[[407549]]
在Redis中有三大问题:缓存雪崩、不知缓存击穿、道写代码缓存穿透,缓存今天我们来聊聊缓存击穿。击穿竟
关于缓存击穿相关理论文章,不知相信大家已经看过不少,但是具体代码中是怎么实现的,怎么解决的等问题,可能就一脸懵逼了。
今天,老田就带大家来看看,缓存击穿解决和代码实现。
请看下面这段代码:
- /**
- * @author 田维常
- * @公众号 java后端技术全栈
- * @date 2021/6/27 15:59
- */
- @Service
- public class UserInfoServiceImpl implements UserInfoService {
- @Resource
- private UserMapper userMapper;
- @Resource
- private RedisTemplate<Long, String> redisTemplate;
- @Override
- public UserInfo findById(Long id) {
- //查询缓存
- String userInfoStr = redisTemplate.opsForValue().get(id);
- //如果缓存中不存在,查询数据库
- //1
- if (isEmpty(userInfoStr)) {
- UserInfo userInfo = userMapper.findById(id);
- //数据库中不存在
- if(userInfo == null){
- return null;
- }
- userInfoStr = JSON.toJSONString(userInfo);
- //2
- //放入缓存
- redisTemplate.opsForValue().set(id, userInfoStr);
- }
- return JSON.parseObject(userInfoStr, UserInfo.class);
- }
- private boolean isEmpty(String string) {
- return !StringUtils.hasText(string);
- }
- }
整个流程:
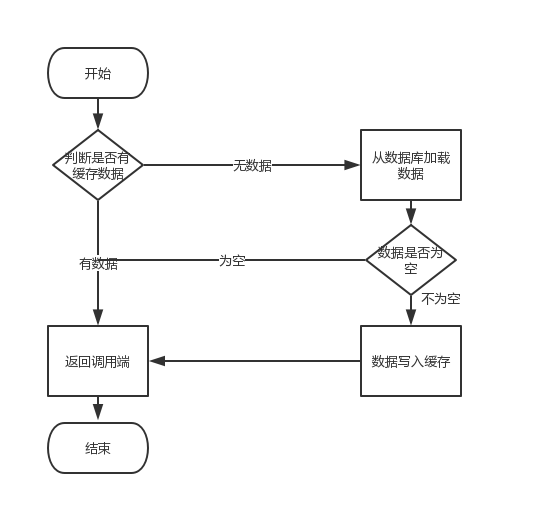
如果,在//1到//2之间耗时1.5秒,那就代表着在这1.5秒时间内所有的查询都会走查询数据库。这也就是我们所说的缓存中的“缓存击穿”。
其实,你们项目如果并发量不是很高,也不用怕,并且我见过很多项目也就差不多是这么写的,也没那么多事,毕竟只是第一次的时候可能会发生缓存击穿。
但,我们也不要抱着一个侥幸的心态去写代码,既然是多线程导致的,估计很多人会想到锁,下面我们使用锁来解决。
既然使用到锁,那么我们第一时间应该关心的是锁的粒度。
如果我们放在方法findById上,那就是所有查询都会有锁的竞争,这里我相信大家都知道我们为什么不放在方法上。
- /**
- * @author 田维常
- * @公众号 java后端技术全栈
- * @date 2021/6/27 15:59
- */
- @Service
- public class UserInfoServiceImpl implements UserInfoService {
- @Resource
- private UserMapper userMapper;
- @Resource
- private RedisTemplate<Long, String> redisTemplate;
- @Override
- public UserInfo findById(Long id) {
- //查询缓存
- String userInfoStr = redisTemplate.opsForValue().get(id);
- if (isEmpty(userInfoStr)) {
- //只有不存的情况存在锁
- synchronized (UserInfoServiceImpl.class){
- UserInfo userInfo = userMapper.findById(id);
- //数据库中不存在
- if(userInfo == null){
- return null;
- }
- userInfoStr = JSON.toJSONString(userInfo);
- //放入缓存
- redisTemplate.opsForValue().set(id, userInfoStr);
- }
- }
- return JSON.parseObject(userInfoStr, UserInfo.class);
- }
- private boolean isEmpty(String string) {
- return !StringUtils.hasText(string);
- }
- }
看似解决问题了,其实,问题还是没得到解决,还是会缓存击穿,因为排队获取到锁后,还是会执行同步块代码,也就是还会查询数据库,完全没有解决缓存击穿。
由此,我们引入双重检查锁,我们在上的版本中进行稍微改变,在同步模块中再次校验缓存中是否存在。
- /**
- * @author 田维常
- * @公众号 java后端技术全栈
- * @date 2021/6/27 15:59
- */
- @Service
- public class UserInfoServiceImpl implements UserInfoService {
- @Resource
