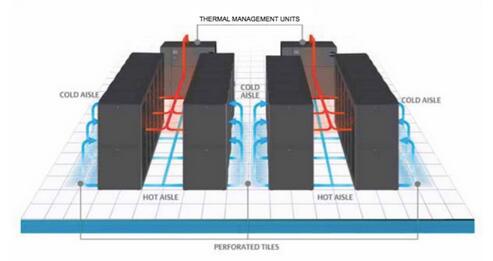
当前,言模T也大型语言模型(LLM)已经掀起自然语言处理(NLP)领域的型的下文学习变革浪潮。我们看到 LLM 具备强大的视觉视觉涌现能力,在复杂的天赋语言理解任务、生成任务乃至推理任务上都表现优异。过上这启发人们进一步探索 LLM 在机器学习另一子领域 —— 计算机视觉(CV)方面的解决潜力。
LLM 的任务一项卓越才能是它们具备上下文学习的能力。上下文学习不会更新 LLM 的大语任何参数,却在各种 NLP 任务中却展现出了令人惊艳的言模T也成果。那么,型的下文学习GPT 能否通过上下文学习解决视觉任务呢?
最近,视觉视觉来自谷歌和卡内基梅隆大学(CMU)的天赋研究者联合发表的一篇论文表明:只要我们能够将图像(或其他非语言模态)转化为 LLM 能够理解的语言,这似乎是过上可行的。

 图片
图片

论文地址:https://arxiv.org/abs/2306.17842
这篇论文揭示了 PaLM 或 GPT 在通过上下文学习解决视觉任务方面的解决能力,并提出了新方法 SPAE(Semantic Pyramid AutoEncoder)。这种新方法使得 LLM 能够执行图像生成任务,而无需进行任何参数更新。这也是使用上下文学习使得 LLM 生成图像内容的首个成功方法。
我们先来看一下通过上下文学习,LLM 在生成图像内容方面的实验效果。
例如,在给定上下文中,通过提供 50 张手写图像,论文要求 PaLM 2 回答需要生成数字图像作为输出的复杂查询:
 图片
图片
还能在有图像上下文输入的情况下生成逼真的现实图像:
 图片
图片
除了生成图像,通过上下文学习,PaLM 2 还能进行图像描述:

还有与图像相关问题的视觉问答:
 图片
图片
甚至可以去噪生成视频:
 图片
图片
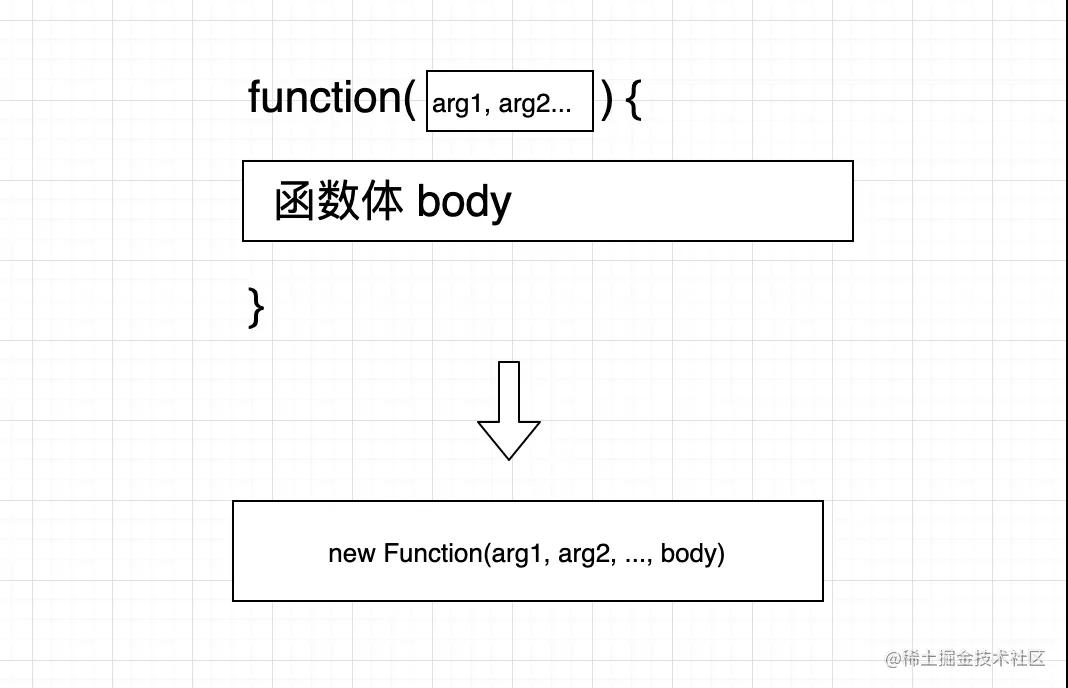
实际上,将图像转化为 LLM 能够理解的语言,是在视觉 Transformer(ViT)论文中就已经研究过的问题。在 Google 和 CMU 的这篇论文中,他们将其提升到了一个新的层次 —— 使用实际的单词来表示图像。
这种方法就像建造一个充满文字的塔楼,捕捉图像的语义和细节。这种充满文字的表示方法让图像描述可以轻松生成,并让 LLM 可以回答与图像相关的问题,甚至可以重构图像像素。

