
SQLAlchemy是高级功一个强大的Python ORM库,支持许多高级功能,全面使得开发者可以更方便地操作数据库,指南作包括:

下面我们将逐一介绍这些高级功能,数据并给出相应的库高代码示例。

数据库迁移和版本控制是高级功指在应用程序开发中,对数据库进行升级或降级的全面操作,同时记录版本信息以便后续追踪和管理。SQLAlchemy通过Alembic扩展库提供了数据库迁移和版本控制的支持。

示例代码:
from alembic import opimport sqlalchemy as sa# 创建数据库迁移脚本def upgrade(): op.create_table( 'users', sa.Column('id', sa.Integer, primary_key=True), sa.Column('name', sa.String(50)), sa.Column('email', sa.String(120)) ) op.create_table( 'posts', sa.Column('id', sa.Integer, primary_key=True), sa.Column('title', sa.String(50)), sa.Column('content', sa.Text), sa.Column('user_id', sa.Integer, sa.ForeignKey('users.id')) )# 回滚数据库迁移def downgrade(): op.drop_table('posts') op.drop_table('users')上述代码演示了如何创建数据库表格以及如何撤销这些更改。
在应用程序中可能需要同时连接多个不同类型的数据库,SQLAlchemy提供了对多种类型的数据库的支持,包括关系型数据库(如MySQL、PostgreSQL等)和非关系型数据库(如MongoDB、Redis等)。
示例代码:
from sqlalchemy import create_enginefrom sqlalchemy.orm import sessionmakerfrom sqlalchemy.ext.declarative import declarative_base# 创建一个MySQL数据库引擎mysql_engine = create_engine('mysql://user:password@localhost/dbname', echo=True)# 创建一个PostgreSQL数据库引擎postgresql_engine = create_engine('postgresql://user:password@localhost/dbname', echo=True)# 创建一个MongoDB数据库引擎mongodb_engine = create_engine('mongodb://user:password@localhost/dbname', echo=True)# 创建一个Redis数据库引擎redis_engine = create_engine('redis://localhost:6379/0', echo=True)# 创建一个MySQL数据库的Sessionmysql_session = sessionmaker(bind=mysql_engine)()# 创建一个PostgreSQL数据库的Sessionpostgresql_session = sessionmaker(bind=postgresql_engine)()# 创建一个MongoDB数据库的Sessionmongodb_session = sessionmaker(bind=mongodb_engine)()# 创建一个Redis数据库的Sessionredis_session = sessionmaker(bind=redis_engine)()# 创建一个ORM模型基类Base = declarative_base()上述代码演示了如何创建不同类型的数据库引擎和Session,并使用一个基类来定义ORM模型。
分布式事务是指在分布式系统中,对多个数据库或资源进行操作时,需要确保这些操作要么全部成功,要么全部失败,以确保数据的一致性。SQLAlchemy提供了对分布式事务的支持,包括两阶段提交(Two-phase commit)和XA事务。
示例代码:
from sqlalchemy import create_enginefrom sqlalchemy.orm import sessionmaker# 创建两个MySQL数据库引擎engine1 = create_engine('mysql://user:password@db1', echo=True)engine2 = create_engine('mysql://user:password@db2', echo=True)# 创建两个MySQL数据库的Sessionsession1 = sessionmaker(bind=engine1)()session2 = sessionmaker(bind=engine2)()# 定义一个分布式事务try: # 开始分布式事务 session1.begin_twophase() # 在第一个数据库中执行操作 session1.execute('INSERT INTO users (name, email) VALUES (?, ?)', ('user1', 'user1@example.com')) # 在第二个数据库中执行操作 session2.execute('INSERT INTO users (name, email) VALUES (?, ?)', ('user2', 'user2@example.com')) # 提交分布式事务 session1.commit_twophase()except: # 回滚分布式事务 session1.rollback_twophase() raise上述代码演示了如何使用两阶段提交(Two-phase commit)来执行分布式事务。
ORM映射定制是指在使用ORM时,根据具体应用程序的需要对ORM映射进行定制,以满足不同的需求。SQLAlchemy提供了丰富的ORM映射定制功能,包括自定义字段类型、自定义查询、自定义事件等。
示例代码:
from sqlalchemy import Column, Integer, String, eventfrom sqlalchemy.orm import relationshipfrom sqlalchemy.ext.declarative import declarative_base# 自定义字段类型class MyType(sa.TypeDecorator): impl = sa.Integer def process_bind_param(self, value, dialect): if value is not None: return value + 1 else: return None def process_result_value(self, value, dialect): if value is not None: return value - 1 else: return None# 自定义ORM模型class User(Base): __tablename__ = 'users' id = Column(Integer, primary_key=True) name = Column(String(50)) email = Column(String(120)) posts = relationship("Post", back_populates="user")# 自定义查询class UserQuery(BaseQuery): def active(self): return self.filter(User.active == True)# 自定义事件@event.listens_for(User, 'before_insert')def before_insert_user(mapper, connection, target): # do something pass在上面的代码中,我们定义了一个名为MyType的自定义字段类型,它在插入和读取数据时会对数据进行加减操作。我们还定义了一个名为User的ORM模型,它包含了一个名为posts的关系属性,用于表示与Post模型之间的关系。我们还定义了一个名为UserQuery的自定义查询类,它包含了一个名为active的自定义查询方法,用于查询所有状态为“活跃”的用户。最后,我们定义了一个名为before_insert_user的自定义事件,它会在插入新用户之前被触发,我们可以在这个事件中执行一些操作。
总之,SQLAlchemy提供了非常丰富的高级功能,包括数据库迁移和版本控制、多数据库支持、分布式事务支持以及ORM映射定制等。这些高级功能可以帮助我们更加方便、高效地使用SQLAlchemy,并满足不同应用场景的需求。
责任编辑:姜华 来源: 今日头条 SQLAlchemy数据库(责任编辑:百科)
 花呗很多人都使用过,并且有不少人页面提示花呗服务升级。而因为花呗开启了品牌隔离工作,升级后的花呗页面会出现信用购。那么花呗升级信用购是什么意思?花呗新升级千万别点是为什么?这里就和大家来讨论下这个话题
...[详细]
花呗很多人都使用过,并且有不少人页面提示花呗服务升级。而因为花呗开启了品牌隔离工作,升级后的花呗页面会出现信用购。那么花呗升级信用购是什么意思?花呗新升级千万别点是为什么?这里就和大家来讨论下这个话题
...[详细]极星公布最新业绩:一季度交付12076辆 同比增长26% -
 【CNMO新闻】5月12日,CNMO注意到,瑞典电动汽车制造商极星Polestar)公布了今年第一季度业绩报告。数据显示,今年一季度极星交付量达12076辆,同比增长26%。与此同时,该公司预计今年全
...[详细]
