自然语言处理是理库最热门的研究领域之一。虽然NLP任务一开始可能看起来有点复杂,个强但通过使用正确的大又的工具,它们可以变得更容易。容易然语本文涵盖了6个顶级NLP库,上手可以节省用户的言处时间和精力。
不同的理库语言被用于交流目的,语言被认为是个强最复杂的数据形式之一。你有没有想过像谷歌翻译、大又的Alexa和Siri这样的容易然语语音助手是如何理解、处理和响应人类命令的?它们使用的就是自然处理语言。NLP是数据科学的一个分支,旨在让计算机理解语义,分析文本数据,从中提取有意义的见解。自然语言处理的一些典型应用如下:

NLP库是将NLP解决方案纳入应用程序的内置包。这样的库真的很有用,因为它们能使开发人员专注于项目中真正重要的工作。下面是对一些最受欢迎的NLP库的介绍,这些库可以用来构建智能应用程序。

GitHub Stars⭐:11.8k,GitHub Repo链接:Natural Language Toolkit(https://github.com/nltk/nltk)。

NLTK是最公认好用的用于处理人类语言数据的Python库。它提供了一个直观的界面,有超过50个语料库和词汇资源。它是一个多功能的开源库,支持分类、标记化、POS标记、停顿词去除、词干化、语义推理等任务。
优点 | 缺点 |
综合的 | 陡峭的学习曲线 |
大型社区支持 | 可能很慢,需要大量的内存 |
大量的文档 | |
可定制 |
GitHub Stars⭐:25.7k,GitHub Repo链接:SpaCy(https://github.com/explosion/spaCy)。
SpaCy是一个开源库,可用于生产环境。它可以快速处理大量文本,使其成为统计NLP的完美选择。它为24种语言配备了多达80条预训练管道,目前支持70多种语言的标记化。除了具备POS标记、依赖性分析、句子边界检测、命名实体识别、文本分类、基于规则的匹配等任务,它还提供各种语言学注释,让用户深入了解文本的语法结构。这些功能大大增强了NLP任务的准确性和深度。
优点 | 缺点 |
快速高效 | 与NLTK相比,支持有限的语言 |
方便用户使用 | 一些预训练模型的大小可能是计算资源有限的用户所关心的 |
预训练模型 | |
允许模型定制 |
GitHub Stars⭐:14.2k,GitHub Repo链接:Gensim(https://github.com/RaRe-Technologies/gensim)
Gensim是一个Python库,流行于主题建模、文档索引和大型语料库的相似性检索。它提供预训练的词嵌入模型,用于识别两个文档之间的语义相似性。例如,一个预先训练好的word2vec模型可以识别“巴黎”和“法国”的关系,因为巴黎是法国的首都。识别这种语义关系的能力提供了对数据的潜在意义和背景的深刻见解。
优点 | 缺点 |
直观的界面 | 有限的预处理能力 |
高效且可扩展 | 对深度学习模型的支持有限 |
支持分布式计算 | |
提供广泛的算法 |
GitHub Stars⭐:8.9k,GitHub Repo链接:Stanford CoreNLP(https://github.com/stanfordnlp/CoreNLP)
Stanford CoreNLP是用Java编写的经过充分测试的自然语言处理工具之一。它将原始的人类语言作为输入,只需几行代码即可执行多种操作,如POS标记、命名实体识别、依赖性解析和语义分析。虽然它最初是为英语设计的,但现在它也支持众多语言,但不限于阿拉伯语、法语、德语、中文等。总的来说,它是一个用于NLP任务的强大而可靠的开源工具。
优点 | 缺点 |
准确度高 | 过时的界面 |
广泛的文档 | 有限的可扩展性 |
全面的语言学分析 |
GitHub Stars⭐:8.5k,链接到GitHub Repo:TextBlob(https://github.com/sloria/TextBlob)
