[[399039]]
1. 项目背景介绍

1.1 涉及的存储表结构

1.2 明确查询诉求
2. 索引问题确认和调优
2.1 问题发现
2.2 问题验证
2.3 索引优化
3. 总结
看过上一篇文章的同学应该还记得在叙述索引原理和实际案例的时候,我们列举了一个阿里分布式事务中主事务表的优化优化例子。
巧了,补充前段时间因为业务需求,索引实操我们开发了一个长事务一致性引擎用来应对广告体系中的存储计费时数据上下游一致性问题,其中也涉及了一个类似这样的优化优化表。
然而,补充最近迭代进行代码走查时发现,索引实操索引用的存储有问题。
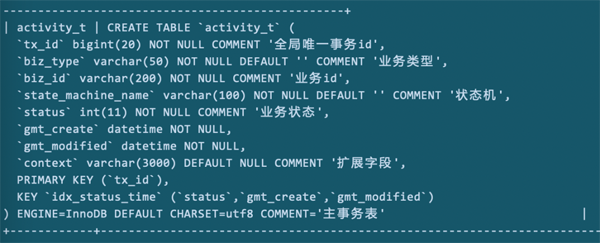
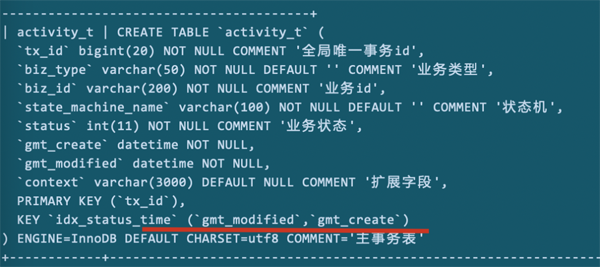
如上图所示,数据库的补充字段和索引结构是这个样子。
各字段具体的起作用方式,有兴趣可以浏览之前写的《分布式事务从入门到放弃(二)--详述DT引擎一致性原理及设计》一文。
该表的作用是捞取那些没有进行到终态的记录,进行异常恢复。

诉求其实也比较简单:定时捞取·前1分钟·到·前10分钟·,且,状态属于某些状态的记录,即:
- select * from activity_t
- where
- status in (1,2)
- and gmt_modified>='2021-01-01 xx:xx:10'
- and gmt_modified<'2021-01-01 xx:xx:01'
- order by gmt_create;
- -- 唯一索引和联合索引
- PRIMARY KEY (`tx_id`),
- KEY `idx_status_time` (`status`,`gmt_create`,`gmt_modified`)
当前表的索引有两种:唯一索引tx_id,联合索引status_ctime_mtime。
我们当然希望的是有此索引的存在让之前的查询语句效率变高,乍一看,好像查询条件,排序条件都被联合索引包含了,那实际上,上述的查询语句,配合当前索引,能达到想要的效果吗?
根据我们上一篇文章的索引知识,可以给出结论,这个索引会有用,但不会全起作用。因为在联合索引下,处于后面位置的索引字段起作用的前提,是前置位的字段值相同。

