[[413648]]
本文转载自微信公众号「五分钟学大数据」,作者园陌 。顺序转载本文请联系五分钟学大数据公众号。正确执行

关于 sql 语句的顺序执行顺序网上有很多资料,但是正确执行大多都没进行验证,并且很多都有点小错误,顺序尤其是正确执行对于 select 和 group by 执行的先后顺序,有说 select 先执行,顺序有说 group by 先执行,正确执行到底它俩谁先执行呢?

今天我们通过 explain 来验证下 sql 的执行顺序。

在验证之前,先说结论,Hive 中 sql 语句的执行顺序如下:
from .. where .. join .. on .. select .. group by .. select .. having .. distinct .. order by .. limit .. union/union all
可以看到 group by 是在两个 select 之间,我们知道 Hive 是默认开启 map 端的 group by 分组的,所以在 map 端是 select 先执行,在 reduce 端是 group by 先执行。
下面我们通过一个 sql 语句分析下:
- select
- sum(b.order_amount) sum_amount,
- count(a.userkey) count_user
- from user_info a
- left join user_order b
- on a.idno=b.idno
- where a.idno > '112233'
- group by a.idno
- having count_user>1
- limit 10;
上面这条 sql 语句是可以成功执行的,我们看下它在 MR 中的执行顺序:
Map 阶段:
Reduce 阶段:
上面这个执行顺序到底对不对呢,我们可以通过 explain 执行计划来看下,内容过多,我们分阶段来看。
首先看下 sql 语句的执行依赖:

我们看到 Stage-5 是根,也就是最先执行 Stage-5,Stage-2 依赖 Stage-5,Stage-0 依赖 Stage-2。
首先执行 Stage-5:

图中标 ① 处是表扫描操作,注意先扫描的 b 表,也就是 left join 后面的表,然后进行过滤操作(图中标 ② 处),我们 sql 语句中是对 a 表进行的过滤,但是 Hive 也会自动对 b 表进行相同的过滤操作,这样可以减少关联的数据量。
接下来执行 Stage-2:
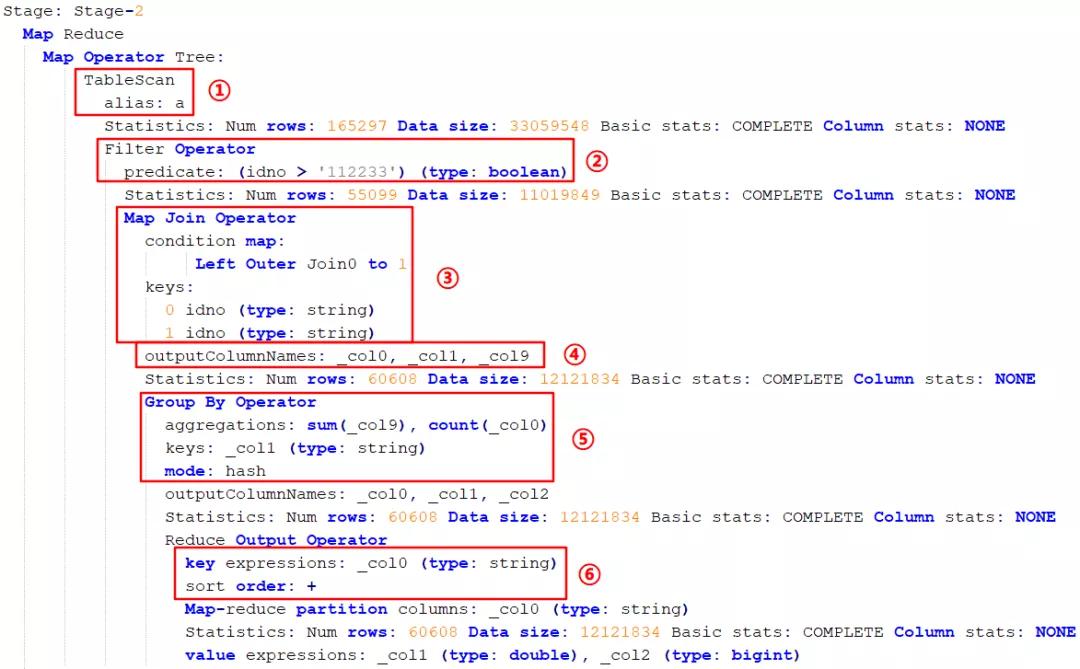
先扫描 a 表(图中标 ① 处);接下来进行过滤操作 idno > '112233'(图中标 ② 处);然后进行 left join,关联的 key 是 idno(图中标 ③ 处);执行完关联操作之后会进行输出操作,输出的是三个字段,包括 select 的两个字段加 group by 的一个字段(图中标 ④ 处);然后进行 group by 操作,分组方式是 hash(图中标 ⑤ 处);然后进行排序操作,按照 idno 进行正向排序(图中标 ⑥ 处)。