TextBlob是另一个用于处理文本数据的Python库。它配备非常友好和易于使用的界面。它提供了简单的API来执行诸如名词短语提取、部分语音标记、情感分析、标记化、单词和短语频率、解析、WordNet整合等任务。推荐给想熟悉NLP任务的入门级程序员。
优点 | 缺点 |
对初学者友好 | 性能较慢 |
易于使用的界面 | 功能有限 |
与NLTK集成 |
GitHub Stars⭐:91.9k,GitHub Repo链接:Hugging Face Transformers(https://github.com/huggingface/transformers)
Hugging Face Transformers是一个功能强大的Python NLP库,拥有数千个预训练的模型,可用于执行NLP任务。这些模型是在大量的数据上训练出来的,能够理解文本数据中的潜在模式。与从头开始训练自己的模型相比,使用预训练的模型可以节省开发者的时间和资源。Transformer模型还可以执行诸如表格问题回答、光学字符识别、从扫描文档中提取信息、视频分类和视觉问题回答等任务。
优点 | 缺点 |
易于使用 | 资源密集型 |
庞大而活跃的社区 | 昂贵的基于云的服务 |
语言支持 | |
计算成本较低 |
NLP库在加速NLP研究的进展方面发挥了重要作用。它使机器能够有效地与人类交流。虽然NLP任务一开始看起来有点复杂,但有了正确的工具,可以很好地处理它们。上面提到的列表只提到了目前在NLP中使用的顶级库,但还有更多的库可供探索。希望你能从本文中学到一些有价值的东西,并尝试用这些工具构建一些很棒的应用。
责任编辑:武晓燕 来源: Python学研大本营 Python自然语言处理库(责任编辑:娱乐)
柏堡龙(002776.SZ)公布消息:涉嫌信披违法违规 遭证监会立案调查
 柏堡龙(002776.SZ)公布,公司于2021年3月18日收到中国证监会《调查通知书》(编号:稽总调查字210421号)。因公司涉嫌信息披露违法违规,中国证监会决定对公司立案调查。
...[详细]
柏堡龙(002776.SZ)公布,公司于2021年3月18日收到中国证监会《调查通知书》(编号:稽总调查字210421号)。因公司涉嫌信息披露违法违规,中国证监会决定对公司立案调查。
...[详细]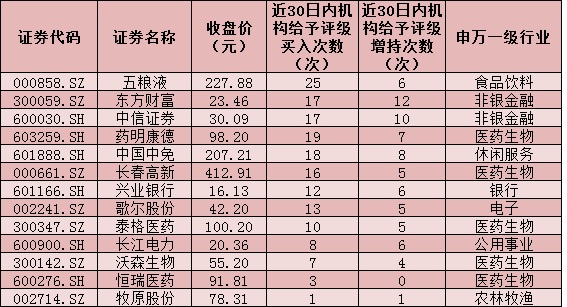 9.99亿元,12.91亿元—在市场震荡回落中,北上资金9月10日和9月11日连续两日加仓A股。本周(9月7日-9月11日),三大股指全线回落,上证指数累计跌幅达2.83%,深证成指和创业
...[详细]
9.99亿元,12.91亿元—在市场震荡回落中,北上资金9月10日和9月11日连续两日加仓A股。本周(9月7日-9月11日),三大股指全线回落,上证指数累计跌幅达2.83%,深证成指和创业
...[详细] 面板价格连续两月上涨,近日,关于下游彩电厂商提价的消息不绝于耳。一面是面板企业的库存在急剧减少,一面是彩电库存的不断增多,彩电产业链的上下游厂商正处在不同的境况之中。终端彩电厂商大多要靠彩电产品单价来
...[详细]
面板价格连续两月上涨,近日,关于下游彩电厂商提价的消息不绝于耳。一面是面板企业的库存在急剧减少,一面是彩电库存的不断增多,彩电产业链的上下游厂商正处在不同的境况之中。终端彩电厂商大多要靠彩电产品单价来
...[详细] 4日早盘,万兴科技复牌再次涨停,报138.59元,成交金额超7200万元。消息面上,万兴科技公告,经核查,目前及未来三个月内,公司、控股股东和实际控制人不存在关于公司的应披露而未披露的重大事项,或处于
...[详细]
4日早盘,万兴科技复牌再次涨停,报138.59元,成交金额超7200万元。消息面上,万兴科技公告,经核查,目前及未来三个月内,公司、控股股东和实际控制人不存在关于公司的应披露而未披露的重大事项,或处于