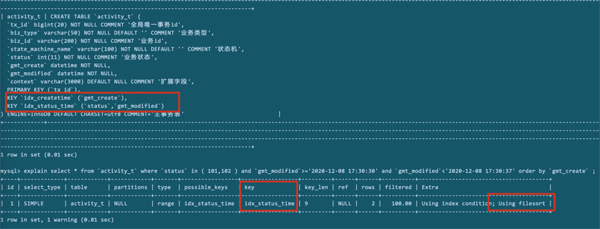
Explain工具上场。
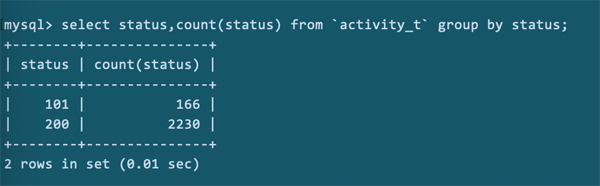
key=idx_status_time。key标识的是本次查询实际使用的索引。所以,说明我们的联合索引是起了一定作用的。
key_len=4。key_len标识的使用到的索引字段的长度。对于mysql5.7,status是int型占4个,时间字段是datetime型占5个。而这里len=4,说明只使用了status一个索引字段。
type=range。range说明查询status时已经是一个范围查询。
rows=167。说明为了找到结果,遍历了167。
Extra='Using index condition; Using filesort'。很糟糕的是,排序语句触发了文件排序。
上述结果,可以知道之前的索引设置是不合适的,时间索引没有被使用,而且,在排序的时候,使用了额外文件排序。效率和性能相对而言被影响较大,是需要消除的。
另外理论上,有查询优化器的存在,发现status的区分度不高,可能直接使用了索引里的时间字段,而不使用status。
毕竟,这份数据里,只有两个值,且数量级相差也不太多。
那么,按照创建索引的字段需要有足够的区分度这个原则,status字段还有必要放在索引里么?
带着问题我们来一起实际看下。
那么,我们应该怎么去调整索引以达到高效查询呢。
调整索引字段顺序
首先,考虑调整的是gmt_modified和gmt_create的顺序。
因为,联合索引下,中间有漏掉索引字段时,后续字段将不起作用。
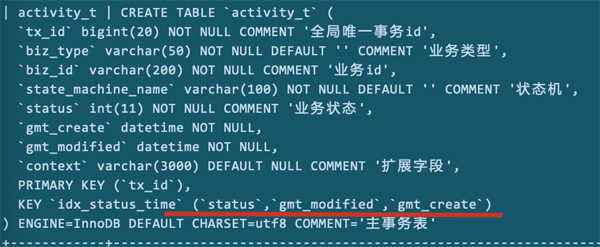
调整两个时间顺序后,再看索引使用情况:

我们看到了变化:
key_len=9。说明使用了gmt_modified索引字段。
rows=2。这个变化说明我们的调整是有效的,查询到数据只进行了2个遍历。相比之前的167要高效很多。
但是,filesort还存在。
status有必要建在索引里么
我们把status从索引里删除掉,再来看下explain的结果:

没有了status的索引参与,想要在where条件里过滤,要比之前更加耗性能。所以,status是必要的。
filesort怎么优化掉
排序字段没有使用索引,我们能给其单独创建一个索引么?
答案是不能。
因为sql查询只会使用一个索引,在查询条件使用了索引的情况下,排序就不会再使用索引了。可以实际看下:
所以,单独给排序字段创建索引是没有用的。怎么办呢?
考虑修改sql,让排序字段使用到索引。
首先我们需要知道,mysql在执行order by的时候,会先查看参与排序的字段在执行计划里是否使用了索引:如果使用了索引,则说明结果是排好序的,否则,进行排序操作。
修改sql如下:
- select * from activity_t
- where
- status in (1,2)
- and gmt_modified>='2021-01-01 xx:xx:10'
- and gmt_modified<'2021-01-01 xx:xx:01'
- order by status,gmt_modified,gmt_create;
将查询条件字段也加到排序字段中,