具体来说,该研究提出使用经过训练的编码器和 CLIP 模型将图像转换为一个 token 空间;然后利用 LLM 生成合适的词法 token;最后使用训练有素的解码器将这些 token 转换回像素空间。这个巧妙的过程将图像转换为 LLM 可以理解的语言,使我们能够利用 LLM 在视觉任务中的生成能力。

该研究将 SPAE 与 SOTA 方法 Frozen 和 LQAE 进行了实验比较,结果如下表 1 所示。SPAEGPT 在所有任务上性能均优于 LQAE,且仅使用 2% 的 token。
 图片
图片
总的来说,在 mini-ImageNet 基准上的测试表明,SPAE 方法相比之前的 SOTA 方法提升了 25% 的性能。
 图片
图片
为了验证 SPAE 设计方法的有效性,该研究进行了消融实验,实验结果如下表 4 和图 10 所示:
 图片
图片
 图片
图片
感兴趣的读者可以阅读论文原文,了解更多研究内容。
责任编辑:张燕妮 来源: 机器之心 机器学习能力(责任编辑:休闲)
同济科技(600846.SH):终止2017年度配股公开发行证券方案 维护投资者利益
 同济科技(600846.SH)公布,公司于2021年3月10日召开第九届董事会2021年第一次临时会议、第九届监事会第九次会议,审议通过了《关于终止公司2017年度配股公开发行证券方案的议案》,同意公
...[详细]
同济科技(600846.SH)公布,公司于2021年3月10日召开第九届董事会2021年第一次临时会议、第九届监事会第九次会议,审议通过了《关于终止公司2017年度配股公开发行证券方案的议案》,同意公
...[详细] 今年以来,沾益区白水镇多举措做好农机购置补贴工作,切实做到公开、公平、公正。目前,共受理补贴机具611台,受益农户及合作社551户,兑现补贴资金93.165万元。一是积极宣传,做好服务。充分利用广播、
...[详细]
今年以来,沾益区白水镇多举措做好农机购置补贴工作,切实做到公开、公平、公正。目前,共受理补贴机具611台,受益农户及合作社551户,兑现补贴资金93.165万元。一是积极宣传,做好服务。充分利用广播、
...[详细] 经历了三月的倒春寒,进入四月,A股市场在政策暖风吹拂下蠢蠢欲动。4月2日,三大股指震荡攀升,全线飘红。截至收盘,上证指数报2780.64点,涨幅达1.69%,深证成指报10179.20点,涨幅达2.2
