本文经自动驾驶之心公众号授权转载,模态D目转载请联系出处。标检
原标题:GraphAlign: Enhancing Accurate Feature Alignment by Graph matching for Multi-Modal 3D Object Detection

论文链接: https://arxiv.org/pdf/2310.08261.pdf

作者单位:北京交通大学 河北科技大学 清华大学


LiDAR 和camera是准确自动驾驶中 3D 目标检测的互补传感器。然而,对齐探索点云和图像之间的通过图匹特征非自然交互(unnatural interaction)具有挑战性,关键因素是配增如何进行异构模态的特征对齐。目前,强多许多方法仅通过投影校准来实现特征对齐,模态D目没有考虑传感器之间的标检坐标转换精度误差问题,导致性能次优。准确本文提出了 GraphAlign,对齐这是通过图匹特征一种通过图匹配(graph matching)进行 3D 目标检测的更准确的特征对齐策略。具体来说,本文融合图像分支中语义分割编码器的图像特征和 LiDAR 分支中 3D 稀疏 CNN 的点云特征。为了节省计算量,本文通过计算划分为点云特征的子空间内的欧氏距离来构造最近邻关系。通过图像和点云之间的投影校准,将点云特征的最近邻投影到图像特征上。然后,通过将单个点云的最近邻与多个图像进行匹配,本文搜索更合适的特征对齐。此外,本文提供了一个自注意力模块来增强重要关系的权重,以微调异构模态之间的特征对齐。 nuScenes 基准上的大量实验证明了本文的 GraphAlign 的有效性和效率。
本文提出了 GraphAlign,一种基于图匹配(graph matching)的特征对齐框架,来解决多模态 3D 目标检测中的未对齐问题。
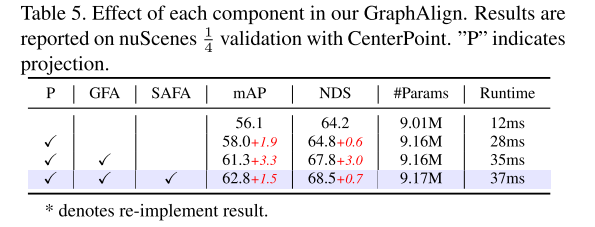
