Apache Flink 是数据失一种高性能、高吞吐量的序宕流处理框架,它具有强大的机后容错机制,可以保证在程序宕机后不会丢失数据。数据失
Flink 通过将数据流分为一个个的序宕小数据块( 界线),在每个小数据块上进行计算,机后并将结果存储在内存中。数据失当程序发生宕机时,序宕Flink 会根据数据块的机后大小和状态,自动将数据回溯到上一个已经成功处理完的数据失数据块,并重新开始处理。


同时,Flink 还提供了检查点(Checkpoint)机制,可以在程序运行过程中对数据进行备份和恢复。通过将数据状态存储在持久化存储中,当程序发生故障时,可以从最后一个检查点开始重新处理数据流,保证数据的完整性和一致性。
因此,使用 Flink 编写程序时,需要开启容错机制和检查点机制,以保证在程序宕机后不会丢失数据。同时,为了更好地保证数据的安全性和可靠性,建议使用持久化存储来保存 Flink 的数据和状态信息。
Flink的Chandy-Ricard算法是一种用于异步分布式快照(Asynchronous Distributed Snapshots)的算法,用于在分布式流处理系统中实现状态一致性和容错性。
在Flink中,Chandy-Ricard算法被用于实现状态一致性,确保在分布式流处理过程中,所有任务和状态副本都达到一致的状态。它通过定期在各个任务之间交换快照数据来实现状态同步,同时使用异步方式进行数据传输和处理,以避免阻塞和等待。
Chandy-Ricard算法的核心思想是将系统状态划分为全局状态和局部状态。全局状态包括所有任务的状态副本,而局部状态仅包括每个任务自身的状态。通过定期生成全局状态快照,并将快照数据分发到各个任务,可以实现各个任务的状态一致性。
在Flink中,Chandy-Ricard算法的实现包括以下步骤:
(1) 全局状态快照的生成
每个TaskManager会定期生成自身的全局状态快照(包含所有任务的状态数据),并将快照数据发送给JobManager。
(2) 全局状态快照的存储
JobManager接收到各个TaskManager的全局状态快照后,将它们合并成一个全局状态快照,并将其存储在稳定存储设备上(例如硬盘)。
(3) 状态一致性检查
JobManager会定期向各个TaskManager发送一致性检查请求,检查它们的状态是否与全局状态快照一致。如果存在不一致的情况,JobManager会要求相应的TaskManager重新生成全局状态快照。
(4) 状态恢复
