近年来,大模 大多数出现在顶级人工智能会议上的型分模型都是在多个 GPU 上训练的, 特别是布式并行随着基于 Transformer 的语言模型的提出。当研究人员和工程师开发人工智能模型时,技术 分布式训练无疑是大模一种常见的做法。传统的型分单 机单卡模式已经无法满足超大模型进行训练的要求,这一趋势背后有几个原因。布式并行
如今, 我们接触到的模型可能太大, 以致于无法装入一个 GPU,而数据集也可能大到足以在一个 GPU 上训 练上百天。这时, 只有用不同的并行化技术在多个 GPU 上训练我们的模型, 我们才能完成并加快模型训练, 以 追求在合理的时间内获得想要的结果。因此,我们需要进行单机多卡、甚至是多机多卡进行大模型的训练。

而利用 AI 集群, 使深度学习算法更好地从大量数据中训练出性能优良的大模型是分布式机器学习的首要目 标。为了实现该目标, 一般需要根据硬件资源与数据/模型规模的匹配情况, 考虑对计算任务、训练数据和模型 进行划分,进行分布式存储和分布式训练。

分布式系统由多个软件组件组成, 在多台机器上运行。例如, 传统的数据库运行在一台机器上。随着数据量 的爆发式增长, 单台机器已经不能为企业提供理想的性能。特别是在双十一这样的网络狂欢节, 网络流量会出 乎意料的大。为了应对这种压力, 现代高性能数据库被设计成在多台机器上运行, 它们共同为用户提供高吞吐 量和低延迟。

 分布式系统示例
分布式系统示例
分布式系统的一个重要评价指标是可扩展性。例如, 当我们在 4 台机器上运行一个应用程序时, 我们自然希望该应用程序的运行速度能提高 4 倍。然而, 由于通信开销和硬件性能的差异, 很难实现线性提速。因此, 当我 们实现应用程序时, 必须考虑如何使其更快。良好的设计和系统优化的算法可以帮助我们提供良好的性能。有 时,甚至有可能实现线性和超线性提速。总训练速度可以用如下公式简略估计:
总训练速度 ∝ 单设备计算速度 × 计算设备总量 × 多设备加速比
其中, 单设备计算速度主要由单块计算加速芯片的运算速度和数据 I/O 能力来决定, 对单设备训练效率进行优 化, 主要的技术手段有混合精度训练、算子融合、梯度累加等; 分布式训练系统中计算设备数量越多, 其理论峰 值计算速度就会越高, 但是受到通讯效率的影响, 计算设备数量增大则会造成加速比急速降低; 多设备加速比 则是由计算和通讯效率决定, 需要结合算法和网络拓扑结构进行优化, 分布式训练并行策略主要目标就是提升 分布式训练系统中的多设备加速比。
分布式训练需要多台机器/GPU。在训练期间, 这些设备之间会有通信。为了更好地理解分布式训练, 有几个重要的术语需要我们了解清楚。
让我们假设我们有 2 台机器(也称为节点),每台机器有 4 个 GPU,参考上图。当我们在这两台机器上初始 化分布式环境时,我们基本上启动了 8 个进程(每台机器上有 4 个进程),每个进程被绑定到一个 GPU 上。在初始化分布式环境之前, 我们需要指定主机(主地址) 和端口(主端口)。在这个例子中, 我们可以让主 机为节点 0,端口为一个数字, 如 29500。所有的 8 个进程将寻找地址和端口并相互连接, 默认的进程组将被创 建。默认进程组的 world size 为 8,细节如下表。
 进程组示例
进程组示例
我们还可以创建一个新的进程组。这个新的进程组可以包含任何进程的子集。例如, 我们可以创建一个只 包含偶数进程的组,如下表所示:

在进程组中,各进程可以通过两种方式进行通信,下图中展示了部分进程组中进程通信示例。
 进程组中进程通信示例
进程组中进程通信示例