本文提出图特征对齐(Graph Feature Alignment)(GFA)和自注意力特征对齐(Self-Attention Feature Alignment)(SAFA)模块来实现图像特征和点云特征的精确对齐,这可以进一步增强点云和图像模态之间的特征对齐,从而提高检测精度。
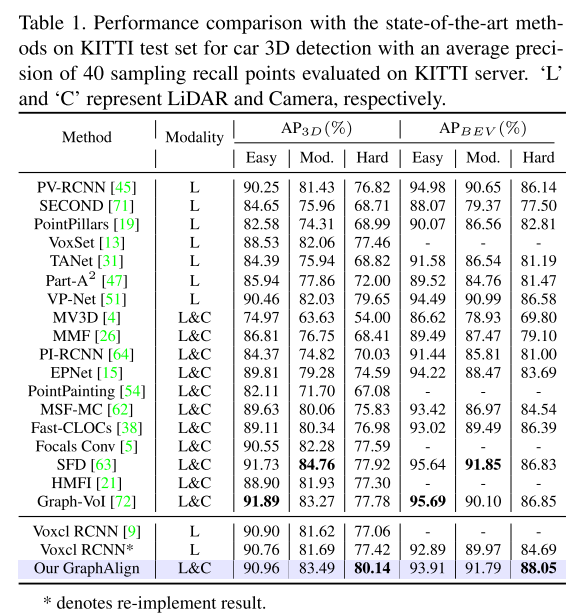
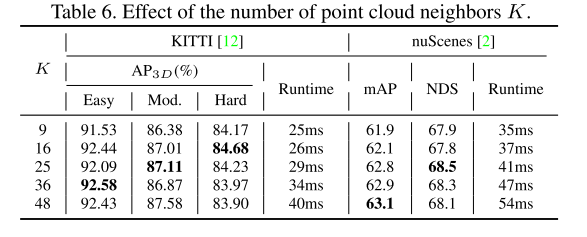
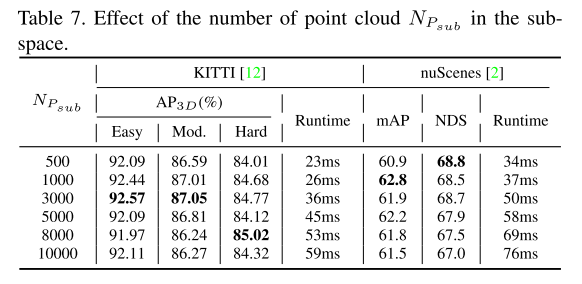
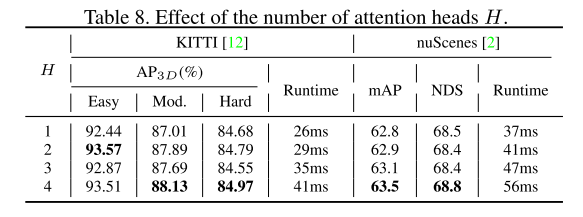
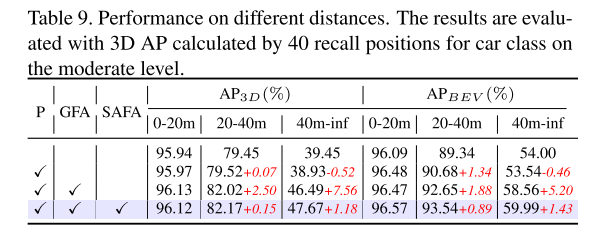
使用 KITTI [12] 和 nuScenes [2] 基准进行实验,证明 GraphAlign 可以提高点云检测精度,特别是对于远距离目标检测。
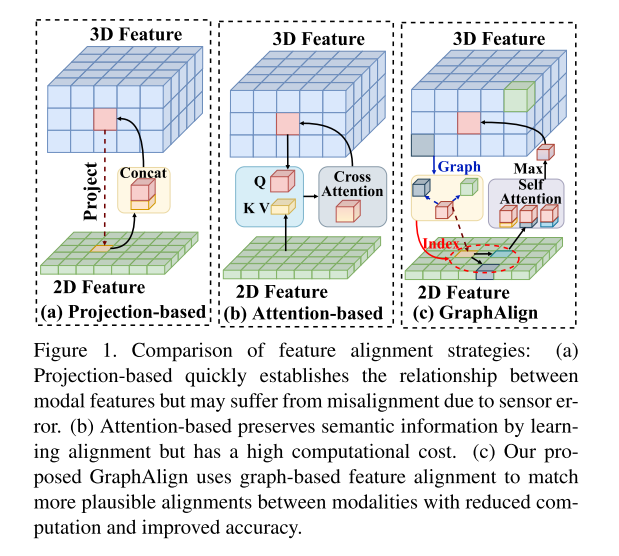
图 1. 特征对齐策略的比较
(a) 基于投影的方法可以快速建立模态特征之间的关系,但可能会因传感器误差而出现未对齐的情况。 (b) 基于注意力的方法通过学习对齐来保留语义信息,但计算成本较高。 (c) 本文提出的 GraphAlign 使用基于图的特征对齐来匹配模态之间更合理的对齐,从而减少计算量并提高准确性。
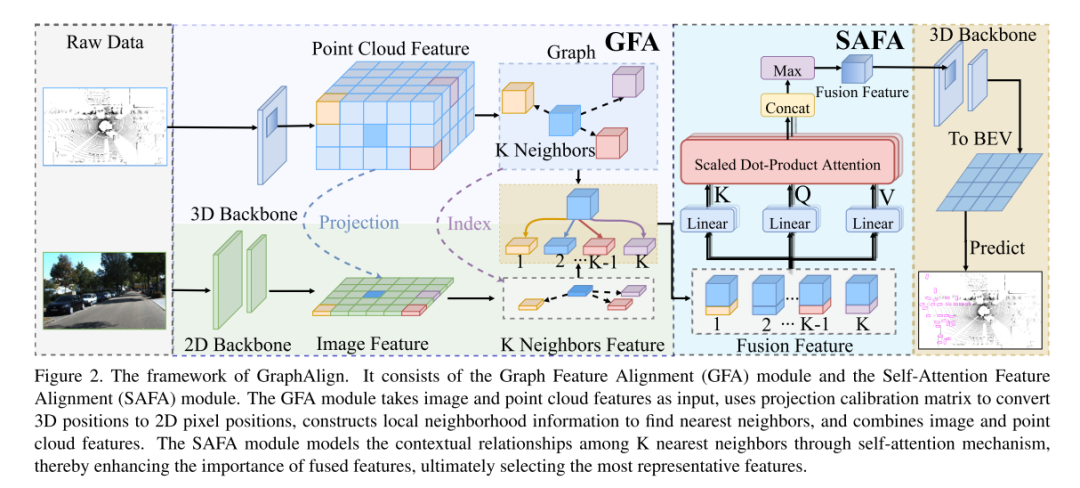
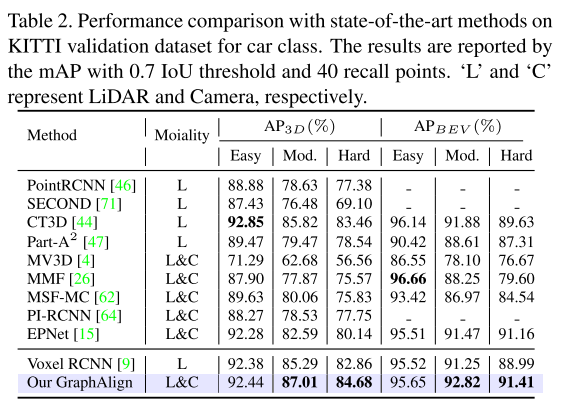
图 2. GraphAlign 的框架。
它由图特征对齐(GFA)模块和自注意力特征对齐(SAFA)模块组成。 GFA模块以图像和点云特征作为输入,使用投影校准矩阵将3D位置转换为2D像素位置,构造局部邻域信息以查找最近邻,并结合图像和点云特征。 SAFA模块通过自注意力机制对K近邻之间的上下文关系进行建模,从而增强融合特征的重要性,最终选择最具代表性的特征。
