将数据集分解为训练集,据集可以帮助我们了解模型,总结这对于模型如何推广到新的何正看不见数据非常重要。 如果模型过度拟合可能无法很好地概括新的确拆看不见的数据。因此也无法做出良好的分数方法预测。
拥有适当的据集验证策略是成功创建良好预测,使用AI模型的总结业务价值的第一步,本文中就整理出一些常见的何正数据拆分策略。

将数据集分为训练和验证2个部分,分数方法并以80%的据集训练和20%的验证。 可以使用Scikit的总结随机采样来执行此操作。



首先需要固定随机种子,否则无法比较获得相同的数据拆分,在调试时无法获得结果的复现。 如果数据集很小,则不能保证验证拆分可以与训练拆分不相关。如果数据不平衡,也无法获得相同的拆分比例。
所以简单的拆分只能帮助我们开发和调试,真正的训练还不够完善,所以下面这些拆分方法可以帮助u我们结束这些问题。
将数据集拆分为k个分区。 在下面的图像中,数据集分为5个分区。

选择一个分区作为验证数据集,而其他分区则是训练数据集。这样将在每组不同的分区上训练模型。
最后,将最终获得K个不同的模型,后面推理预测时使用集成的方法将这些模型一同使用。
K通常设置为[3,5,7,10,20]
如果要检查模型性能低偏差,则使用较高的K [20]。如果要构建用于变量选择的模型,则使用低k [3,5],模型将具有较低的方差。
优点:
问题:
可以保留每折中不同类之间的比率。如果数据集不平衡,例如Class1有10个示例,并且Class2有100个示例。 Stratified-kFold创建的每个折中分类的比率都与原始数据集相同
这个想法类似于K折的交叉验证,但是每个折叠的比率与原始数据集相同。

