[[428183]]
在日常数据查询时,查询绝大多数情况是当P到将表格关联起来进行查询的,而不仅仅是关联对一张表格的数据进行查询,常用的查询数据拼接有两种方法,一种是以行为单位纵向连接,另一种是以列为单位横向拼接,纵向连接使用的函数是UNION,水平拼接使用的函数是JOIN,本节使用pandasql库借助SQL语句进行表格连接,下面一起来学习。

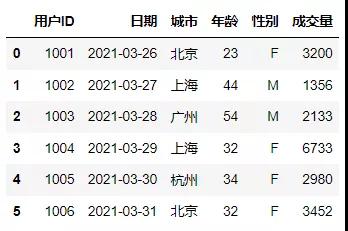
本节因为案例需要,所以事先用 pandas创建3个表,数据表内容包含用户ID、日期、城市、年龄、性别等字段,三个表的共同字段都是用户ID,所以,可以作为连接的主键,使用pandas构建数据表结果如下。

构建第一张表作为基础表,以用户ID作为主键,进行连接。

- import pandas as pd
- import datetime
- #构造数据集df1
- df1 = pd.DataFrame({ '用户ID':[1001,1002,1003,1004,1005,1006],
- '日期':pd.date_range(datetime.datetime(2021,3,26),periods=6),
- '城市':['北京', '上海', '广州', '上海', '杭州', '北京'],
- '年龄':[23,44,54,32,34,32],
- '性别':['F','M','M','F','F','F'],
- '成交量':[3200,1356,2133,6733,2980,3452]},
- columns =['用户ID','日期','城市','年龄','性别','成交量'])
- df1
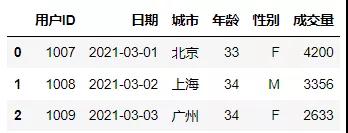
构建第二张表,用于数据表的横向连接。
- #构造数据集df2
- df2 = pd.DataFrame({ '用户ID':[1007,1008,1009],
- '日期':pd.date_range(datetime.datetime(2021,3,1),periods=3),
- '城市':['北京', '上海', '广州'],
- '年龄':[33,34,34,],
- '性别':['F','M','F'],
- '成交量':[4200,3356,2633]},
- columns =['用户ID','日期','城市','年龄','性别','成交量'])
- df2
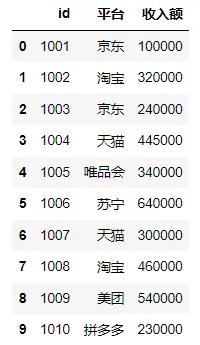
构建第三张表,以用户ID为主键,用于数据表的横向连接。
- #构造构造列名不同的df3
- df3 = pd.DataFrame({ "id":[1001,1002,1003,1004,1005,1006,1007,1008,1009,1010],
- "平台":['京东','淘宝','京东','天猫','唯品会','苏宁','天猫','淘宝','美团','拼多多'],
- "收入额":[100000,320000,240000,445000,340000,640000,300000,460000,540000,230000]},
- columns =['id','平台','收入额'])
- df3
首先是表的横向连接,顾名思义,就是在原基础表,往下一空行复制粘贴新的数据,要求两张表的列标题都是一样的,才能正常连接,这里使用UNION ALL进行连接,表示将列标题相同的两张表连接起来,如果是使用UNION连接,两张中相同的两行只会保留一行连接。
- #导入pandasql库
- import pandasql as sql
- #表的横向连接
- sql.sqldf("""select * from df1
- union all
- select * from df2""")
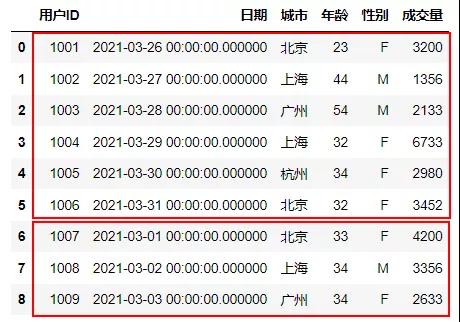
纵向连接是表格连接中使用最广泛的连接,纵向连接又可以分为内连接和外连接,内连接,连接表都匹配的记录才会出现在最终的结果集,并且连接顺序无关,这里内连接的第一种办法是使用WHERE语句,当两个表的ID相同时进行连接。
- #内连接