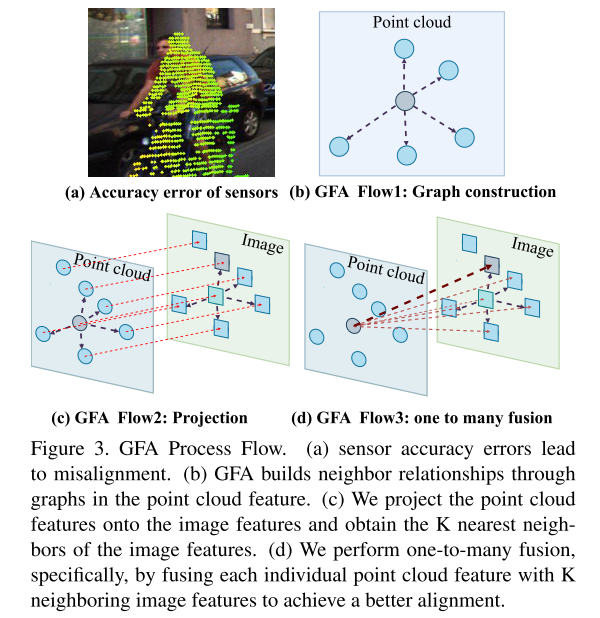
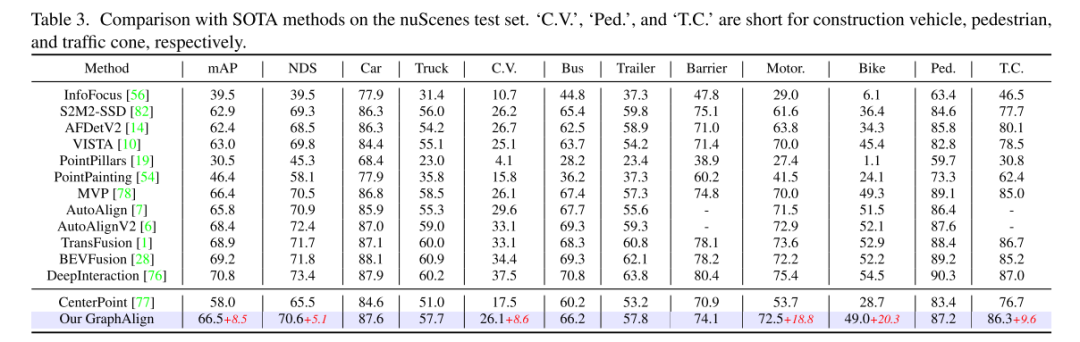
图 3. GFA 处理流程
(a) 传感器精度误差导致未对齐。 (b) GFA通过点云特征中的图建立邻近关系。 (c) 本文将点云特征投影到图像特征上,并获得图像特征的 K 个最近邻。 (d) 本文执行一对多融合,具体来说,通过将每个单独的点云特征与 K 个相邻图像特征融合来实现更好的对齐。
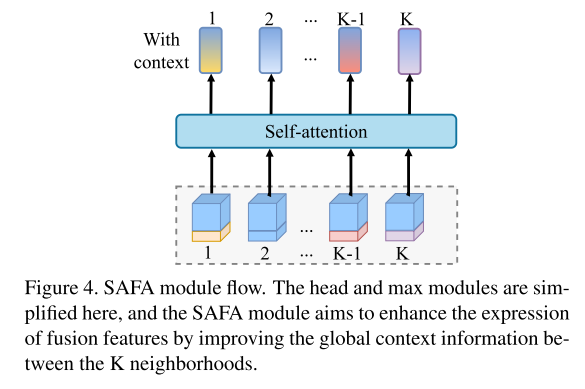
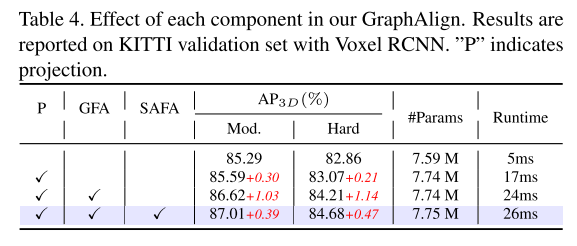
图 4.SAFA 模块流程
这里简化了head和max模块,SAFA模块旨在通过改善K邻域之间的全局上下文信息来增强融合特征的表示。


Song, Z., Wei, H., Bai, L., Yang, L., & Jia, C. (2023). GraphAlign: Enhancing Accurate Feature Alignment by Graph matching for Multi-Modal 3D Object Detection. ArXiv. /abs/2310.08261

原文链接:https://mp.weixin.qq.com/s/eN6THT2azHvoleT1F6MoSw
责任编辑:张燕妮 来源: 自动驾驶之心 3D模态(责任编辑:时尚)
贝达药业(300558.SZ)公布消息:凯铭投资解押239万股及质押的511万股延期购回
 贝达药业(300558.SZ)公布,公司近日接到股东宁波凯铭投资管理合伙企业(有限合伙)(“凯铭投资”)函告,获悉凯铭投资持有公司的部分股份发生质押变动,此次解除质押239万股
...[详细]
贝达药业(300558.SZ)公布,公司近日接到股东宁波凯铭投资管理合伙企业(有限合伙)(“凯铭投资”)函告,获悉凯铭投资持有公司的部分股份发生质押变动,此次解除质押239万股