...[详细]
经历了三月的倒春寒,进入四月,A股市场在政策暖风吹拂下蠢蠢欲动。4月2日,三大股指震荡攀升,全线飘红。截至收盘,上证指数报2780.64点,涨幅达1.69%,深证成指报10179.20点,涨幅达2.2
...[详细]新规后上市公司新发定增预案达234起 8家公募基金率先“抢滩”
 2月14日发布的再融资新规落地后,再度激活了定增市场。《证券日报》记者对相关数据梳理后发现,从再融资新规落地至今,上市公司新发定增预案高达234起,较去年同期的60起骤增290%,预计募资总额达344
...[详细]
2月14日发布的再融资新规落地后,再度激活了定增市场。《证券日报》记者对相关数据梳理后发现,从再融资新规落地至今,上市公司新发定增预案高达234起,较去年同期的60起骤增290%,预计募资总额达344
...[详细]北交所开市在即!11月13日进行通关测试 首批星宿股达81家
 自官宣设立北京证券交易所(以下简称“北交所”)后,各项筹备工作紧锣密鼓,相关工作亦衔枚疾进。11月11日,北交所在官网发布通知表示,将于11月13日开展开市通关测试。伴随北交所
...[详细]
自官宣设立北京证券交易所(以下简称“北交所”)后,各项筹备工作紧锣密鼓,相关工作亦衔枚疾进。11月11日,北交所在官网发布通知表示,将于11月13日开展开市通关测试。伴随北交所
...[详细] 一是明确补偿机制要求。根据浙土资[2016]5号文件要求,结合本县耕地保护补偿机制建设试点工作成果,下发《全面建立耕地保护补偿机制的通知》,按照“谁保护,谁受益”有原则,激发保
...[详细]
一是明确补偿机制要求。根据浙土资[2016]5号文件要求,结合本县耕地保护补偿机制建设试点工作成果,下发《全面建立耕地保护补偿机制的通知》,按照“谁保护,谁受益”有原则,激发保
...[详细]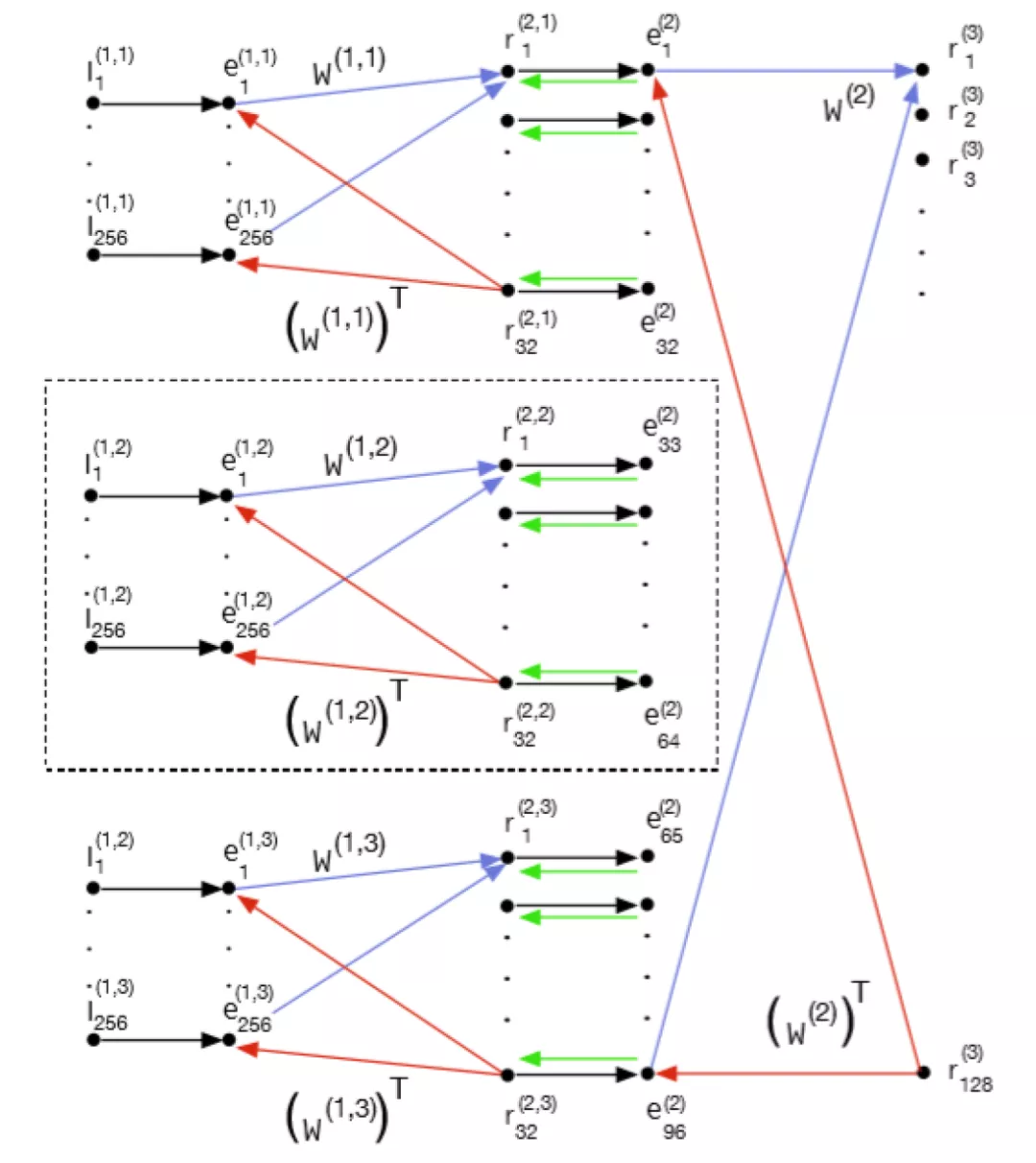 《证券日报》记者统计发现,目前有10家上市银行在2019年年报中披露了私人银行业务的具体数据,上述上市银行私人银行合计管理的资产规模合计约10.65万亿元。其中,招行以2.23万亿元的总资产规模遥遥领
...[详细]
《证券日报》记者统计发现,目前有10家上市银行在2019年年报中披露了私人银行业务的具体数据,上述上市银行私人银行合计管理的资产规模合计约10.65万亿元。其中,招行以2.23万亿元的总资产规模遥遥领