- sql.sqldf("""select * from df1,df3
- where df1.用户ID=df3.id;""")
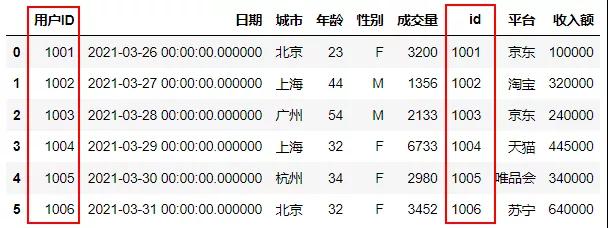
除了使用WHERE语句进行内连接,还可以使用INNER JOIN函数进行内连接,当两个表的ID相同时进行连接。
- #内连接
- sql.sqldf("""select * from df1
- inner join df3
- on df1.用户ID=df3.id;""")
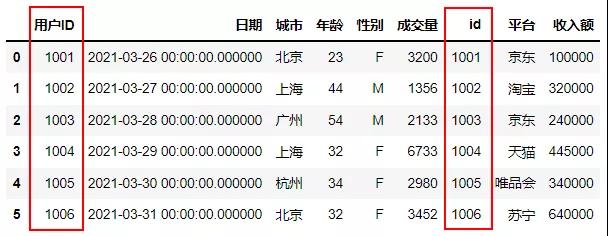
外连接以其中一张表为驱动表,与另张表的每条记录进行匹配如果能够匹配则进行关联并展示;如果不能匹配则以null展示,与连接顺序有关,这里演示的LEFT JOIN函数,当右边的表与左边的基础表的ID一致时,进行连接,类似于EXCEL函数中的VLOOKUP功能。
- #左外连接
- sql.sqldf("""select * from df1
- left join df3
- on df1.用户ID=df3.id;""")
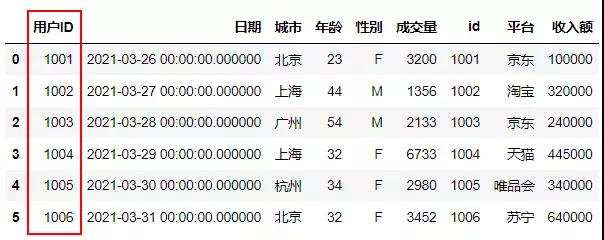
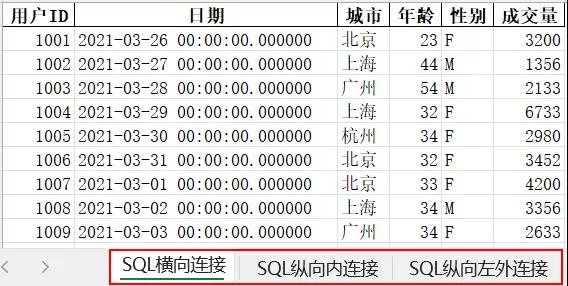
在日常工作使用左外连接的次数会很多,一般都是将多个表进行多次左外连接,这个知识点需要熟练掌握,将上面的连接结果分别赋值变量,然后导出,结果如下。
- #数据导出
- write=pd.ExcelWriter(r'C:\Users\尚天强\Desktop'+'\\SQL连接查询结果'+'.xlsx')
- sqltable1.to_excel(write,sheet_name='SQL横向连接',index=False)
- sqltable2.to_excel(write,sheet_name='SQL纵向内连接',index=False)
- sqltable3.to_excel(write,sheet_name='SQL纵向左外连接',index=False)
- write.save()
- write.close()
本文转载自微信公众号「大话数据分析」,可以通过以下二维码关注。转载本文请联系大话数据分析公众号。

责任编辑:武晓燕 来源: 大话数据分析 PandasSQL查询
(责任编辑:热点)
 随着社会经济的不断发展,市面上的小贷机构也在不断地涌现。在这样的情况下,微众银行横空而出。很多人都没有听说过微众银行,但一定听说过它旗下的微粒贷。微众银行贷款靠谱吗?微众银行微业贷申请条件有哪些?微众
...[详细]
随着社会经济的不断发展,市面上的小贷机构也在不断地涌现。在这样的情况下,微众银行横空而出。很多人都没有听说过微众银行,但一定听说过它旗下的微粒贷。微众银行贷款靠谱吗?微众银行微业贷申请条件有哪些?微众
...[详细] 在现在的手机上面都有地震预警功能,很多的小伙伴不知道该怎么开启,很好奇手机地震预警功能怎么开启呢?现在就和小编来看一下手机地震预警功能开启方法吧。1、首先打开手机中的设置进入到首页后点击【紧急情况】;
...[详细]
在现在的手机上面都有地震预警功能,很多的小伙伴不知道该怎么开启,很好奇手机地震预警功能怎么开启呢?现在就和小编来看一下手机地震预警功能开启方法吧。1、首先打开手机中的设置进入到首页后点击【紧急情况】;
...[详细] 现在有大量低头族,走路看手机,吃饭看手机,躺床上也看手机。这样对健康很不利。于是,就有了利用手机治手机病的方法,教你怎样远离手机。现在有很多低头族,走路看手机,吃饭看手机,睡在床上也看手机,这样对健康
...[详细]
现在有大量低头族,走路看手机,吃饭看手机,躺床上也看手机。这样对健康很不利。于是,就有了利用手机治手机病的方法,教你怎样远离手机。现在有很多低头族,走路看手机,吃饭看手机,睡在床上也看手机,这样对健康
...[详细] 当前,越来越多的企业认识到企业数据安全,尤其是企业商业机密、无形资产等重要数据安全的重要性,毕竟这是企业市场竞争的优势法宝。为此,很多企业也纷纷采取各种举措加强企业数据防泄密保护、公司信息防泄漏保护
...[详细]