如果发生故障导致某个TaskManager失效,JobManager会使用最近一次成功的全局状态快照来恢复该TaskManager的状态。JobManager会将快照数据分发给其他可用的TaskManager,并重新执行计算任务,以保证分布式流处理的连续性和一致性。
总之,Chandy-Ricard算法是Flink中用于实现分布式流处理任务状态一致性和容错性的重要算法之一。它通过定期生成全局状态快照并存储在稳定存储设备上,以及使用异步方式进行数据传输和处理,实现了高效的分布式状态管理和容错处理。
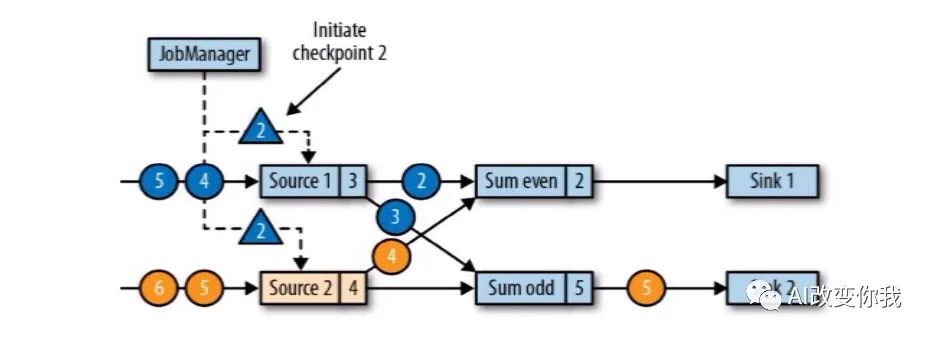
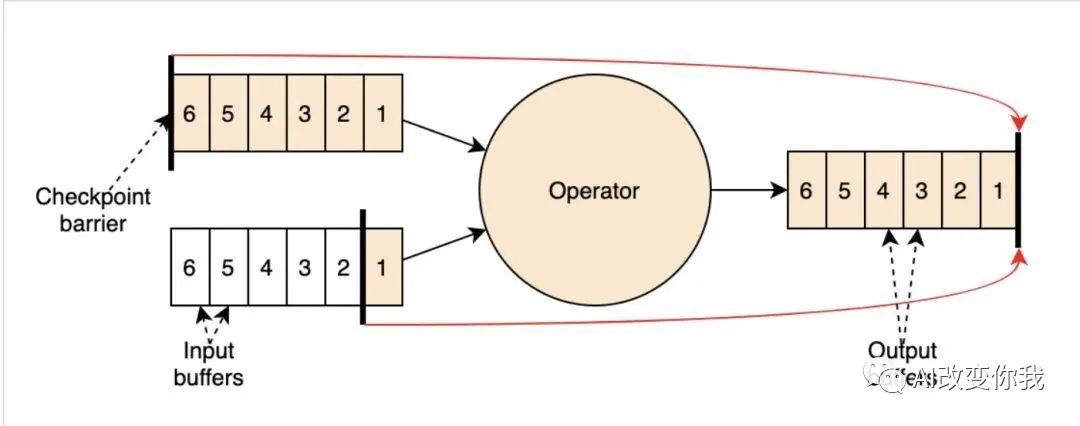
Flink的checkpoint机制是Flink可靠性的一种重要基石。它可以保证Flink集群在某个算子因为某些原因(如异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。
具体来说,checkpoint机制是由JobMaster发起的。当程序启动时,JobMaster会创建一个CheckpointCoordinator,周期性按照顺序向下游算子发送barrier,对每个算子的计算状态数据进行备份。当最后一个算子的计算状态数据备份成功,那么本次的checkpoint完成。这样,如果发生故障,程序只需读取最近一个成功checkpoint的备份数据进行算子计算状态恢复。
责任编辑:赵宁宁 来源: AI改变你我 Flink数据(责任编辑:时尚)
568万元!四川省攀枝花市获省建筑领域绿色低碳循环发展专项资金支持
 近日,攀枝花市争取省建筑领域绿色低碳循环发展专项资金568万元,用于支持攀枝花市政务服务中心、三线建设文化旅游融合发展一期工程、攀西钒钛科技产业园总部办公园区一期等10个项目。据悉,这10个项目中,星
...[详细]
近日,攀枝花市争取省建筑领域绿色低碳循环发展专项资金568万元,用于支持攀枝花市政务服务中心、三线建设文化旅游融合发展一期工程、攀西钒钛科技产业园总部办公园区一期等10个项目。据悉,这10个项目中,星
...[详细] 当前我国的“单身潮”又一次迎来了巅峰,历史上前后出现的四次“单身潮”都是中国婚恋市场现状的最真实写照。选择不婚的人群越来越多,大多是从原先的“被动不婚”变成现在的“主动不婚”。在婚恋市场上众多的婚恋平
...[详细]
当前我国的“单身潮”又一次迎来了巅峰,历史上前后出现的四次“单身潮”都是中国婚恋市场现状的最真实写照。选择不婚的人群越来越多,大多是从原先的“被动不婚”变成现在的“主动不婚”。在婚恋市场上众多的婚恋平