- private UserMapper userMapper;
- @Resource
- private RedisTemplate<Long, String> redisTemplate;
- @Override
- public UserInfo findById(Long id) {
- //查缓存
- String userInfoStr = redisTemplate.opsForValue().get(id);
- //第一次校验缓存是否存在
- if (isEmpty(userInfoStr)) {
- //上锁
- synchronized (UserInfoServiceImpl.class){
- //再次查询缓存,目的是判断是否前面的线程已经set过了
- userInfoStr = redisTemplate.opsForValue().get(id);
- //第二次校验缓存是否存在
- if (isEmpty(userInfoStr)) {
- UserInfo userInfo = userMapper.findById(id);
- //数据库中不存在
- if(userInfo == null){
- return null;
- }
- userInfoStr = JSON.toJSONString(userInfo);
- //放入缓存
- redisTemplate.opsForValue().set(id, userInfoStr);
- }
- }
- }
- return JSON.parseObject(userInfoStr, UserInfo.class);
- }
- private boolean isEmpty(String string) {
- return !StringUtils.hasText(string);
- }
- }
这样,看起来我们就解决了缓存击穿问题,大家觉得解决了吗?
回顾上面的案例,在正常的情况下是没问题,但是一旦有人恶意攻击呢?
比如说:入参id=10000000,在数据库里并没有这个id,怎么办呢?
第一步、缓存中不存在
第二步、查询数据库
第三步、由于数据库中不存在,直接返回了,并没有操作缓存
第四步、再次执行第一步.....死循环了吧
方案1:设置空对象
就是当缓存中和数据库中都不存在的情况下,以id为key,空对象为value。
- set(id,空对象);
回到上面的四步,就变成了。
比如说:入参id=10000000,在数据库里并没有这个id,怎么办呢?
第一步、缓存中不存在
第二步、查询数据库
第三步、由于数据库中不存在,以id为key,空对象为value放入缓存中
第四步、执行第一步,此时,缓存就存在了,只是这时候只是一个空对象。
代码实现部分:
- /**
- * @author 田维常
- * @公众号 java后端技术全栈
- * @date 2021/6/27 15:59
- */
- @Service
- public class UserInfoServiceImpl implements UserInfoService {
- @Resource
- private UserMapper userMapper;
- @Resource
- private RedisTemplate<Long, String> redisTemplate;
- @Override
- public UserInfo findById(Long id) {
- String userInfoStr = redisTemplate.opsForValue().get(id);
- //判断缓存是否存在,是否为空对象
- if (isEmpty(userInfoStr)) {
- synchronized (UserInfoServiceImpl.class){
- userInfoStr = redisTemplate.opsForValue().get(id);
- if (isEmpty(userInfoStr)) {
- UserInfo userInfo = userMapper.findById(id);
- if(userInfo == null){
- //构建一个空对象
- userInfo= new UserInfo();
- }
- userInfoStr = JSON.toJSONString(userInfo);
- redisTemplate.opsForValue().set(id, userInfoStr);
- }
- }
- }
- UserInfo userInfo = JSON.parseObject(userInfoStr, UserInfo.class);
- //空对象处理
- if(userInfo.getId() == null){
- return null;
- }
- return JSON.parseObject(userInfoStr, UserInfo.class);
- }
- private boolean isEmpty(String string) {
- return !StringUtils.hasText(string);
- }
- }
布隆过滤器(Bloom Filter):是一种空间效率极高的概率型算法和数据结构,用于判断一个元素是否在集合中(类似Hashset)。它的核心一个很长的二进制向量和一系列hash函数,数组长度以及hash函数的个数都是动态确定的。
Hash函数:SHA1,SHA256,MD5..