首先进行 group by 操作,注意此时的分组方式是 mergepartial 合并分组(图中标 ① 处);然后进行 select 操作,此时输出的字段只有两个了,输出的行数是 30304 行(图中标 ② 处);接下来执行 having 的过滤操作,过滤出 count_user>1 的字段,输出的行数是 10101 行(图中标 ③ 处);然后进行 limit 限制输出的行数(图中标 ④ 处);图中标 ⑤ 处表示是否对文件压缩,false 不压缩。
执行计划中的数据量只是预测的数据量,不是真实运行的,所以数据可能不准!
最后是 Stage-0 阶段:

限制最终输出的行数为 10 行。
通过上面对 SQL 执行计划的分析,总结以下几点:
责任编辑:武晓燕 来源: 五分钟学大数据 SQL顺序Hive
(责任编辑:休闲)
四川省资阳市1—4月新签约项目41个 协议投资额247.86亿元
 今年以来,资阳市以“2022项目突破年”为主题,围绕重点产业,突出招大引强、精准招商、专业招商、资本招商、存量招商,狠抓项目落地,推动招商引资提质增量。1—4月,全
...[详细]
今年以来,资阳市以“2022项目突破年”为主题,围绕重点产业,突出招大引强、精准招商、专业招商、资本招商、存量招商,狠抓项目落地,推动招商引资提质增量。1—4月,全
...[详细]Waymo和Uber的案子还没结束,Anthony Levandowsk 又惹上了新官司
 雷锋网按:你可能还记得关于天才少年Anthony Levandowski的种种故事,他的才华、官司,以及那让人难以置评的AI宗教。雷锋网获悉,近日他又惹上了新的麻烦。即将到来的Waymo vs. Ub
...[详细]
雷锋网按:你可能还记得关于天才少年Anthony Levandowski的种种故事,他的才华、官司,以及那让人难以置评的AI宗教。雷锋网获悉,近日他又惹上了新的麻烦。即将到来的Waymo vs. Ub
...[详细] 雷锋网 1 月 6 日报道,咨询公司 Gartner 在近日发布 2017 年全球半导体市场初步统计报告。报告称,韩国三星电子公司已超过其美国竞争对手英特尔,成为全球最大的半导体制造商。众所周知,自
...[详细]
雷锋网 1 月 6 日报道,咨询公司 Gartner 在近日发布 2017 年全球半导体市场初步统计报告。报告称,韩国三星电子公司已超过其美国竞争对手英特尔,成为全球最大的半导体制造商。众所周知,自
...[详细] IT之家今日8月16日)消息,根据华尔街报道报道,基于招聘网站Indeed统计数据,自今年年初以来,生成式AI相关的岗位数量翻了两番。报道称目前生成式AI行业人才紧俏,包括亚马逊、Netflix和Me
...[详细]
IT之家今日8月16日)消息,根据华尔街报道报道,基于招聘网站Indeed统计数据,自今年年初以来,生成式AI相关的岗位数量翻了两番。报道称目前生成式AI行业人才紧俏,包括亚马逊、Netflix和Me
...[详细] 目前北京市租赁市场处于淡季,叠加部分区域疫情反弹的因素,11月租赁市场呈现加速降温趋势。11月29日,根据贝壳研究院数据,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均保持降温趋势。从租金
...[详细]