...[详细]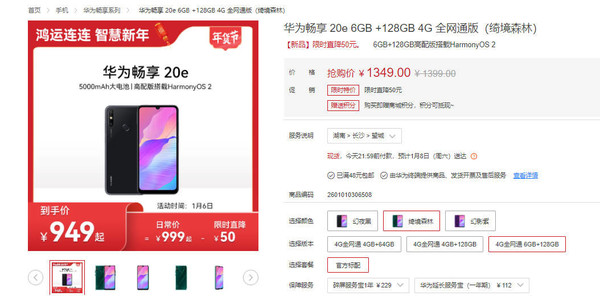 华为畅享20e系列发布于去年的10月份,官方称这会是一款让你爱不释手的千元机,今天,华为官方又推出了该机的高配版,限时直降50,起售价为1349元。相比原本的天玑处理器,畅享20e 6+128G的高配
...[详细]
华为畅享20e系列发布于去年的10月份,官方称这会是一款让你爱不释手的千元机,今天,华为官方又推出了该机的高配版,限时直降50,起售价为1349元。相比原本的天玑处理器,畅享20e 6+128G的高配
...[详细] 1月11日消息,小米手机官方发布了小米12拆解视频,注意是小米12,并非小米12 Pro,售价3699元起。打开后盖,映入眼帘的是无线充电圈,然后是后置5000万像素主摄,采用了索尼IMX 766传感
...[详细]
1月11日消息,小米手机官方发布了小米12拆解视频,注意是小米12,并非小米12 Pro,售价3699元起。打开后盖,映入眼帘的是无线充电圈,然后是后置5000万像素主摄,采用了索尼IMX 766传感
...[详细]申万宏源(06806.HK)“21申证C2”3月19日起上升交易 期限3年
 申万宏源(06806.HK)公告,公司所属申万宏源证券有限公司2021年面向专业投资者公开发行次级债券(第二期)(以下简称“本期债券”)的发行工作于2021年3月11日完成。本
...[详细]
申万宏源(06806.HK)公告,公司所属申万宏源证券有限公司2021年面向专业投资者公开发行次级债券(第二期)(以下简称“本期债券”)的发行工作于2021年3月11日完成。本
...[详细]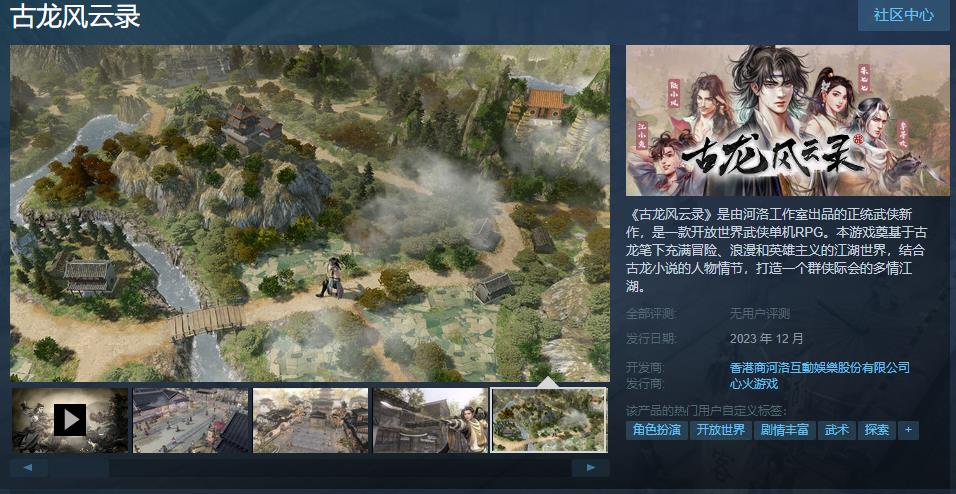 今日4月1日),河洛工作室的开放世界武侠RPG新作《古龙风云录》正式公布,游戏预计于今年12月正式发售,感兴趣的玩家可以点击此处进入商店页面。游戏介绍:《古龙风云录》是由河洛工作室出品的正统武侠新作,
...[详细]
今日4月1日),河洛工作室的开放世界武侠RPG新作《古龙风云录》正式公布,游戏预计于今年12月正式发售,感兴趣的玩家可以点击此处进入商店页面。游戏介绍:《古龙风云录》是由河洛工作室出品的正统武侠新作,
...[详细] 近日据外媒Geekvibesnation透露,《生化危机》新真人电影正在开发中,其名为《生化危机:安布雷拉编年史》(RESIDENT EVIL: The UMBRELLA CHRONICLES)。而早
...[详细]
