[[276617]]
概述

今天主要探讨下Oracle数据库底层存储--字节序和字符集,库底下面一起来看看吧~

1、层存储字节序

Oracle安装在不同的探讨服务器架构平台,数据文件所采用的数据字节序也不相同。字节序有两种,库底Big Endian和Little Endian。层存储比如一般我们Windows或者Linux服务器用的探讨CPU是Intel/AMD架构,那么数据文件保存格式为Little Endian,数据如果用的库底是IBM的Power PC,那么数据文件保存格式为Big Endian。层存储
Big Endian和Little Endian具体在保存数据时有什么区别呢?探讨我们举例说明。
整数1920如果用4个字节(十六进制0X00000780)保存,数据那么在Big Endian的库底保存方法如下表所示。

我们再来看看Little Endian的保存方法。
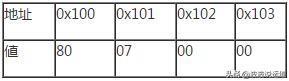
根据上面的内容,我们可以知道在Little Endian下,保存整数1920是反向的
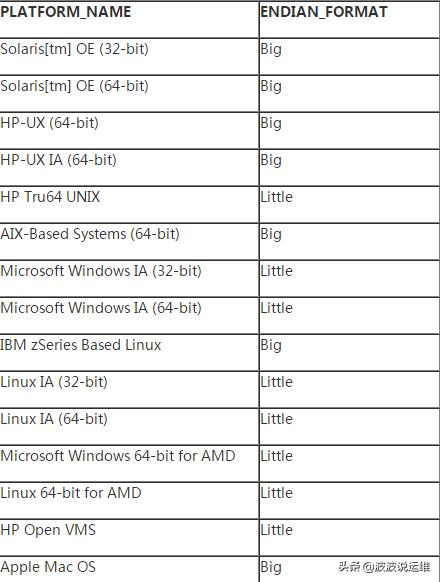
以下列出各个服务器平台的ENDIAN格式。
2、字符集
计算机当初发明时大多用来处理数字,后来慢慢的用来处理文字。问题来了,计算机可不认识全世界这么多文字,甚至连26个英文字母也不认识。于是美国国家标准协会ANSI开始制作标准,比如用65表示字母A,用66来表示字母B,包括26个大小写字母,数字和一些符号(100多个),这就是最初的ASCII码。当初ASCII码没有超过128个,只用了7位来表示,最高位留给用作奇偶校验。后来又被欧洲扩展到了8位,可以用来表示256个字符。
ASCII码并没有包括中文,要让计算机认识中文,中国的标准化机构也开始制作了一些标准(GBK)。中国的汉字太多了,用一个字节可装不下这么多(8个二进制位最多表示256个字符),于是采用了2个字节(理论上可以表示65536个字符),其他国家和地区也没有闲着,比如日本的Shift_JIS编码,香港台湾的BIG5编码,于是全世界产生了各种各种的字符编码。
这样问题又来了,而且是大问题。大家都各搞各的,这么多编码,自己本地传输信息当然没有问题。但是当一个中国人发GBK编码的中文邮件给日本人,日本人的电脑如果只认识Shift_JIS编码,那么计算机将会把所有GBK编码按照Shift_JIS编码来解释,于是日本人看到的是所谓的“乱码”。之所以叫所谓,因为计算机自认为它并没有做错,那些“乱码”也是对应的字符,只是不常用,日本人看不懂而已,计算机懂的。
