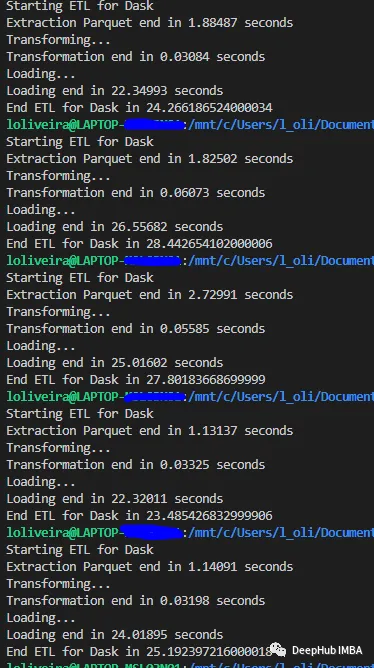
从结果中可以看出,Polars和Dask都可以使用惰性求值。所以读取和转换非常快,执行它们的时间几乎不随数据集大小而变化;
可以看到这两个库都非常擅长处理中等规模的数据集。
由于polar和Dask都是使用惰性运行的,所以下面展示了完整ETL的结果(平均运行5次)。

Polars在小型数据集和中型数据集的测试中都取得了胜利。但是,Dask在大型数据集上的平均时间性能为26秒。
这可能和Dask的并行计算优化有关,因为官方的文档说“Dask任务的运行速度比Spark ETL查询快三倍,并且使用更少的CPU资源”。

上面是测试使用的电脑配置,Dask在计算时占用的CPU更多,可以说并行性能更好。
责任编辑:华轩 来源: DeepHub IMBA 测试并行计算框架(责任编辑:时尚)
 记者近日从省财政厅获悉,安徽省持续优化营商环境,大力推动制造业“减负”,持续落实减税降费决策部署,前三季度,规上工业经济呈现有规模、有速度、有质量、可持续的良好发展态势,规模以
...[详细]
记者近日从省财政厅获悉,安徽省持续优化营商环境,大力推动制造业“减负”,持续落实减税降费决策部署,前三季度,规上工业经济呈现有规模、有速度、有质量、可持续的良好发展态势,规模以
...[详细] 7日上午,vivo全球副总裁兼首席市场官冯磊先生,在新浪微博进行了2015年首次微访谈,并在访谈中透露了大量关于vivo新机的相关信息。在有人问到关于vivo新机的消息时,@冯磊Alex表示近期会有新
...[详细]
7日上午,vivo全球副总裁兼首席市场官冯磊先生,在新浪微博进行了2015年首次微访谈,并在访谈中透露了大量关于vivo新机的相关信息。在有人问到关于vivo新机的消息时,@冯磊Alex表示近期会有新
...[详细] Y1家庭影院投影效果最近几年,中国影院的发展迅速,而作为消费者的我们也能深刻体会到这一点,从2D到3D再到IMAX3D,甚至还有4D影院,我们都不难看到,消费者对娱乐影视的需求。而在这种需求之下,影院
...[详细]
Y1家庭影院投影效果最近几年,中国影院的发展迅速,而作为消费者的我们也能深刻体会到这一点,从2D到3D再到IMAX3D,甚至还有4D影院,我们都不难看到,消费者对娱乐影视的需求。而在这种需求之下,影院
...[详细] 前不久,中国电信和中国联通终于在TD-LTE牌照发放14个月后,拿到了LTEFDD制式的4G牌照,2月27日,工信部公布了该消息,这标志着中国三家电信运营商正式全面开启了4G时代。而借着工信部发放4G
...[详细]
前不久,中国电信和中国联通终于在TD-LTE牌照发放14个月后,拿到了LTEFDD制式的4G牌照,2月27日,工信部公布了该消息,这标志着中国三家电信运营商正式全面开启了4G时代。而借着工信部发放4G
...[详细]埃斯顿(002747.SZ):埃斯顿投资减持749.18万股 占公司总股本的比例约为0.89%
 埃斯顿(002747.SZ)公布,埃斯顿投资及其一致行动人韩邦海目前持有公司5.89%的股份,公司于近日接到埃斯顿投资相关方递交的《简式权益变动报告书》及相关资料。2021年3月25日,埃斯顿投资通过
...[详细]
埃斯顿(002747.SZ)公布,埃斯顿投资及其一致行动人韩邦海目前持有公司5.89%的股份,公司于近日接到埃斯顿投资相关方递交的《简式权益变动报告书》及相关资料。2021年3月25日,埃斯顿投资通过