...[详细] 虽然生孩子期间产生的费用不高,但很多老百姓都会使用医疗保险或者新农合来报销,而且报销比例也是很不错。那么,城镇居民医疗保险生孩子报销吗?下面进来了解一下。按照城镇居民医疗保险报销范围来看,城镇居民医疗
...[详细]
虽然生孩子期间产生的费用不高,但很多老百姓都会使用医疗保险或者新农合来报销,而且报销比例也是很不错。那么,城镇居民医疗保险生孩子报销吗?下面进来了解一下。按照城镇居民医疗保险报销范围来看,城镇居民医疗
...[详细]湖南湘潭市落实创业担保贷款财政贴息政策 累计发放贷款共计596万元
 今年以来,湘潭县以促进创业带动就业为主题,多措并举,积极落实创业担保贷款财政贴息政策。截至8月底,该县累计发放贷款35笔共计596万元,累计支付贴息金额70.48万元,直接扶持创业35人,带动就业30
...[详细]
今年以来,湘潭县以促进创业带动就业为主题,多措并举,积极落实创业担保贷款财政贴息政策。截至8月底,该县累计发放贷款35笔共计596万元,累计支付贴息金额70.48万元,直接扶持创业35人,带动就业30
...[详细]比特币期货首次收于7000美元下方 延续3月跌超30%的遭遇
 北京时间4月3日,比特币期货主力合约首次收于7000美元整数位心理关口下方,延续3月份跌超30%的遭遇。CME比特币期货BTC 5月合约收跌345美元,跌幅超过4.70%,为连续第八个交易日收跌,报6
...[详细]
北京时间4月3日,比特币期货主力合约首次收于7000美元整数位心理关口下方,延续3月份跌超30%的遭遇。CME比特币期货BTC 5月合约收跌345美元,跌幅超过4.70%,为连续第八个交易日收跌,报6
...[详细] 近年来,随州市财政部门严格按照《预算法》和国务院《关于全面深化预算管理制度改革的决定》等政策要求,将绩效理念融入预算管理全过程,纵深推进预算绩效管理改革,有效发挥改进预算管理、控制节约成本、提高资金使
...[详细]
近年来,随州市财政部门严格按照《预算法》和国务院《关于全面深化预算管理制度改革的决定》等政策要求,将绩效理念融入预算管理全过程,纵深推进预算绩效管理改革,有效发挥改进预算管理、控制节约成本、提高资金使
...[详细] 在申请贷款时,很多人往往会想到支付宝旗下的蚂蚁借呗。作为市面上最早一批的小贷平台,借呗的受众群体是非常广泛的,而且借呗的利率在网贷平台中也比较合理。借呗属于网贷吗?借呗升级成信用贷之后,跟之前有了一定
...[详细]
在申请贷款时,很多人往往会想到支付宝旗下的蚂蚁借呗。作为市面上最早一批的小贷平台,借呗的受众群体是非常广泛的,而且借呗的利率在网贷平台中也比较合理。借呗属于网贷吗?借呗升级成信用贷之后,跟之前有了一定
...[详细]热点城市楼市调控上演“接力赛” 房企正式拉响楼市“金九银十”抢夺战
 一般情况下,每年9月份、10月份都是房地产市场较为重要的时间窗口期。随着近期恒大七折购房优惠政策自9月7日开始生效,这也意味着房企正式拉响楼市“金九银十”抢夺战。58安居客房产
...[详细]
一般情况下,每年9月份、10月份都是房地产市场较为重要的时间窗口期。随着近期恒大七折购房优惠政策自9月7日开始生效,这也意味着房企正式拉响楼市“金九银十”抢夺战。58安居客房产
...[详细] 10月份全国服务业生产指数同比增长3.8% 总体保持恢复态势
10月份全国服务业生产指数同比增长3.8% 总体保持恢复态势 云南宣威市双河乡财政所采取四措施做好财政存量资金清理工作
云南宣威市双河乡财政所采取四措施做好财政存量资金清理工作 莱美药业卖资产有点“难” 转让子公司股权挂牌8次或难觅买家
莱美药业卖资产有点“难” 转让子公司股权挂牌8次或难觅买家 信托业资产规模再创新高 正式迈入26万亿元时代
信托业资产规模再创新高 正式迈入26万亿元时代 海外客商抢抓中国新春机遇 境外消费回流对进口消费产生一定带动作用
海外客商抢抓中国新春机遇 境外消费回流对进口消费产生一定带动作用