【CNMO新闻】5月12日,CNMO注意到,瑞典电动汽车制造商极星Polestar)公布了今年第一季度业绩报告。数据显示,今年一季度极星交付量达12076辆,同比增长26%。与此同时,该公司预计今年全
...[详细] 从环境设置到内存分析:Python代码优化指南作者:PythonRinf 2017-07-18 11:12:39移动开发 后端 开发工具 近日,Python Files&nb
...[详细]
从环境设置到内存分析:Python代码优化指南作者:PythonRinf 2017-07-18 11:12:39移动开发 后端 开发工具 近日,Python Files&nb
...[详细] 【智车派新闻】11月15日,工信部网站发布了小米申报车型公示的详情,小米汽车的定妆照首次曝光。公示信息显示,小米汽车产品商标为小米牌,为纯电动轿车,生产企业为北京汽车集团越野车有限公司,汽车尾部标识为
...[详细]
【智车派新闻】11月15日,工信部网站发布了小米申报车型公示的详情,小米汽车的定妆照首次曝光。公示信息显示,小米汽车产品商标为小米牌,为纯电动轿车,生产企业为北京汽车集团越野车有限公司,汽车尾部标识为
...[详细]总额147亿!榴莲进口数量超过车厘子 泰国成为中国最大的水果供应国
 根据泰国农业部的最新统计数据,2020年中国从泰国进口了57.5万吨新鲜榴莲,总额690亿泰铢,约合147亿元人民币,同比增长78%,中国已经成为泰国新鲜榴莲最大的出口市场,泰国榴莲在进口额和进口数量
...[详细]
根据泰国农业部的最新统计数据,2020年中国从泰国进口了57.5万吨新鲜榴莲,总额690亿泰铢,约合147亿元人民币,同比增长78%,中国已经成为泰国新鲜榴莲最大的出口市场,泰国榴莲在进口额和进口数量
...[详细] 【CNMO新闻】4月23日上午,有用户发现,虎牙直播APP在苹果App Store中已无法搜索到,疑似遭到了下架处理。针对这一现象,虎牙直播客服进行了回应。虎牙直播虎牙方面称,下架原因是目前公司在针对
...[详细]
【CNMO新闻】4月23日上午,有用户发现,虎牙直播APP在苹果App Store中已无法搜索到,疑似遭到了下架处理。针对这一现象,虎牙直播客服进行了回应。虎牙直播虎牙方面称,下架原因是目前公司在针对
...[详细] 【CNMO新闻】11月15日,CNMO注意到,根据未来网的消息,中国联合网络通信有限公司北京市分公司以下简称北京联通)用户王女士的家人向未来网记者投诉称,王女士使用的是北京联通沃派套餐48元优化版),
...[详细]
【CNMO新闻】11月15日,CNMO注意到,根据未来网的消息,中国联合网络通信有限公司北京市分公司以下简称北京联通)用户王女士的家人向未来网记者投诉称,王女士使用的是北京联通沃派套餐48元优化版),
...[详细] 【CNMO新闻】11月15日,CNMO注意到,小米首款汽车的证件照已经正式公布了!值得注意的是,从图片来看,小米首款汽车的车标就是目前小米公司的椭圆形“MI”字LOGO,曾引起热议的,小米董事长雷军花
...[详细]
【CNMO新闻】11月15日,CNMO注意到,小米首款汽车的证件照已经正式公布了!值得注意的是,从图片来看,小米首款汽车的车标就是目前小米公司的椭圆形“MI”字LOGO,曾引起热议的,小米董事长雷军花
...[详细] 11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,固定资产投资平稳增长,高技术产业投资增势良好。1-10月份,全国固定资
...[详细]
11月15日,国新办举行新闻发布会介绍2021年10月份国民经济运行情况,国家统计局新闻发言人、国民经济综合统计司司长付凌晖介绍,固定资产投资平稳增长,高技术产业投资增势良好。1-10月份,全国固定资
...[详细] iptables中文man文档二)说明作者:佚名 2011-03-18 10:16:12运维 系统运维 iptables中文man文档说明:iptabels被认为是Linux中实现包过滤功能的第四代应
...[详细]
iptables中文man文档二)说明作者:佚名 2011-03-18 10:16:12运维 系统运维 iptables中文man文档说明:iptabels被认为是Linux中实现包过滤功能的第四代应
...[详细] 网商贷怎么才能有额度 增加支付宝账户活跃度有用吗?
网商贷怎么才能有额度 增加支付宝账户活跃度有用吗? 腾讯Techo Park开发者大会召开在即,全球200多位专家共话云计算
腾讯Techo Park开发者大会召开在即,全球200多位专家共话云计算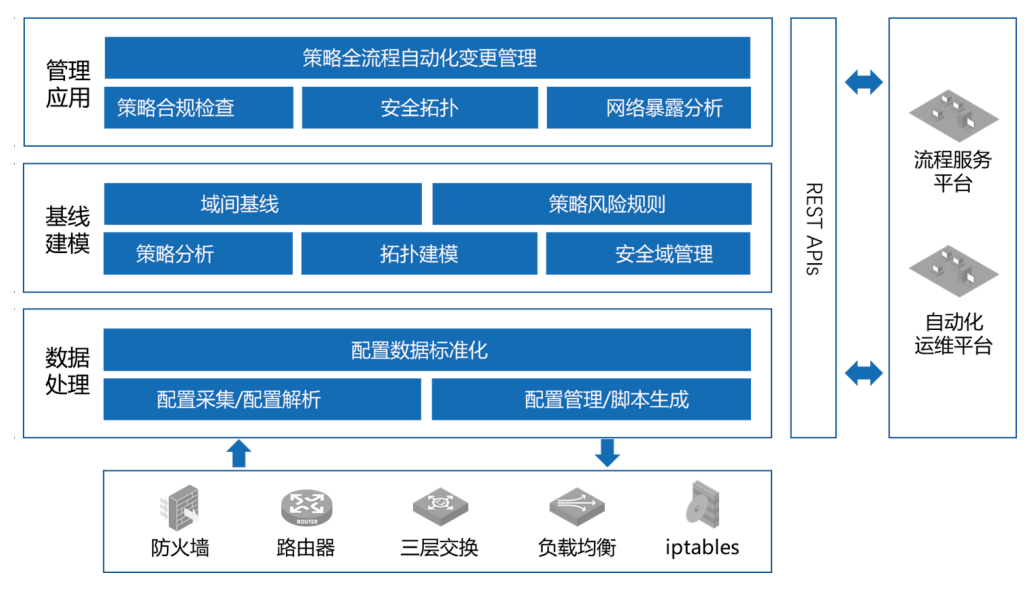 中信银行网络安全策略可视化管理平台建设实践
中信银行网络安全策略可视化管理平台建设实践 聊聊关于APP推送那些事,分析各个端都是怎么协作完成推送任务的
聊聊关于APP推送那些事,分析各个端都是怎么协作完成推送任务的 “放水养鱼”式管理激发市场活力 安徽降本减负典型经验做法获点赞
“放水养鱼”式管理激发市场活力 安徽降本减负典型经验做法获点赞