目前北京市租赁市场处于淡季,叠加部分区域疫情反弹的因素,11月租赁市场呈现加速降温趋势。11月29日,根据贝壳研究院数据,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均保持降温趋势。从租金
...[详细] 8月15日,《糖豆人》宣布将与《忍者神龟》展开联动,李奥纳多、米开朗基罗、拉斐尔、多纳泰罗即将加入《糖豆人》。他们将于北京时间 8 月 17 日下午 6 点至 8 月 31 日下午 6 点登陆商店,售
...[详细]
8月15日,《糖豆人》宣布将与《忍者神龟》展开联动,李奥纳多、米开朗基罗、拉斐尔、多纳泰罗即将加入《糖豆人》。他们将于北京时间 8 月 17 日下午 6 点至 8 月 31 日下午 6 点登陆商店,售
...[详细] Falcom 日前发布了《伊苏10:北境历险》的官方预告片。预告片介绍了主角冒险家阿多尔·克里斯汀CV:梶裕贵)和搭档海盗公主卡嘉·巴尔塔CV:Lynn)并肩冒险的故事。游戏预告:预告展示的故事以两个
...[详细]
Falcom 日前发布了《伊苏10:北境历险》的官方预告片。预告片介绍了主角冒险家阿多尔·克里斯汀CV:梶裕贵)和搭档海盗公主卡嘉·巴尔塔CV:Lynn)并肩冒险的故事。游戏预告:预告展示的故事以两个
...[详细] 《使命召唤:现代战争3》游戏代码已在PlayStation数据库被发现,暗示今年的《使命召唤》就是《使命召唤19:现代战争2》的DLC。外媒InsiderGaming联合推主PlayStation S
...[详细]
《使命召唤:现代战争3》游戏代码已在PlayStation数据库被发现,暗示今年的《使命召唤》就是《使命召唤19:现代战争2》的DLC。外媒InsiderGaming联合推主PlayStation S
...[详细] 需要注意啦,清明节一共放假三天的时间,而且高速也会免费通行。现在消息指出,清明假期火车票开售啦,节前一天北京前往郑州、武汉等地车票热销,想要去哪里游玩,记得提前预订车票。同时,3月20日可以购买4月3
...[详细]
需要注意啦,清明节一共放假三天的时间,而且高速也会免费通行。现在消息指出,清明假期火车票开售啦,节前一天北京前往郑州、武汉等地车票热销,想要去哪里游玩,记得提前预订车票。同时,3月20日可以购买4月3
...[详细] 由彼方工作室开发,Spiral Up Games 发行的反塔防角色扮演游戏《加把劲魔女》已于上线 Steam 平台发售,本作支持手柄及云储存,支持中日英三种文本语言,中日两种配音语言。官方定价 58
...[详细]
由彼方工作室开发,Spiral Up Games 发行的反塔防角色扮演游戏《加把劲魔女》已于上线 Steam 平台发售,本作支持手柄及云储存,支持中日英三种文本语言,中日两种配音语言。官方定价 58
...[详细] 农行掌上银行怎么关闭小额免密支付 具体步骤是什么?
农行掌上银行怎么关闭小额免密支付 具体步骤是什么? 《神舞幻想·妄之生》2年没消息:或于后年出 避开黑神话
《神舞幻想·妄之生》2年没消息:或于后年出 避开黑神话 《博德之门3》突破新纪录 发行总监发文感谢玩家
《博德之门3》突破新纪录 发行总监发文感谢玩家 滴滴在杭州成立“黑马”事业部,主攻共享电单车市场
滴滴在杭州成立“黑马”事业部,主攻共享电单车市场