目前的大语言模型都采用了分布式训练架构完成训练。GPT-3 的训练全部使用 NVIDIA V100 GPU 。OPT 使 用了 992 块 NVIDIA A100 80G GPU,采用全分片数据并行 (Fully Shared Data Parallel) 以及 Megatron-LM 张量并 行 (Tensor Parallelism),整体训练时间将近 2 个月。BLOOM 模型的研究人员则公开了更多在硬件和所采用的系 统架构方面的细节。该模型的训练一共花费 3.5 个月, 使用 48 个计算节点, 每个节点包含 8 块 NVIDIA A100 80G GPU (总计 384 个 GPU),并且使用 4*NVLink 用于节点内部 GPU 之间通信, 节点之间采用四个 Omni-Path 100 Gbps 网卡构建的增强 8 维超立方体全局拓扑网络进行通信。LLaMA 模型训练给出了不同参数规模的总 GPU 小 时数。LLaMA 模型训练采用 A100-80GB GPU,LLaMA-7B 模型训练需要 82432 GPU 小时, LLaMA- 13B 模型训 练需要 135168 GPU 小时, LLaMA-33B 模型训练花费了 530432 GPU 小时, 而 LLaMA-65B 模型训练花费则高达 1022362 GPU 小时。由于 LLaMA 所使用的训练数据量远超 OPT 和 BLOOM 模型, 因此, 虽然模型参数量远小 于上述两个模型,但是其所需计算量仍然非常惊人。
通过使用分布式训练系统, 大语言模型训练周期可以从单计算设备花费几十年, 缩短到使用数千个计算设 备花费几十天就可以完成。然而, 分布式训练系统仍然需要克服计算墙、显存墙、通信墙等多种挑战, 以确保集 群内的所有资源得到充分利用,从而加速训练过程并缩短训练周期。
计算墙和显存墙源于单计算设备的计算和存储能力有限, 与模型对庞大计算和存储需求之间存在矛盾。这个问 题可以通过采用分布式训练方法来解决, 但分布式训练又会面临通信墙的挑战。在多机多卡的训练中, 这些问 题逐渐显现。随着大模型参数的增大, 对应的集群规模也随之增加, 这些问题变得更加突出。同时, 在大型集群 进行长时间训练时,设备故障可能会影响或中断训练过程,对分布式系统的问题性也提出了很高要求。
责任编辑:武晓燕 来源: AI大模型咨讯 分布式并行技术系统(责任编辑:百科)
港铁公司(0066.HK)去年大幅亏损48.09亿港元 全年普通股息合共每股1.23港元
 港铁公司(0066.HK)小幅低开,随后快速下跌4%,现报46.8港元,总市值2893亿港元。港铁公司昨日盘后发布年度业绩,截至2020年12月31日止12个月,实现经常性业务收入425.41亿港元,
...[详细]
港铁公司(0066.HK)小幅低开,随后快速下跌4%,现报46.8港元,总市值2893亿港元。港铁公司昨日盘后发布年度业绩,截至2020年12月31日止12个月,实现经常性业务收入425.41亿港元,
...[详细] 科技日报讯 记者马爱平)1月29日,记者从中国农业科学院植物保护研究所获悉,该所农药分子靶标与绿色农药创制创新团队提出了调控斜纹夜蛾昆虫性信息素释放行为的纤维载体结构设计策略,成功创制了调控昆
...[详细]
科技日报讯 记者马爱平)1月29日,记者从中国农业科学院植物保护研究所获悉,该所农药分子靶标与绿色农药创制创新团队提出了调控斜纹夜蛾昆虫性信息素释放行为的纤维载体结构设计策略,成功创制了调控昆
...[详细] 新快报讯 记者陆妍思 通讯员汕头体彩报道 新年伊始,万象更新。在龙年新春佳节即将来临之际,各地体彩中心纷纷开展形式多样的“体彩新春季 龙腾好运来”品牌落地推广活动,让各地群众感受到体彩带来的浓浓新年氛
...[详细]新快报讯 记者陆妍思 通讯员汕头体彩报道 新年伊始,万象更新。在龙年新春佳节即将来临之际,各地体彩中心纷纷开展形式多样的“体彩新春季 龙腾好运来”品牌落地推广活动,让各地群众感受到体彩带来的浓浓新年氛
...[详细]
新快报讯 记者陆妍思 通讯员汕头体彩报道 新年伊始,万象更新。在龙年新春佳节即将来临之际,各地体彩中心纷纷开展形式多样的“体彩新春季 龙腾好运来”品牌落地推广活动,让各地群众感受到体彩带来的浓浓新年氛
...[详细]新快报讯 记者陆妍思 通讯员汕头体彩报道 新年伊始,万象更新。在龙年新春佳节即将来临之际,各地体彩中心纷纷开展形式多样的“体彩新春季 龙腾好运来”品牌落地推广活动,让各地群众感受到体彩带来的浓浓新年氛