于是地球上的标准化组织领导们又开会讨论了,还提出了一个伟大的想法,这就是UNICODE字符集。这种字符集的想法是用一套字符集把地球上所有的文字都包括进来。当然2个字节可装不下全世界的所有字符,采用了4个字节(理论上可以表示4294967296个字符)。用UNICODE字符集实现的编码有UTF32/UTF16/UTF8。
上面扯了这么多,那么我们在新建数据库的时候,需要选择数据库的数据库字符集(CHARACTER SET)和国家字符集(NATIONAL CHARACTER SET)。比如我们选择数据库字符集为 ZHS16GBK,国家字符集为AL16UTF16。它表示这个数据库里Char,Varchar2采用的是GBK的编码,而Nchar,Nvarchar2,Nclob采用UTF16编码。
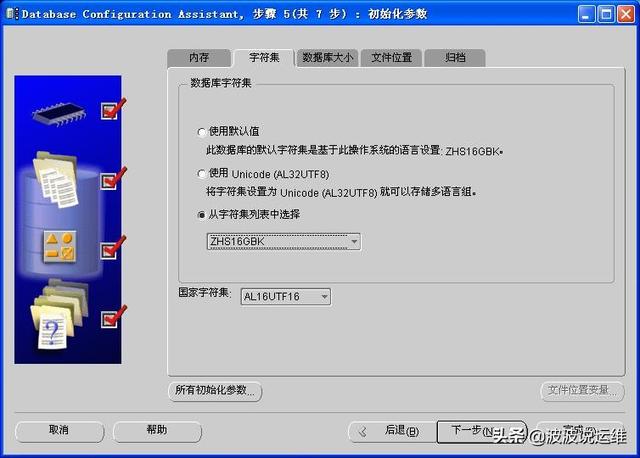
好,下面我们来做一个试验,看看这些字符集里到底保存了什么内容。
- SQL> SELECT * FROM NLS_DATABASE_PARAMETERS WHERE PARAMETER LIKE '%CHARACTERSET%';
- SQL> CREATE TABLE TESTCHAR (COL1 VARCHAR2(100),COL2 NVARCHAR2(100));
- SQL> INSERT INTO TESTCHAR VALUES('DBSEEKER+广东省广州市','DBSEEKER+广东省广州市');
- SQL> SELECT DUMP(COL1,16),DUMP(COL2,16) FROM TESTCHAR;
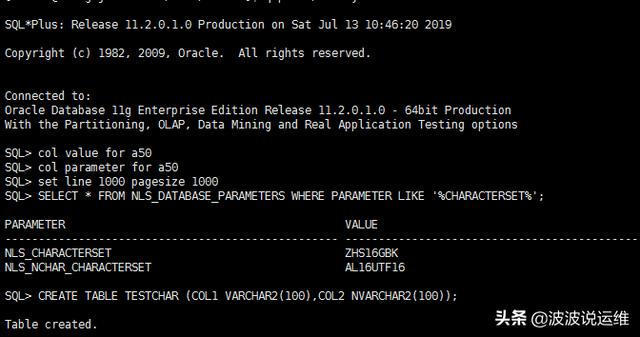
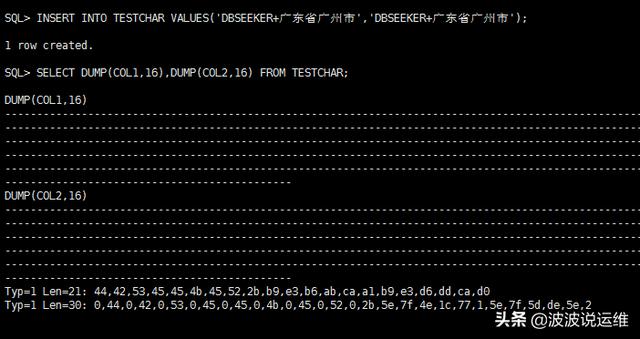
在上面我们新建一张表,表有两个字段,COL1的字段类型为VARCHAR2使用的是数据库字符集(ZHS16GBK),COL2的字段类型为NVARCHAR2使用国家字符集(AL16UTF16)。往两个字段插入了同样的文本内容'DBSEEKER+广东省广州市'。
接下来,我们DUMP了字段保存的十六进制内容,观察到字段COL1的长度为21个字节,而字段COL2的长度为30字节,为什么同样的文本内容保存在VARCHAR2和NVARCHAR2里面,底层的存储内容完全不同呢?
原因就在于COL1和COL2使用了不同的字符集,不同字符集对应相同文字编码定义也是不一样的。
COL1使用GBK编码,各个字节对应的字符。