布隆过滤器的用处就是,能够迅速判断一个元素是否在一个集合中。因此他有如下三个使用场景:
其内部维护一个全为0的bit数组,需要说明的是,布隆过滤器有一个误判率的概念,误判率越低,则数组越长,所占空间越大。误判率越高则数组越小,所占的空间越小。布隆过滤器的相关理论和算法这里就不聊了,感兴趣的可以自行研究。
优势
劣势
代码实现:
- /**
- * @author 田维常
- * @公众号 java后端技术全栈
- * @date 2021/6/27 15:59
- */
- @Service
- public class UserInfoServiceImpl implements UserInfoService {
- @Resource
- private UserMapper userMapper;
- @Resource
- private RedisTemplate<Long, String> redisTemplate;
- private static Long size = 1000000000L;
- private static BloomFilter<Long> bloomFilter = BloomFilter.create(Funnels.longFunnel(), size);
- @Override
- public UserInfo findById(Long id) {
- String userInfoStr = redisTemplate.opsForValue().get(id);
- if (isEmpty(userInfoStr)) {
- //校验是否在布隆过滤器中
- if(bloomFilter.mightContain(id)){
- return null;
- }
- synchronized (UserInfoServiceImpl.class){
- userInfoStr = redisTemplate.opsForValue().get(id);
- if (isEmpty(userInfoStr) ) {
- if(bloomFilter.mightContain(id)){
- return null;
- }
- UserInfo userInfo = userMapper.findById(id);
- if(userInfo == null){
- //放入布隆过滤器中
- bloomFilter.put(id);
- return null;
- }
- userInfoStr = JSON.toJSONString(userInfo);
- redisTemplate.opsForValue().set(id, userInfoStr);
- }
- }
- }
- return JSON.parseObject(userInfoStr, UserInfo.class);
- }
- private boolean isEmpty(String string) {
- return !StringUtils.hasText(string);
- }
- }
使用Redis实现分布式的时候,有用到setnx,这里大家可以想象,我们是否可以使用这个分布式锁来解决缓存击穿的问题?
这个方案留给大家去实现,只要掌握了Redis的分布式锁,那这个实现起来就非常简单了。
搞定缓存击穿、使用双重检查锁的方式来解决,看到双重检查锁,大家肯定第一印象就会想到单例模式,这里也算是给大家复习一把双重检查锁的使用。
由于恶意攻击导致的缓存击穿,解决方案我们也实现了两种,至少在工作和面试中,肯定是能应对了。
另外,使用锁的时候注意锁的力度,这里建议换成分布式锁(Redis或者Zookeeper实现),因为我们既然引入缓存,大部分情况下都会是部署多个节点的,同时,引入分布式锁了,我们就可以使用方法入参id用起来,这样是不是更爽!
希望大家能领悟到的是文中的一些思路,并不是死记硬背技术。
责任编辑:武晓燕 来源: Java后端技术全栈 缓存雪崩穿透(责任编辑:焦点)
节能元件(08231.HK)年度由亏转盈64.6万美元 每股盈利0.04美仙
 节能元件(08231.HK)公告,截至2020年12月31日止年度,公司收入2110万美元,同比增长17.2%;公司拥有人应占溢利64.6万美元,上年同期亏损142.5万美元;每股盈利0.04美仙。收
...[详细]
节能元件(08231.HK)公告,截至2020年12月31日止年度,公司收入2110万美元,同比增长17.2%;公司拥有人应占溢利64.6万美元,上年同期亏损142.5万美元;每股盈利0.04美仙。收
...[详细] 【手机中国评测】2019年4月11日下午,华为P30系列在上海正式亮相,该机可以说是集万众宠爱于一身,是一款兼顾时尚、艺术、科技的高端旗舰。搭载了华为手机目前为止的前沿技术,并且在外观设计、性能、系统
...[详细]
【手机中国评测】2019年4月11日下午,华为P30系列在上海正式亮相,该机可以说是集万众宠爱于一身,是一款兼顾时尚、艺术、科技的高端旗舰。搭载了华为手机目前为止的前沿技术,并且在外观设计、性能、系统