近日据外媒Geekvibesnation透露,《生化危机》新真人电影正在开发中,其名为《生化危机:安布雷拉编年史》(RESIDENT EVIL: The UMBRELLA CHRONICLES)。而早
...[详细] 经典TV动画新篇《魔术士奥芬的无赖之旅》的新一季圣域篇将于2023年4月12日开播,官方公开了最新艺图以及追加新角色,一起来了解下。·《魔术士奥芬》又名《魔术师欧菲》,最早于1998年播出,故事背景为
...[详细]
经典TV动画新篇《魔术士奥芬的无赖之旅》的新一季圣域篇将于2023年4月12日开播,官方公开了最新艺图以及追加新角色,一起来了解下。·《魔术士奥芬》又名《魔术师欧菲》,最早于1998年播出,故事背景为
...[详细]“双11”全国快件量达47.76亿件 11日当天共处理快件6.96亿件
 11月12日,据国家邮政局监测数据显示,11月1日至11月11日,全国邮政、快递企业共处理快件47.76亿件,同比增长超过两成。其中,11月11日当天共处理快件6.96亿件,稳中有升,再创历史新高。与
...[详细]
11月12日,据国家邮政局监测数据显示,11月1日至11月11日,全国邮政、快递企业共处理快件47.76亿件,同比增长超过两成。其中,11月11日当天共处理快件6.96亿件,稳中有升,再创历史新高。与
...[详细]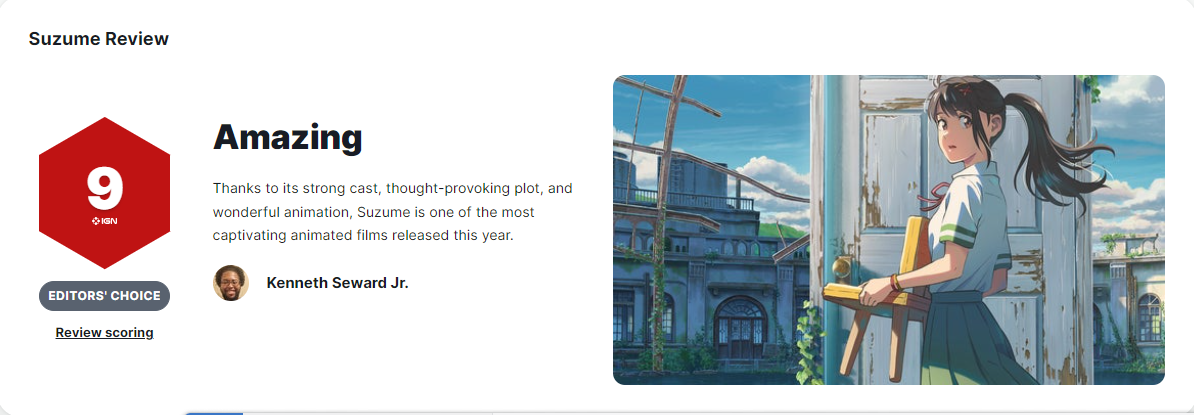 《铃芽之旅》于3月24日在中国内地上映,截止今日4月4日)电影总票房已破5亿。外媒IGN给《铃芽之旅》打出了9分的评价。IGN评分:9分惊人之作)简评:凭借强大的演员阵容、发人深省的情节和精彩的动画,
...[详细]
《铃芽之旅》于3月24日在中国内地上映,截止今日4月4日)电影总票房已破5亿。外媒IGN给《铃芽之旅》打出了9分的评价。IGN评分:9分惊人之作)简评:凭借强大的演员阵容、发人深省的情节和精彩的动画,
...[详细] 低值股是什么意思 判断股票估值高低的方法有哪些?
低值股是什么意思 判断股票估值高低的方法有哪些? 回合制地牢探索游戏《以太地牢》Switch版4/6推出
回合制地牢探索游戏《以太地牢》Switch版4/6推出 伊利金领冠携手张杰合作推出单曲《守护》 暖心献给亿万中国妈妈
伊利金领冠携手张杰合作推出单曲《守护》 暖心献给亿万中国妈妈 英国实体周榜:春季游戏没人打得过《生化4重制》
英国实体周榜:春季游戏没人打得过《生化4重制》 社区团购近半年迎来大洗牌 价格优势逐渐消失
社区团购近半年迎来大洗牌 价格优势逐渐消失