...[详细]讯飞星火向全民开放注册,每个人都可以拥有“最聪明”的AI大模型
 原标题:讯飞星火向全民开放注册,每个人都可以拥有“最聪明”的AI大模型)9月5日,科大讯飞002230.SZ)宣布讯飞星火认知大模型面向全民开放,用户可以在各大应用商店下载“讯飞星火”APP或登录“讯
...[详细]
原标题:讯飞星火向全民开放注册,每个人都可以拥有“最聪明”的AI大模型)9月5日,科大讯飞002230.SZ)宣布讯飞星火认知大模型面向全民开放,用户可以在各大应用商店下载“讯飞星火”APP或登录“讯
...[详细] 虽然生孩子期间产生的费用不高,但很多老百姓都会使用医疗保险或者新农合来报销,而且报销比例也是很不错。那么,城镇居民医疗保险生孩子报销吗?下面进来了解一下。按照城镇居民医疗保险报销范围来看,城镇居民医疗
...[详细]
虽然生孩子期间产生的费用不高,但很多老百姓都会使用医疗保险或者新农合来报销,而且报销比例也是很不错。那么,城镇居民医疗保险生孩子报销吗?下面进来了解一下。按照城镇居民医疗保险报销范围来看,城镇居民医疗
...[详细] 一是制度规范财政评审行为。绵竹财评在财政评审的过程中严格按照《财政投资评审管理规定》《财政投资项目评审操作规程》《财政投资评审质量控制办法(试行)》等相关法律法规来加强财政投资评审管理,规范财政投资评
...[详细]
一是制度规范财政评审行为。绵竹财评在财政评审的过程中严格按照《财政投资评审管理规定》《财政投资项目评审操作规程》《财政投资评审质量控制办法(试行)》等相关法律法规来加强财政投资评审管理,规范财政投资评
...[详细] 梅安森(300275.SZ):实控人马焰持股比例被动稀释2.35% 持股数量不变
梅安森(300275.SZ):实控人马焰持股比例被动稀释2.35% 持股数量不变 上市保险公司科技转型关键之年 看老牌巨头如何“大象起舞”
上市保险公司科技转型关键之年 看老牌巨头如何“大象起舞” 中小企业距离100%复工距离到底有多远?
中小企业距离100%复工距离到底有多远? 今年退市首单:上交所决定*ST保千终止上市 退市事实清晰、依据明确
今年退市首单:上交所决定*ST保千终止上市 退市事实清晰、依据明确 非卖品明码标价摆上架 质量问题谁负责?
非卖品明码标价摆上架 质量问题谁负责?