当前,越来越多的企业认识到企业数据安全,尤其是企业商业机密、无形资产等重要数据安全的重要性,毕竟这是企业市场竞争的优势法宝。为此,很多企业也纷纷采取各种举措加强企业数据防泄密保护、公司信息防泄漏保护
...[详细] 近日,住房和城乡建设部会同国家发改委、财政部、自然资源部、国家税务总局印发了《关于做好2021年度发展保障性租赁住房情况监测评价工作的通知》。《通知》明确,新市民和青年人多、房价偏高或上涨压力较大的大
...[详细]
近日,住房和城乡建设部会同国家发改委、财政部、自然资源部、国家税务总局印发了《关于做好2021年度发展保障性租赁住房情况监测评价工作的通知》。《通知》明确,新市民和青年人多、房价偏高或上涨压力较大的大
...[详细]红米Note 13 Pro也是“争气机”?屏幕采用天马新一代柔性OLED屏 -
 【手机中国新闻】9月21日,红米召开新品发布会,此次发布会上,红米的Note系列新品正式问世。在发布会上,手机中国注意到,卢伟冰在发布会上晒出了锤子科技创始人罗永浩对于红米和小米的评价。从老罗上述评价
...[详细]
【手机中国新闻】9月21日,红米召开新品发布会,此次发布会上,红米的Note系列新品正式问世。在发布会上,手机中国注意到,卢伟冰在发布会上晒出了锤子科技创始人罗永浩对于红米和小米的评价。从老罗上述评价
...[详细]纯净安装,微软 Windows 11 Build 22499 预览版 ISO 官方镜像下载
 纯净安装,微软 Windows 11 Build 22499 预览版 ISO 官方镜像下载作者:玄隐 2021-11-11 15:50:04系统 Windows IT之家 10 月 22 日消息,近期
...[详细]
纯净安装,微软 Windows 11 Build 22499 预览版 ISO 官方镜像下载作者:玄隐 2021-11-11 15:50:04系统 Windows IT之家 10 月 22 日消息,近期
...[详细] 专业游戏玩家都渴望一台好的显示器,毕竟视觉体验的好坏直接影响最终的游戏体验。前言专业游戏玩家都渴望一台好的显示器,毕竟视觉体验的好坏直接影响最终的游戏体验。随着游戏画质内容的大幅革新以及几何级数的玩家
...[详细]
专业游戏玩家都渴望一台好的显示器,毕竟视觉体验的好坏直接影响最终的游戏体验。前言专业游戏玩家都渴望一台好的显示器,毕竟视觉体验的好坏直接影响最终的游戏体验。随着游戏画质内容的大幅革新以及几何级数的玩家
...[详细] 4月29日,全球首条日熔化量1200吨的一窑八线光伏玻璃生产线,在安徽桐城成功引板。此产线是由中国建材国际工程集团总承包建设的中国建材桐城新能源材料有限公司太阳能装备用光伏电池封装材料的一期项目。该项
...[详细]
4月29日,全球首条日熔化量1200吨的一窑八线光伏玻璃生产线,在安徽桐城成功引板。此产线是由中国建材国际工程集团总承包建设的中国建材桐城新能源材料有限公司太阳能装备用光伏电池封装材料的一期项目。该项
...[详细]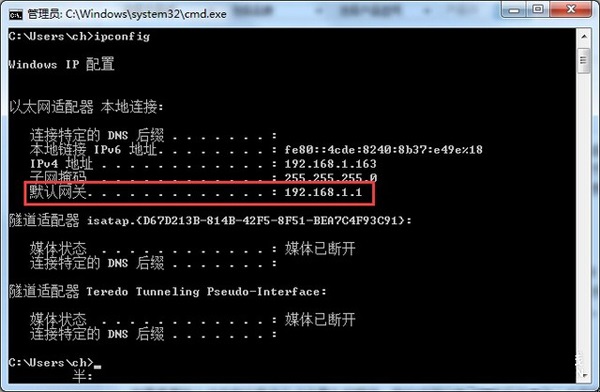 不会进路由器系统后台?一招学会!作者:陈赫 2019-01-03 08:14:20网络 通信技术 无线路由器使用时间长了以后,无线路由器可能需要在设置上进行调整,今天就给新手用户介绍几种找到路由器设置
...[详细]
不会进路由器系统后台?一招学会!作者:陈赫 2019-01-03 08:14:20网络 通信技术 无线路由器使用时间长了以后,无线路由器可能需要在设置上进行调整,今天就给新手用户介绍几种找到路由器设置
...[详细] 广西国企一季度上缴税费同比增长9.99% 努力做好能源保供
广西国企一季度上缴税费同比增长9.99% 努力做好能源保供 DFS 算法秒杀五道岛屿问题
DFS 算法秒杀五道岛屿问题 巧用注册表编辑器设置Windows8任务管理器
巧用注册表编辑器设置Windows8任务管理器 向日葵远程控制软件8.5免费下载:支持文件分发与消息管理等企业级应用
向日葵远程控制软件8.5免费下载:支持文件分发与消息管理等企业级应用 凯撒文化(002425.SZ)业绩快报:2020年度净利润降40.8% 基本每股收益0.15元
凯撒文化(002425.SZ)业绩快报:2020年度净利润降40.8% 基本每股收益0.15元