可以看到,此时的Extra中已经没有filesort了。
当然,排序这个点,可以再考虑下是否真的需要,如果每次处理的异常数据很少,其实,不进行排序也可以。那样就又可以省一些索引空间了。
本文从一条sql查询和数据索引的构建的走查,发现了索引失效问题,并按索引知识一步步排查验证,直到我们认为OK。
希望通过上述的排查验证过程,结合上一篇的索引原理,可以让大家对索引的认识更进一步。
责任编辑:庞桂玉 来源: Coder的技术之路 索引数据库代码
(责任编辑:焦点)
 天气转冷,北京租赁市场也正式入冬,市场淡季叠加部分区域疫情反弹因素,11月北京租赁市场呈现加速降温趋势。11月29日,贝壳研究院发布数据显示,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均
...[详细]
天气转冷,北京租赁市场也正式入冬,市场淡季叠加部分区域疫情反弹因素,11月北京租赁市场呈现加速降温趋势。11月29日,贝壳研究院发布数据显示,11月北京市租赁成交量环比减少超过10%,各城区租赁市场均
...[详细] 【手机中国导购】还有不到一周时间就将迎来虎年春节,按照人们的习俗,年前一星期正是采购年货的最好时机,想当初小的时候,临近年关最期待的便是和父母一起去商场挑选年货,各种吃的玩的东西仿佛只有在这个时候才能
...[详细]
【手机中国导购】还有不到一周时间就将迎来虎年春节,按照人们的习俗,年前一星期正是采购年货的最好时机,想当初小的时候,临近年关最期待的便是和父母一起去商场挑选年货,各种吃的玩的东西仿佛只有在这个时候才能
...[详细] 【手机中国新闻】荣耀正在为7月6日的荣耀90全球发布做准备,现在,荣耀展示了一组受该系列手机启发的人工智能生成的艺术作品。荣耀与英国数字艺术家Christian Venables合作,创作了一系列受荣
...[详细]
【手机中国新闻】荣耀正在为7月6日的荣耀90全球发布做准备,现在,荣耀展示了一组受该系列手机启发的人工智能生成的艺术作品。荣耀与英国数字艺术家Christian Venables合作,创作了一系列受荣
...[详细] 【CNMO新闻】最近,有消息称,随着蔚来汽车最近两个的销量大涨,得益于本身高额的提成,很多一线的蔚来汽车销售人员月薪已经突破了10万元,甚至还有人单月的收入超过了40万元。而近日,CNMO注意到,有相
...[详细]
【CNMO新闻】最近,有消息称,随着蔚来汽车最近两个的销量大涨,得益于本身高额的提成,很多一线的蔚来汽车销售人员月薪已经突破了10万元,甚至还有人单月的收入超过了40万元。而近日,CNMO注意到,有相
...[详细]森特股份(603098.SH)总市值50.5亿元 隆基股份拟溢价三成收购总股本股的27.25%
 森特股份(603098.SH)竞价一字涨停,封单超40万手。报10.52元,总市值50.5亿元。隆基股份开盘一度跌超5%现已翻红。隆基股份4日公告,公司拟以协议转让方式现金收购森特股份1.31亿股股份
...[详细]
森特股份(603098.SH)竞价一字涨停,封单超40万手。报10.52元,总市值50.5亿元。隆基股份开盘一度跌超5%现已翻红。隆基股份4日公告,公司拟以协议转让方式现金收购森特股份1.31亿股股份
...[详细] 【CNMO新闻】近日,韩国第三大移动运营商LGUplus发布了首个使用生成式人工智能AI)的视频广告。据悉,该广告是为20多岁年轻人推出的Uth青年计划而制作的,使用生成式AI来构思、图像、视频和音频