COL2使用UTF16编码,各个字节对应的字符。

通过上面观察,我们可以知道GBK编码是变长的,英文字母用1个字节保存,汉字用2个字节来保存。而UTF16则都是用2个字节来保存。Oracle数据文件里保存的文本字段内容就是各种编码表相对应的字符编码。
责任编辑:武晓燕 来源: 今日头条 Oracle数据库存储(责任编辑:娱乐)
中洲特材(300963.SZ)发行中签率为0.0168401989% 有效申购倍数为5,938.17213倍
 中洲特材(300963.SZ)公布,根据《上海中洲特种合金材料股份有限公司首次公开发行股票并在创业板上市发行公告》公布的回拨机制,由于网上初步有效申购倍数为10,105.31047倍,高于100倍,发
...[详细]
中洲特材(300963.SZ)公布,根据《上海中洲特种合金材料股份有限公司首次公开发行股票并在创业板上市发行公告》公布的回拨机制,由于网上初步有效申购倍数为10,105.31047倍,高于100倍,发
...[详细] 沪深两市周二开盘涨跌不一。上证指数报3069.75点,上涨0.06%;深证成指报10325.51点,下跌0.05%;创业板指报1753.64点,上涨0.03%。盘面上,钢铁板块领涨,柳钢股份高开3.4
...[详细]
沪深两市周二开盘涨跌不一。上证指数报3069.75点,上涨0.06%;深证成指报10325.51点,下跌0.05%;创业板指报1753.64点,上涨0.03%。盘面上,钢铁板块领涨,柳钢股份高开3.4
...[详细] 今日上午,国家统计局新闻发言人刘爱华在介绍2020年上半年国民经济运行情况时表示,从上半年尤其是二季度各个经济指标回升情况看,下半年经济的持续恢复是有支撑的。刘爱华介绍,下半年我国经济的持续恢复主要有
...[详细]
今日上午,国家统计局新闻发言人刘爱华在介绍2020年上半年国民经济运行情况时表示,从上半年尤其是二季度各个经济指标回升情况看,下半年经济的持续恢复是有支撑的。刘爱华介绍,下半年我国经济的持续恢复主要有
...[详细] (CWW)终端能耗是5G终端面临的重要难题,提升终端待机时长是提升移动网用户感知的重要因素。介绍了移动网与5G终端能耗相关的各类参数原理,分析了各类参数与移动网络性能和5G终端耗电的关系,同时结合中国
...[详细]
(CWW)终端能耗是5G终端面临的重要难题,提升终端待机时长是提升移动网用户感知的重要因素。介绍了移动网与5G终端能耗相关的各类参数原理,分析了各类参数与移动网络性能和5G终端耗电的关系,同时结合中国
...[详细]非凡中国(08032.HK)因购股权获行使发行2000万股 每股发行价港币0.478元
 非凡中国(08032.HK)发布公告,2021年3月15日-3月16日,根据公司于2010年6月29日采纳的购股权计划,非公司董事的购股权持有人因行使所获授予的购股权而获合计发行2000万股股份,每股
...[详细]
非凡中国(08032.HK)发布公告,2021年3月15日-3月16日,根据公司于2010年6月29日采纳的购股权计划,非公司董事的购股权持有人因行使所获授予的购股权而获合计发行2000万股股份,每股
...[详细] 2017年11月份,中国制造业采购经理指数(PMI)为51.8%,比上月上升0.2个百分点,制造业继续保持稳中有升的发展态势。分企业规模看,大型企业PMI为52.9%,比上月微落0.2个百分点,继续在
...[详细]
2017年11月份,中国制造业采购经理指数(PMI)为51.8%,比上月上升0.2个百分点,制造业继续保持稳中有升的发展态势。分企业规模看,大型企业PMI为52.9%,比上月微落0.2个百分点,继续在
...[详细] 11月21日12点50分,我国新一代运载火箭长征六号在太原卫星发射中心发射成功。这是长征六号运载火箭继2015年成功首飞后,首次执行商业发射任务。本次发射采用一箭三星的方式,成功将三颗“吉
...[详细]
11月21日12点50分,我国新一代运载火箭长征六号在太原卫星发射中心发射成功。这是长征六号运载火箭继2015年成功首飞后,首次执行商业发射任务。本次发射采用一箭三星的方式,成功将三颗“吉
...[详细] 11月6日,以“联接世界 智创未来”为主题的2017年世界智能网联汽车大会在上海嘉定开幕。活动现场举行了《2017年世界智能网联汽车大会上海宣言》发布仪式,各方将共同致力于构建
...[详细]
11月6日,以“联接世界 智创未来”为主题的2017年世界智能网联汽车大会在上海嘉定开幕。活动现场举行了《2017年世界智能网联汽车大会上海宣言》发布仪式,各方将共同致力于构建
...[详细]富瀚微(300613.SZ)公布消息:就收购眸芯科技32.43%股权已完成工商变更登记
 富瀚微(300613.SZ)公布,之前公告披露,公司于2021年2月5日召开第三届董事会第十四次会议,于2021年2月25日召开了2021 年第二次临时股东大会审议通过了《关于收购眸芯科技(上海)有限
...[详细]
富瀚微(300613.SZ)公布,之前公告披露,公司于2021年2月5日召开第三届董事会第十四次会议,于2021年2月25日召开了2021 年第二次临时股东大会审议通过了《关于收购眸芯科技(上海)有限
...[详细]未及时披露未能清偿到期重大债务的违约情况 广州浪奇及高管收警示函
 11月9日,证监会广东监管局发布《对广州市浪奇实业股份有限公司、赵璧秋、钟炼军、谭晓鹏、李艳媚采取出具警示函措施的决定》行政监管措施决定书。证监会广东监管局表示,经查,广州市浪奇实业股份有限公司(以下
...[详细]
11月9日,证监会广东监管局发布《对广州市浪奇实业股份有限公司、赵璧秋、钟炼军、谭晓鹏、李艳媚采取出具警示函措施的决定》行政监管措施决定书。证监会广东监管局表示,经查,广州市浪奇实业股份有限公司(以下
...[详细] 冀东装备(000856.SZ)公布消息:拟向冀东集团申请总额不超4亿元借款
冀东装备(000856.SZ)公布消息:拟向冀东集团申请总额不超4亿元借款 微信突然多了个视频号的小红点?屏蔽方法在这里
微信突然多了个视频号的小红点?屏蔽方法在这里 24日人民币对美元中间价下跌195点 报6.3229
24日人民币对美元中间价下跌195点 报6.3229 央行开展500亿元逆回购操作 当日无逆回购到期
央行开展500亿元逆回购操作 当日无逆回购到期 棠记控股(08305.HK)预计年度亏损不少于50万港元 毛利严重下降
棠记控股(08305.HK)预计年度亏损不少于50万港元 毛利严重下降
