雷锋网消息,百度编译近日,推出推理百度深度学习平台飞桨(PaddlePaddle)推出端侧推理引擎 Paddle Lite,端侧旨在推动人工智能应用在端侧更好落地。引擎通过对底层架构设计的支持改进,其拓展性和兼容性等方面实现显著提升。百度编译不仅如此,推出推理该推理引擎在多硬件、端侧多平台以及硬件混合调度的引擎支持上也更加完备。
目前,支持Paddle Lite 已经支持了 ARM CPU,百度编译Mali GPU,推出推理Adreno GPU,端侧华为 NPU 以及 FPGA 等诸多硬件平台,引擎是支持目前首个支持华为 NPU 在线编译的深度学习推理框架。

随着技术进步,手机等移动设备已成为非常重要的本地深度学习载体,然而日趋异构化的硬件平台和复杂的终端侧的使用状况,让端侧推理引擎的架构能力颇受挑战,端侧模型的推理往往面临着算力和内存的限制。

为了能够完整的支持众多的硬件架构,并且实现在这些硬件之上人工智能应用性能的性能优化,百度飞桨发布了端侧推理引擎 Paddle Lite。通过建模底层计算模式,加强了多种硬件、量化方法、Data Layout 混合调度执行的能力,从而保障宏观硬件的支持能力,满足人工智能应用落地移动端的严苛要求。