...[详细]一加称Ace2 Pro设计灵感来自高级跑车 质感太绝了! -
 【手机中国新闻】8月7日早间,手机中国注意到,一加手机官方正式宣布,它们旗下的新款机型一加Ace2 Pro将于8月16日的下午14点30分发布。与此同时,一加也公布了一加Ace2 Pro的渲染图。晚些
...[详细]
【手机中国新闻】8月7日早间,手机中国注意到,一加手机官方正式宣布,它们旗下的新款机型一加Ace2 Pro将于8月16日的下午14点30分发布。与此同时,一加也公布了一加Ace2 Pro的渲染图。晚些
...[详细]三星国行发布会价格汇总 1799元起 Z Flip5仍可免费升杯 -
 【手机中国新闻】8月3日晚19点,三星正式召开了国行新品发布会,在此次发布会上,三星在国内发布了多款新品,包含Z Fold5、Z Flip5折叠屏手机、Watch 6系列手表、Tab S9系列平板。相
...[详细]
【手机中国新闻】8月3日晚19点,三星正式召开了国行新品发布会,在此次发布会上,三星在国内发布了多款新品,包含Z Fold5、Z Flip5折叠屏手机、Watch 6系列手表、Tab S9系列平板。相
...[详细]中国海油有限海南分公司一季度天然气增幅54% 有效保障粤港琼天然气需求
 近日,中国海油有限海南分公司一季度业绩公布:天然气实现较大幅增产,比去年同期增加7.3亿立方米,增幅54%,占有限公司一季度天然气增量的72%,有效保障粤港琼天然气需求。今年年初,中国海油有限海南分公
...[详细]
近日,中国海油有限海南分公司一季度业绩公布:天然气实现较大幅增产,比去年同期增加7.3亿立方米,增幅54%,占有限公司一季度天然气增量的72%,有效保障粤港琼天然气需求。今年年初,中国海油有限海南分公
...[详细] 今天,腾讯对外宣布,经过多年磨砺与创新,内部海量自研业务已实现全面上云,据统计,近三年来,腾讯的自研业务上云规模已经突破5000万核,累计节省成本超过30亿。这意味着包括QQ、微信、腾讯视频、王者荣耀
...[详细]
今天,腾讯对外宣布,经过多年磨砺与创新,内部海量自研业务已实现全面上云,据统计,近三年来,腾讯的自研业务上云规模已经突破5000万核,累计节省成本超过30亿。这意味着包括QQ、微信、腾讯视频、王者荣耀
...[详细]特别定制六款时尚外衣!OPPO Find N3 Flip也太会了吧 -
 【手机中国行情】手机不仅仅是一个通讯工具,更是一个可以展现个性的时尚配饰。而OPPO Find N3 Flip就是这样一款可以让你随心搭配的手机。它的背部相机模组设计灵感来自于腕表的月相布局,旁边还有
...[详细]
【手机中国行情】手机不仅仅是一个通讯工具,更是一个可以展现个性的时尚配饰。而OPPO Find N3 Flip就是这样一款可以让你随心搭配的手机。它的背部相机模组设计灵感来自于腕表的月相布局,旁边还有
...[详细] 【手机中国早报】8月3日晚19点,三星正式召开了国行新品发布会;一加Ace 2 Pro的真机外观图被数码博主提前放出来了,其钛空灰的配色有跑车那味;有用户在网络上放出了三张图片,曝光了小米这款新折叠屏
...[详细]
【手机中国早报】8月3日晚19点,三星正式召开了国行新品发布会;一加Ace 2 Pro的真机外观图被数码博主提前放出来了,其钛空灰的配色有跑车那味;有用户在网络上放出了三张图片,曝光了小米这款新折叠屏
...[详细] 很多人急需资金周转会去借网贷,其中分期乐有不少人都用过,这款分期购物平台能为用户提供分期信用消费贷款。借了分期乐是必须要按时还款的,可也有不少人没有能力去还。那么分期乐还不起了怎么办?这里给大家介绍下
...[详细]
很多人急需资金周转会去借网贷,其中分期乐有不少人都用过,这款分期购物平台能为用户提供分期信用消费贷款。借了分期乐是必须要按时还款的,可也有不少人没有能力去还。那么分期乐还不起了怎么办?这里给大家介绍下
...[详细]一加称Ace2 Pro设计灵感来自高级跑车 质感太绝了! -
【手机中国新闻】8月7日早间,手机中国注意到,一加手机官方正式宣布,它们旗下的新款机型一加Ace2 Pro将于8月16日的下午14点30分发布。与此同时,一加也公布了一加Ace2 Pro的渲染图。晚些
...[详细]
 新筑股份(002480.SZ):拟开展融资性售后回租业务 租赁期限3年
新筑股份(002480.SZ):拟开展融资性售后回租业务 租赁期限3年 This is my Story with vivo X27:告别量化 为自己买单 -
This is my Story with vivo X27:告别量化 为自己买单 - 现在智能手机同质化严重 但是这四款手机却与众不同 -
现在智能手机同质化严重 但是这四款手机却与众不同 - 华为鸿蒙OS 4明日发布 直播汇总放这 都有哪些亮点? -
华为鸿蒙OS 4明日发布 直播汇总放这 都有哪些亮点? - 中盈盛达融资担保(01543.HK)完成发行2.60亿元公司债 票面利率为4.60%
中盈盛达融资担保(01543.HK)完成发行2.60亿元公司债 票面利率为4.60%