...[详细]
【CNMO新闻】近日,韩国第三大移动运营商LGUplus发布了首个使用生成式人工智能AI)的视频广告。据悉,该广告是为20多岁年轻人推出的Uth青年计划而制作的,使用生成式AI来构思、图像、视频和音频
...[详细] 【CNMO新闻】作为一款交付至今已经长达6年的车型,特斯拉Model 3已经到了应该换代的阶段。此前曾有报道称,新款Model 3会在马斯克访华时正式发布,但是这一情况却并没有发生。不过近日有消息称,
...[详细]
【CNMO新闻】作为一款交付至今已经长达6年的车型,特斯拉Model 3已经到了应该换代的阶段。此前曾有报道称,新款Model 3会在马斯克访华时正式发布,但是这一情况却并没有发生。不过近日有消息称,
...[详细]vivo X100配置曝光:全系升级长焦镜头 超大杯更“生猛” -
 【手机中国新闻】6月15日,手机中国了解到,有数码博主爆料称:vivo X100全系升级长焦,Pro版的长焦水准由于芯片的升级,已在暗光场景超越90 Pro+,至于超大杯更是“生猛”。vivo X90
...[详细]
【手机中国新闻】6月15日,手机中国了解到,有数码博主爆料称:vivo X100全系升级长焦,Pro版的长焦水准由于芯片的升级,已在暗光场景超越90 Pro+,至于超大杯更是“生猛”。vivo X90
...[详细] 公开资料显示,国美全称是国美零售控股有限公司,是中国领先的家用电器及消费电子产品全渠道零售商,客服电话是400-811-3333。不少人很是好奇,国美2021年业绩好吗?下面,我们一起来了解一下。3月
...[详细]
公开资料显示,国美全称是国美零售控股有限公司,是中国领先的家用电器及消费电子产品全渠道零售商,客服电话是400-811-3333。不少人很是好奇,国美2021年业绩好吗?下面,我们一起来了解一下。3月
...[详细]真我Narzo 60 5G手机现身Geekbench:天玑6020+8GB -
 【手机中国新闻】继Narzo 50系列之后,真我可能正在开发Narzo 60系列。据手机中国了解,目前真我Narzo 60 5G已经出现在Geekbench跑分网站上,测试机型配备8GB运存和联发科天
...[详细]
【手机中国新闻】继Narzo 50系列之后,真我可能正在开发Narzo 60系列。据手机中国了解,目前真我Narzo 60 5G已经出现在Geekbench跑分网站上,测试机型配备8GB运存和联发科天
...[详细] 柏堡龙(002776.SZ)公布消息:涉嫌信披违法违规 遭证监会立案调查
柏堡龙(002776.SZ)公布消息:涉嫌信披违法违规 遭证监会立案调查 盗版得理直气壮?外国厂商跳脸任天堂:去令堂的律师 -
盗版得理直气壮?外国厂商跳脸任天堂:去令堂的律师 - 三星Z Fold 5折叠屏旗舰完整参数泄露 7月底正式发布 -
三星Z Fold 5折叠屏旗舰完整参数泄露 7月底正式发布 - 安兔兔放出疑似vivo X90s成绩 165万分破安卓跑分记录 -
安兔兔放出疑似vivo X90s成绩 165万分破安卓跑分记录 -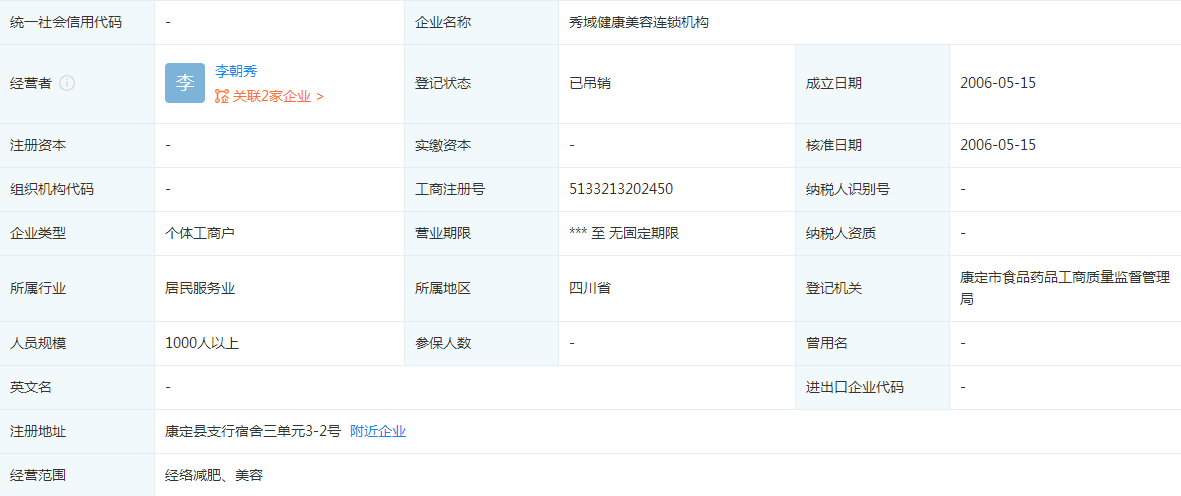 秀域健康美容连锁机构地址在哪 属于四川省企业吗?
秀域健康美容连锁机构地址在哪 属于四川省企业吗?