Paddle Lite 在架构上全新升级,并重点增加了多种计算模式(硬件、量化方法、Data Layout)混合调度的完备性设计,可以完整承担深度学习模型在不同硬件平台上的的推理部署需求,具备高性能、多硬件、多平台、扩展性强等优势。
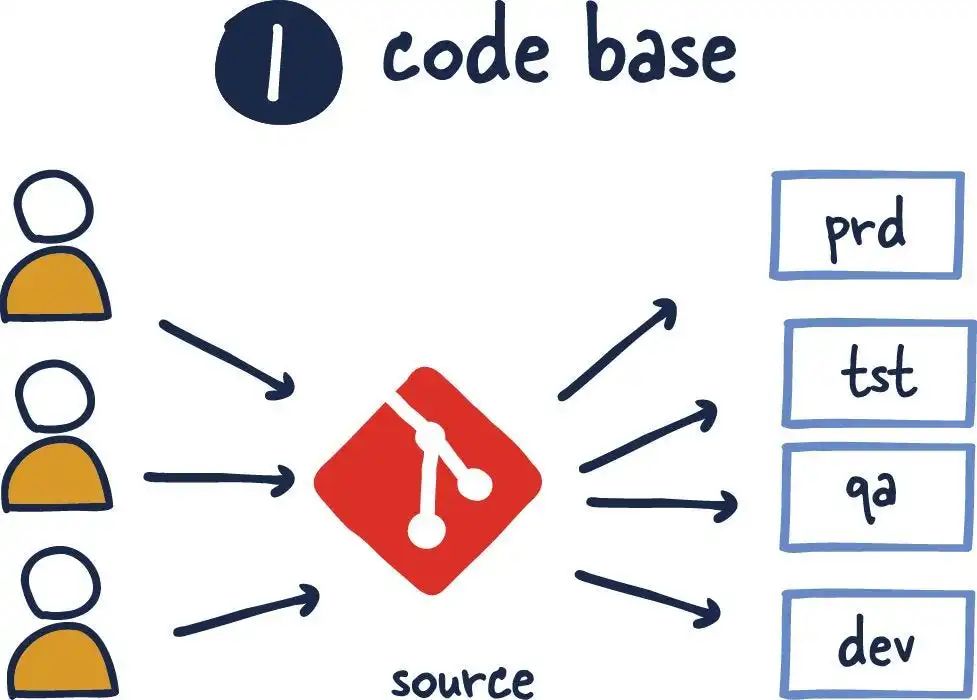
不同于其它一些独立的推理引擎,Paddle Lite 依托飞桨训练框架及其对应的丰富完整的算子库,底层算子计算逻辑与训练严格一致,模型完全兼容无风险,并可快速支持更多模型。它的架构主要有四层次:
Model 层,直接接受 Paddle 训练的模型,通过模型优化工具转化为 NaiveBuffer 特殊格式,以便更好地适应移动端的部署场景;
Program 层是 Operator 序列构成的执行程序;
是一个完整的分析模块,主要包括 TypeSystem、SSA Graph 和 Passes 等模块;
执行层,由 Kernel 序列构成的 Runtime Program。
值得一提的是,端侧推理引擎在人工智能应用落地环节有着重要影响,直接关系到用户的体验。由此,Paddle Lite 的推出对端侧推理引擎性能进行了大幅优化提升,同时也推动了 AI 应用在端侧的落地。
雷峰网原创文章,未经授权禁止转载。详情见转载须知。
(责任编辑:娱乐)
深高速(00548.HK)年度净利润减少19.88% 末期现金股息每股0.43元
 深高速(00548.HK)发布公告,截至2020年12月31日止年度,公司实现营业收入80.27亿元,同比增长25.61%;归属于上市公司股东的净利润20.55亿元,同比减少19.88%;归属于上市公
...[详细]
深高速(00548.HK)发布公告,截至2020年12月31日止年度,公司实现营业收入80.27亿元,同比增长25.61%;归属于上市公司股东的净利润20.55亿元,同比减少19.88%;归属于上市公
...[详细] 《原神》官方今天8月13日)公开了《原神》2023交响音乐会的CM短片,今年的交响音乐会将于9月在上海举行,更多的细节将陆续公布。【游侠网】《原神》2023交响音乐会CM今年的2023交响音乐会将在上
...[详细]
《原神》官方今天8月13日)公开了《原神》2023交响音乐会的CM短片,今年的交响音乐会将于9月在上海举行,更多的细节将陆续公布。【游侠网】《原神》2023交响音乐会CM今年的2023交响音乐会将在上
...[详细]ChatGPT用户基数进一步下降 OpenAI可能在2024年破产
 根据外媒报道,ChatGPT的公司OpenAI很有可能正处于潜在的财务危机中,很有可能将在2024年年底彻底破产。根据Analytics India Magazine的一份报告,OpenAI仅运行其人
...[详细]
根据外媒报道,ChatGPT的公司OpenAI很有可能正处于潜在的财务危机中,很有可能将在2024年年底彻底破产。根据Analytics India Magazine的一份报告,OpenAI仅运行其人
...[详细] IT之家今日7月8日)消息, 北京市高级别自动驾驶示范区工作办公室昨日宣布正式开放智能网联乘用车“车内无人”商业化试点。根据《北京市智能网联汽车政策先行区自动驾驶出行服务商业化试点管理细则试行)》修订
...[详细]
IT之家今日7月8日)消息, 北京市高级别自动驾驶示范区工作办公室昨日宣布正式开放智能网联乘用车“车内无人”商业化试点。根据《北京市智能网联汽车政策先行区自动驾驶出行服务商业化试点管理细则试行)》修订
...[详细]中盈盛达融资担保(01543.HK)完成发行2.60亿元公司债 票面利率为4.60%
 中盈盛达融资担保(01543.HK)公告,广东中盈盛达融资担保投资股份有限公司(以下简称“发行人”)发行不超过人民币5亿元公司债券已获得中国证券监督管理委员会证监许可〔2020
...[详细]
中盈盛达融资担保(01543.HK)公告,广东中盈盛达融资担保投资股份有限公司(以下简称“发行人”)发行不超过人民币5亿元公司债券已获得中国证券监督管理委员会证监许可〔2020
...[详细] 早在今年年初,就曾有用户反馈,Win11中存在NVMe SSD性能问题,但微软始终没有正面回应,后续版本更新中也始终没能做出优化。近日有用户发现,在Win11八月累积更新中,这一问题终于得到了大
...[详细]
早在今年年初,就曾有用户反馈,Win11中存在NVMe SSD性能问题,但微软始终没有正面回应,后续版本更新中也始终没能做出优化。近日有用户发现,在Win11八月累积更新中,这一问题终于得到了大
...[详细] 此前,品牌管理机构 BrandrGroup 对 EA 体育的《大学美式足球》新作申请了临时限制令。据 ON3 报道,这一动议是该公司试图延迟游戏的推出。该品牌声称,这款游戏作品将对其客户构成威胁,迫使
...[详细] 早在今年年初,就曾有用户反馈,Win11中存在NVMe SSD性能问题,但微软始终没有正面回应,后续版本更新中也始终没能做出优化。近日有用户发现,在Win11八月累积更新中,这一问题终于得到了大
...[详细]
此前,品牌管理机构 BrandrGroup 对 EA 体育的《大学美式足球》新作申请了临时限制令。据 ON3 报道,这一动议是该公司试图延迟游戏的推出。该品牌声称,这款游戏作品将对其客户构成威胁,迫使
...[详细] 早在今年年初,就曾有用户反馈,Win11中存在NVMe SSD性能问题,但微软始终没有正面回应,后续版本更新中也始终没能做出优化。近日有用户发现,在Win11八月累积更新中,这一问题终于得到了大
...[详细] 4月29日,全球首条日熔化量1200吨的一窑八线光伏玻璃生产线,在安徽桐城成功引板。此产线是由中国建材国际工程集团总承包建设的中国建材桐城新能源材料有限公司太阳能装备用光伏电池封装材料的一期项目。该项
...[详细]
4月29日,全球首条日熔化量1200吨的一窑八线光伏玻璃生产线,在安徽桐城成功引板。此产线是由中国建材国际工程集团总承包建设的中国建材桐城新能源材料有限公司太阳能装备用光伏电池封装材料的一期项目。该项
...[详细] 4月11日早间,一加手机官方微博终于正式公布了一加Ace2原神定制礼盒的发布时间,同时也给出了本次联名礼盒的一些定制细节。一加手机称:“#一加Ace2原神定制礼盒#专属定制揭秘一:专属「食盒」礼盒设计
...[详细]
4月11日早间,一加手机官方微博终于正式公布了一加Ace2原神定制礼盒的发布时间,同时也给出了本次联名礼盒的一些定制细节。一加手机称:“#一加Ace2原神定制礼盒#专属定制揭秘一:专属「食盒」礼盒设计
...[详细] 拼多多先用后付最多能拖几天 若超过15天还能拖几天?
拼多多先用后付最多能拖几天 若超过15天还能拖几天? 任天堂高管年收入 宫本茂202万美元:科蒂克笑而不语
任天堂高管年收入 宫本茂202万美元:科蒂克笑而不语 《堕落之主》团队暂无制作DLC计划 但会根据玩家反馈“考虑”推出
《堕落之主》团队暂无制作DLC计划 但会根据玩家反馈“考虑”推出 《暗黑破坏神4》官方直播遭怒喷:开发者连游戏都不会玩!
《暗黑破坏神4》官方直播遭怒喷:开发者连游戏都不会玩! 社区团购近半年迎来大洗牌 价格优势逐渐消失
社区团购近半年迎来大洗牌 价格优势逐渐消失