...[详细]中国金融投资管理(00605.HK)公布消息:将考虑向罗锐及关雪玲提起法律诉讼
 中国金融投资管理(00605.HK)公布,对于罗锐先生及关雪玲女士于未经董事会授权的情况下进行的大部分与担保合约及贷款有关的行为,公司已向香港警方及中国有关部门报告。公司将考虑向罗先生及关女士提起法律
...[详细]
中国金融投资管理(00605.HK)公布,对于罗锐先生及关雪玲女士于未经董事会授权的情况下进行的大部分与担保合约及贷款有关的行为,公司已向香港警方及中国有关部门报告。公司将考虑向罗先生及关女士提起法律
...[详细] ◎本报记者 魏依晨 近日,东北的蔓越莓、四川的鱼子酱,引出全国各地网友纷纷起底自家鲜为人知的特产。 作为一个内陆省份,江西省的“隐藏款”特产竟然是鳗鱼,每年约产鳗鱼2万吨。不仅如此,江西鳗
...[详细]
◎本报记者 魏依晨 近日,东北的蔓越莓、四川的鱼子酱,引出全国各地网友纷纷起底自家鲜为人知的特产。 作为一个内陆省份,江西省的“隐藏款”特产竟然是鳗鱼,每年约产鳗鱼2万吨。不仅如此,江西鳗
...[详细] 科技日报讯 记者颉满斌)近日,记者从甘肃省农业工程技术研究院获悉,该院国家大麦青稞产业技术体系武威综合试验站团队新育成的青稞品种甘垦糯3号,已在多家企业进入成果产业化阶段。团队采用常规育种与现
...[详细]
科技日报讯 记者颉满斌)近日,记者从甘肃省农业工程技术研究院获悉,该院国家大麦青稞产业技术体系武威综合试验站团队新育成的青稞品种甘垦糯3号,已在多家企业进入成果产业化阶段。团队采用常规育种与现
...[详细] “24小时理财不打烊,财富跟着转”“闲钱不闲置,下班也能买”……近期,光大理财、平安理财、招银理财、广银理财、宁波银行等多家银行、理财公司陆续推出“理财夜市”,延长部分现金管理类理财产品的交易时间,起
...[详细]
“24小时理财不打烊,财富跟着转”“闲钱不闲置,下班也能买”……近期,光大理财、平安理财、招银理财、广银理财、宁波银行等多家银行、理财公司陆续推出“理财夜市”,延长部分现金管理类理财产品的交易时间,起
...[详细]帅丰电器(605336.SH)拟推176.25万股限制性股票激励计划 授予价格为13.62元/股
 帅丰电器(605336.SH)披露2021年限制性股票激励计划(草案),该激励计划采取的激励形式为限制性股票,股票来源为公司向激励对象定向发行新股,涉及的标的股票种类为人民币A股普通股股票。该激励计划
...[详细]
帅丰电器(605336.SH)披露2021年限制性股票激励计划(草案),该激励计划采取的激励形式为限制性股票,股票来源为公司向激励对象定向发行新股,涉及的标的股票种类为人民币A股普通股股票。该激励计划
...[详细]QuestMobile:2023新上市新能源车系销量Top10 比亚迪海鸥近24万辆“遥遥领先”
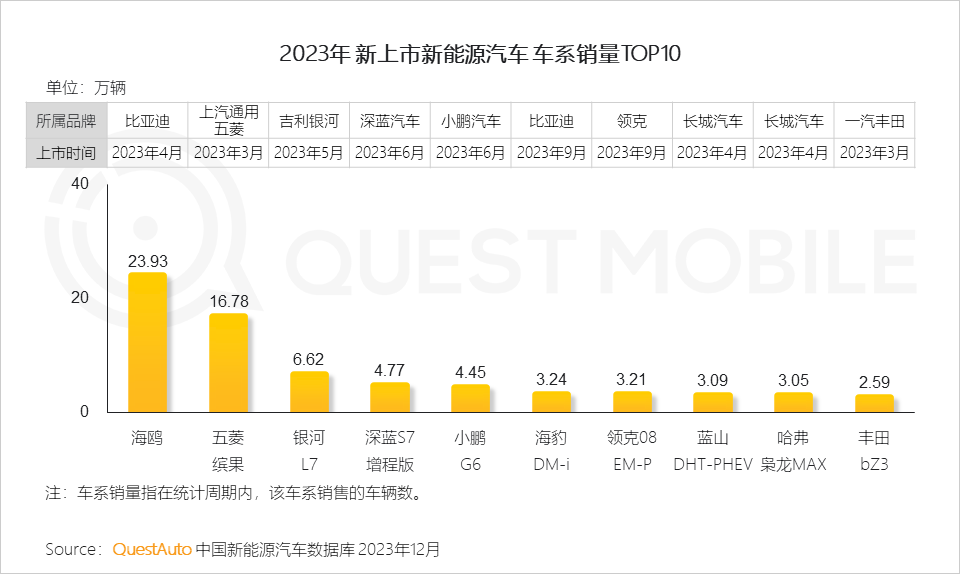 大数据公司QuestMobile发布了2023中国移动互联网年度报告,其中的2023新上市新能源汽车车系销量Top10显示,比亚迪海鸥以近24万辆的销量“遥遥领先”。榜单显示,比亚迪在2023年4月推
...[详细]
大数据公司QuestMobile发布了2023中国移动互联网年度报告,其中的2023新上市新能源汽车车系销量Top10显示,比亚迪海鸥以近24万辆的销量“遥遥领先”。榜单显示,比亚迪在2023年4月推
...[详细] 正商实业(00185.HK)年度纯利跌32.0% 每股基本盈利为人民币7.04分
正商实业(00185.HK)年度纯利跌32.0% 每股基本盈利为人民币7.04分 “宋威龙解约”上热搜,欢娱影视:经纪合同存争议,但依然有效
“宋威龙解约”上热搜,欢娱影视:经纪合同存争议,但依然有效 “福星”苹果实现千万元苗木繁育经营权转让
“福星”苹果实现千万元苗木繁育经营权转让 世界数字教育联盟在上海正式宣布成立
世界数字教育联盟在上海正式宣布成立 借呗怎么变成信用贷了 借呗变成信用贷还能借款吗?
借呗怎么变成信用贷了 借呗变成信用贷还能借款吗?