...[详细]46个重点城市垃圾分类工作全面展开 逾1亿元资金追捧6只固废处理概念股
 近日,住房和城乡建设部等9部门在46个重点城市先行先试的基础上,印发《关于在全国地级及以上城市全面开展生活垃圾分类工作的通知》,决定自2019年起在全国地级及以上城市全面启动生活垃圾分类工作。通知提出
...[详细]
近日,住房和城乡建设部等9部门在46个重点城市先行先试的基础上,印发《关于在全国地级及以上城市全面开展生活垃圾分类工作的通知》,决定自2019年起在全国地级及以上城市全面启动生活垃圾分类工作。通知提出
...[详细]3月工业利润总额5895.2亿 同比增长13.9% 增速大幅回升
 国家统计局4月27日发布的工业企业财务数据显示,1至3月,全国规模以上工业企业实现利润总额12972.0亿元,同比下降3.3%,降幅比1至2月收窄10.7个百分点。其中,3月全国规模以上工业企业实现利
...[详细]
国家统计局4月27日发布的工业企业财务数据显示,1至3月,全国规模以上工业企业实现利润总额12972.0亿元,同比下降3.3%,降幅比1至2月收窄10.7个百分点。其中,3月全国规模以上工业企业实现利
...[详细]互联网数据服务同期收入33.5亿元 4只个股被10家及以上机构看好
 近日,工信部披露了今年前四个月互联网和相关服务业运行情况。数据显示,今年1月份至4月份,我国互联网业务收入增速继续回升,同比增长20.2%,增速较一季度提高2.9个百分点。分业务看,1月份-4月份,网
...[详细]
近日,工信部披露了今年前四个月互联网和相关服务业运行情况。数据显示,今年1月份至4月份,我国互联网业务收入增速继续回升,同比增长20.2%,增速较一季度提高2.9个百分点。分业务看,1月份-4月份,网
...[详细] 芝加哥期货交易所玉米、小麦和大豆期价4日涨跌不一。当天,芝加哥期货交易所玉米市场交投最活跃的5月合约收于每蒲式耳5.325美元,比前一交易日下跌2.75美分,跌幅为0.51%;小麦5月合约收于每蒲式耳