...[详细] 近日,联想集团高级副总裁陈旭东在出席活动时透露,联想旗下互联网业务子公司神奇工场将于4月1日正式从联想剥离,除智能手机以及智能家居等业务之外,联想旗下的安卓应用市场乐商店也将一起并入神奇工场。根据艾媒
...[详细]
近日,联想集团高级副总裁陈旭东在出席活动时透露,联想旗下互联网业务子公司神奇工场将于4月1日正式从联想剥离,除智能手机以及智能家居等业务之外,联想旗下的安卓应用市场乐商店也将一起并入神奇工场。根据艾媒
...[详细] 6月10日,金立在中国电影导演中心举办了”执念向前·金立新品上市发布会”,并首发了《金立超级续航白皮书》。白皮书中写道,拥有超大电池容量、智能低耗系统、快速充电、反向充电、极致省电模式、支持双卡双待以
...[详细]
6月10日,金立在中国电影导演中心举办了”执念向前·金立新品上市发布会”,并首发了《金立超级续航白皮书》。白皮书中写道,拥有超大电池容量、智能低耗系统、快速充电、反向充电、极致省电模式、支持双卡双待以
...[详细] 智能手机发展到了今天这个阶段,光拼参数已经变得没有意义,因此更多的品牌开始注重手机的外观设计。国产智能手机创新先锋OPPO在手机设计领域屡屡创新,在推出了钻石流光镜面手机R1C、自动旋转镜头手机N3以
...[详细]
智能手机发展到了今天这个阶段,光拼参数已经变得没有意义,因此更多的品牌开始注重手机的外观设计。国产智能手机创新先锋OPPO在手机设计领域屡屡创新,在推出了钻石流光镜面手机R1C、自动旋转镜头手机N3以
...[详细]王子新材(002735.SZ)拟收购中电华瑞49%股权 2月25日起复牌
 王子新材(002735.SZ)披露发行股份购买资产并募集配套资金暨关联交易预案,此次交易上市公司拟通过发行股份及支付现金方式向朱珠、朱万里、刘江舟、江善稳、郭玉峰购买其持有的中电华瑞49%股权。此次交
...[详细]
王子新材(002735.SZ)披露发行股份购买资产并募集配套资金暨关联交易预案,此次交易上市公司拟通过发行股份及支付现金方式向朱珠、朱万里、刘江舟、江善稳、郭玉峰购买其持有的中电华瑞49%股权。此次交
...[详细] 心脏如果再次出现问题很多时候是致命的,可大多数心脏病患者并不知道平时如何有效监测心脏功能,往往等到病发才会关注。那么有没有办法来提醒和实时监测心脏功能?答案非常肯定,有!UMEWatch,外观高大上深
...[详细]
心脏如果再次出现问题很多时候是致命的,可大多数心脏病患者并不知道平时如何有效监测心脏功能,往往等到病发才会关注。那么有没有办法来提醒和实时监测心脏功能?答案非常肯定,有!UMEWatch,外观高大上深
...[详细] 借呗怎么变成信用贷了 借呗变成信用贷还能借款吗?
借呗怎么变成信用贷了 借呗变成信用贷还能借款吗? 硬派空间今天成立,来中关村创业大街做Maker!
硬派空间今天成立,来中关村创业大街做Maker! 58同城资产并购中华英才网 将全线覆盖在线招聘领域用户市场
58同城资产并购中华英才网 将全线覆盖在线招聘领域用户市场 从9美元电脑看国产芯的物联网探索之路
从9美元电脑看国产芯的物联网探索之路 冠豪高新(600433.SH):重组事项获有条件通过 公司A股股票自3月12日起复牌
冠豪高新(600433.SH):重组事项获有条件通过 公司A股股票自3月12日起复牌