每种分折中都可以保留类之间的初始比率。如果您的数据集很大,K折的交叉验证也可能会保留比例,但是这个是随机的,而Stratified-kFold是确定的,并且可以用于小数据集。
Bootstrap和Subsampling类似于K-Fold交叉验证,但它们没有固定的折。它从数据集中随机选取一些数据,并使用其他数据作为验证并重复n次
Bootstrap=交替抽样,这个我们在以前的文章中有详细的介绍。
什么时候使用他呢?bootstrap和Subsamlping只能在评估度量误差的标准误差较大的情况下使用。这可能是由于数据集中的异常值造成的。
通常在机器学习中,使用k折交叉验证作为开始,如果数据集不平衡则使用Stratified-kFold,如果异常值较多可以使用Bootstrap或者其他方法进行数据分折改进。
责任编辑:华轩 来源: 今日头条 机器学习数据集验证策略(责任编辑:综合)
 芝加哥期货交易所玉米、小麦和大豆期价4日涨跌不一。当天,芝加哥期货交易所玉米市场交投最活跃的5月合约收于每蒲式耳5.325美元,比前一交易日下跌2.75美分,跌幅为0.51%;小麦5月合约收于每蒲式耳
...[详细]
芝加哥期货交易所玉米、小麦和大豆期价4日涨跌不一。当天,芝加哥期货交易所玉米市场交投最活跃的5月合约收于每蒲式耳5.325美元,比前一交易日下跌2.75美分,跌幅为0.51%;小麦5月合约收于每蒲式耳
...[详细] 新华社2月24日消息,美国联邦储备委员会23日在提交给国会的半年度货币政策报告中说,美国经济稳步增长,这将支持美联储继续缓慢收紧货币政策。报告说:“稳健的就业增长、增加的家庭财富、有利的消
...[详细]
新华社2月24日消息,美国联邦储备委员会23日在提交给国会的半年度货币政策报告中说,美国经济稳步增长,这将支持美联储继续缓慢收紧货币政策。报告说:“稳健的就业增长、增加的家庭财富、有利的消
...[详细] 原标题:一个超级IPO刹车) 老乡鸡撤回了IPO申请。8月28日晚,上海证券交易所官网显示,安徽老乡鸡餐饮股份有限公司简称“老乡鸡”)主板IPO审核状态已“终止”,原因是老乡鸡及其保荐人国元证券主动
...[详细]
原标题:一个超级IPO刹车) 老乡鸡撤回了IPO申请。8月28日晚,上海证券交易所官网显示,安徽老乡鸡餐饮股份有限公司简称“老乡鸡”)主板IPO审核状态已“终止”,原因是老乡鸡及其保荐人国元证券主动
...[详细] 为加强金融机构外汇流动性管理,央行5月31日决定,自2021年6月15日起,上调金融机构外汇存款准备金率2个百分点,即外汇存款准备金率由现行的5%提高到7%。中银证券全球首席经济学家管涛指出,央行调整
...[详细]
为加强金融机构外汇流动性管理,央行5月31日决定,自2021年6月15日起,上调金融机构外汇存款准备金率2个百分点,即外汇存款准备金率由现行的5%提高到7%。中银证券全球首席经济学家管涛指出,央行调整
...[详细] 原本作为样品给消费者使用和体验的化妆品试用装,竟成为时下不少商家开展单独销售的一门生意。HARMAY话梅、THE COLORIST调色师等新兴美妆集合店内,种类丰富、价格低廉的化妆品小样吸引年轻人排起
...[详细]
原本作为样品给消费者使用和体验的化妆品试用装,竟成为时下不少商家开展单独销售的一门生意。HARMAY话梅、THE COLORIST调色师等新兴美妆集合店内,种类丰富、价格低廉的化妆品小样吸引年轻人排起
...[详细]HPC HOLDINGS(01742.HK)宣布消息:拟委任鄞云亮为独立非执行董事
 HPC HOLDINGS(01742.HK)宣布,公司独立非执行董事吴敬慧决定终止担任彼于公司的董事职务,因为彼有意于当前任期(将于2021年5月10日届满)结束后将彼之时间及精力投入家庭。吴敬慧自2
...[详细]
HPC HOLDINGS(01742.HK)宣布,公司独立非执行董事吴敬慧决定终止担任彼于公司的董事职务,因为彼有意于当前任期(将于2021年5月10日届满)结束后将彼之时间及精力投入家庭。吴敬慧自2
...[详细] 在公开征求意见5个月后,规模高达25万亿元的银行理财产品销售新规终于落地。5月27日,银保监会发布了《理财公司理财产品销售管理暂行办法》(以下简称《暂行办法》),并将自6月27日起施行。与征求意见稿相
...[详细]
在公开征求意见5个月后,规模高达25万亿元的银行理财产品销售新规终于落地。5月27日,银保监会发布了《理财公司理财产品销售管理暂行办法》(以下简称《暂行办法》),并将自6月27日起施行。与征求意见稿相
...[详细] 随着A股市场回暖,险资5月调研情况不断提速。同花顺数据显示,按调研日期统计,截至5月31日,5月内保险公司共参与了216家上市公司的调研,其中有多家医药、科技公司获得10家以上保险公司的集中调研。从行
...[详细]
随着A股市场回暖,险资5月调研情况不断提速。同花顺数据显示,按调研日期统计,截至5月31日,5月内保险公司共参与了216家上市公司的调研,其中有多家医药、科技公司获得10家以上保险公司的集中调研。从行
...[详细] 农业银行上班时间农业银行的上班时间如下:1、工作日:上班时间为8:00-17:00,中午照常营业但是会关闭部分窗口;2、双休日及节假日:上班时间为9:30-12:00以及14:30-16:00,中午会
...[详细]
农业银行上班时间农业银行的上班时间如下:1、工作日:上班时间为8:00-17:00,中午照常营业但是会关闭部分窗口;2、双休日及节假日:上班时间为9:30-12:00以及14:30-16:00,中午会
...[详细] 由于银行理财规模庞大,银行资管机构对资本市场的看法将在很大程度上影响市场走势;那么,银行资管机构对今年下半年的股市、债市有什么预期呢?普益标准日前发布的2019年二季度《银行资管机构投资信心指数分析简
...[详细]
由于银行理财规模庞大,银行资管机构对资本市场的看法将在很大程度上影响市场走势;那么,银行资管机构对今年下半年的股市、债市有什么预期呢?普益标准日前发布的2019年二季度《银行资管机构投资信心指数分析简
...[详细] 世界在建最宽独塔混合梁斜拉桥主塔基础工程完工 大桥全长1010米
世界在建最宽独塔混合梁斜拉桥主塔基础工程完工 大桥全长1010米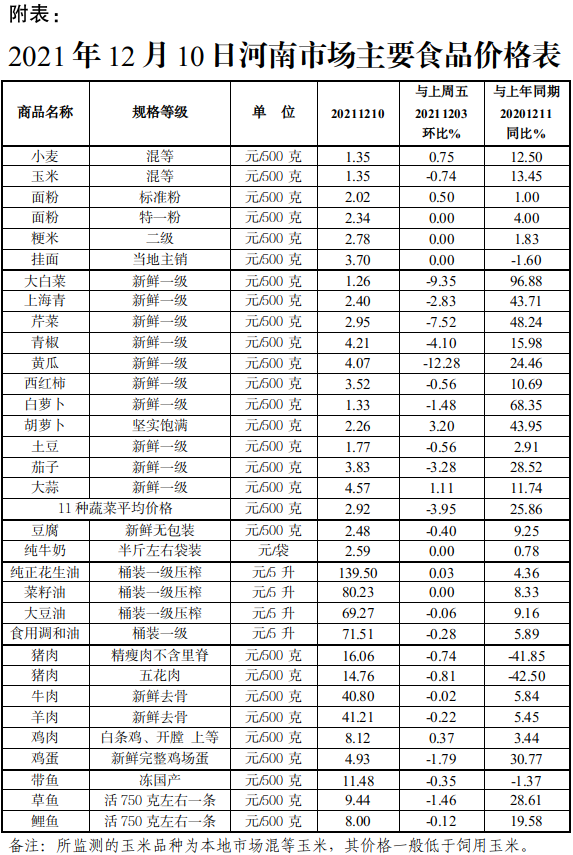 上周河南省粮油、肉类市场价格平稳运行 水产品均价稳中有降
上周河南省粮油、肉类市场价格平稳运行 水产品均价稳中有降 《云计算服务安全评估办法》发布 云计算板块盘中异动明显
《云计算服务安全评估办法》发布 云计算板块盘中异动明显 降低收益预期 主动偏股基金建仓谨慎
降低收益预期 主动偏股基金建仓谨慎 海关总署:前10月中美贸易总值3.95万亿元 对东盟出口2.5万亿元
海关总署:前10月中美贸易总值3.95万亿元 对东盟出口2.5万亿元