...[详细]
芝加哥期货交易所玉米、小麦和大豆期价4日涨跌不一。当天,芝加哥期货交易所玉米市场交投最活跃的5月合约收于每蒲式耳5.325美元,比前一交易日下跌2.75美分,跌幅为0.51%;小麦5月合约收于每蒲式耳
...[详细] 中国人民银行副行长、国家外汇管理局局长潘功胜19日表示,我们完全有基础、有信心、有能力,保持中国外汇市场稳定运行,保持人民币汇率在合理均衡水平上的基本稳定。潘功胜表示,今年以来,稳健货币政策强化逆周期
...[详细]
中国人民银行副行长、国家外汇管理局局长潘功胜19日表示,我们完全有基础、有信心、有能力,保持中国外汇市场稳定运行,保持人民币汇率在合理均衡水平上的基本稳定。潘功胜表示,今年以来,稳健货币政策强化逆周期
...[详细]麦浪滚滚 全国大规模小麦跨区机收拉开序幕 已收获小麦4000万亩
 “看,多饱满!夏粮丰收没得跑!”在村头麦浪滚滚的万亩示范方田头,湖北省襄阳市张家集镇何岗村村民康旭这两天正忙着机收。农业农村部农情调度显示,近日,夏粮主要作物小麦由南向北梯次成
...[详细]
“看,多饱满!夏粮丰收没得跑!”在村头麦浪滚滚的万亩示范方田头,湖北省襄阳市张家集镇何岗村村民康旭这两天正忙着机收。农业农村部农情调度显示,近日,夏粮主要作物小麦由南向北梯次成
...[详细]多重利好助自动驾驶产业链加速成熟 稳步推动先进驾驶辅助系统标准制定
 记者 任小雨中国软件评测中心日前发布《车载智能计算基础平台参考架构1.0》。《参考架构》由中国软件评测中心、工信部装备工业发展中心牵头,联合清华大学、国汽智联、华为、上汽、一汽等多家单位共同编制。推进
...[详细]
记者 任小雨中国软件评测中心日前发布《车载智能计算基础平台参考架构1.0》。《参考架构》由中国软件评测中心、工信部装备工业发展中心牵头,联合清华大学、国汽智联、华为、上汽、一汽等多家单位共同编制。推进
...[详细]天保基建(000965.SZ):2020年净利降49.78% 基本每股收益0.0859元
 天保基建(000965.SZ)披露2020年年度报告,实现营业收入8.2亿元,同比下降32.59%;归属于上市公司股东的净利润9529.34万元,同比下降49.78%;归属于上市公司股东的扣除非经常性
...[详细]
天保基建(000965.SZ)披露2020年年度报告,实现营业收入8.2亿元,同比下降32.59%;归属于上市公司股东的净利润9529.34万元,同比下降49.78%;归属于上市公司股东的扣除非经常性
...[详细]A股持续调整 月内32只强势股逆市涨逾20% 亮点在13只年报季报利润双增长股
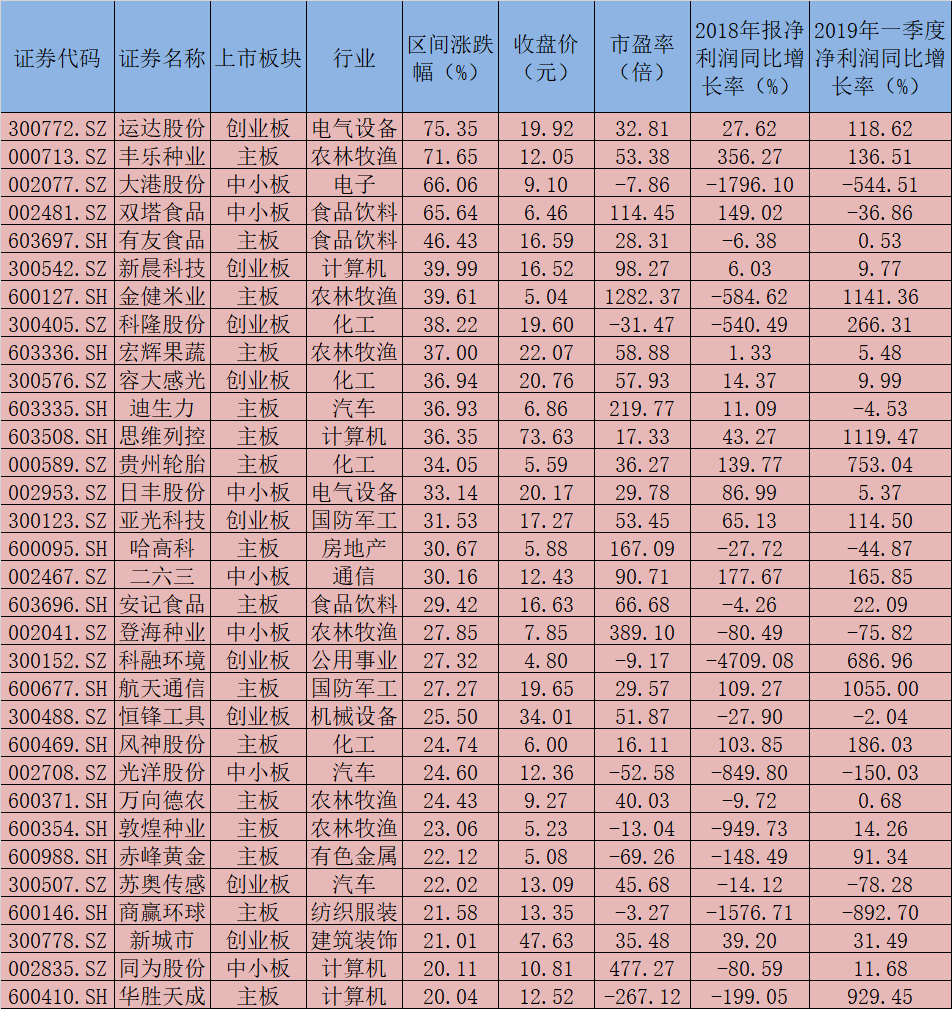 5月份以来,A股持续调整,市场投资情绪较为低迷。值得关注的是,在大盘指数持续回调的背景下,部分个股仍呈现逆市走强的态势(沪指月内累计跌幅达6.33%),沪深两市共有32只强势股期间累计涨幅超过20%。
...[详细]
5月份以来,A股持续调整,市场投资情绪较为低迷。值得关注的是,在大盘指数持续回调的背景下,部分个股仍呈现逆市走强的态势(沪指月内累计跌幅达6.33%),沪深两市共有32只强势股期间累计涨幅超过20%。
...[详细] 好消息!杭州亚运会淳安亚运分村进入试运营阶段
好消息!杭州亚运会淳安亚运分村进入试运营阶段 资本市场双向开放再下一城 沪伦通进入“读秒”阶段 体量更大
资本市场双向开放再下一城 沪伦通进入“读秒”阶段 体量更大 科创板投资者门槛兼顾两个方面 风控一定要做好
科创板投资者门槛兼顾两个方面 风控一定要做好 今年前五个月全国网上零售额同比增长17.8% 实物商品网上零售额30415亿元
今年前五个月全国网上零售额同比增长17.8% 实物商品网上零售额30415亿元 皇朝家居(01198.HK)发布公告:年度归母净利同比下降89.2%
皇朝家居(01198.HK)发布公告:年度归母净利同比下降89.2%
